这也是一篇长文。
Build a Large Scale Cloud Native CI/CD System Based on Tekton
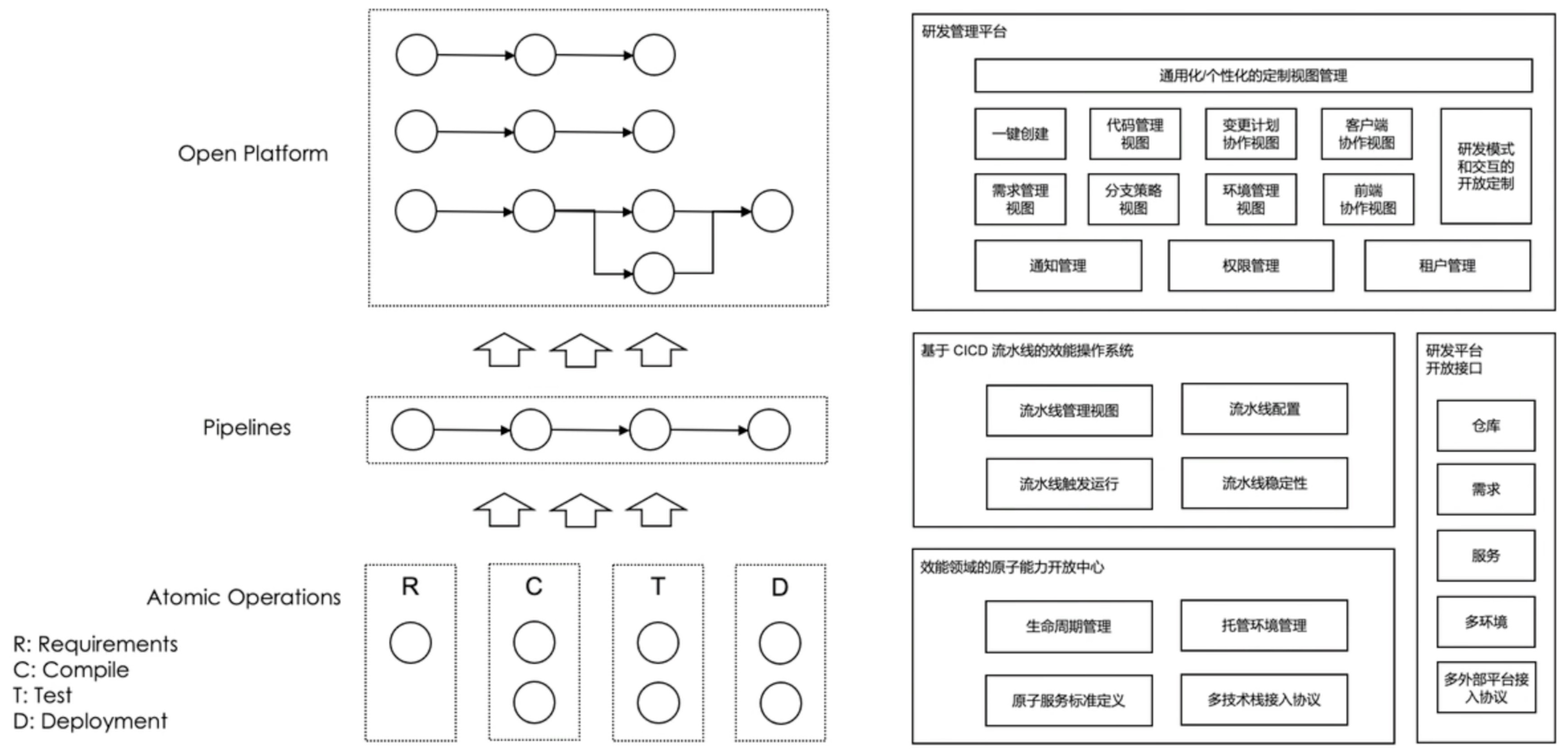
原子能力非常优秀了。
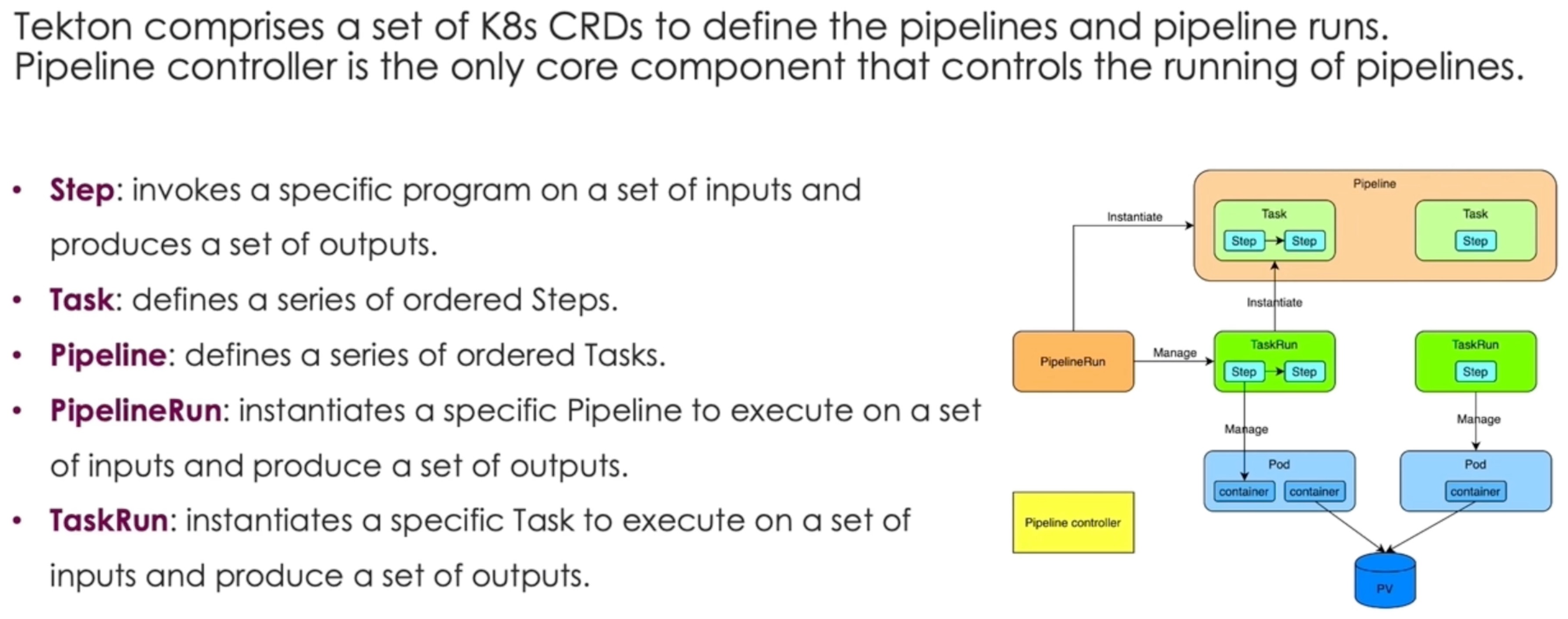
基于 Tekton 做扩展。

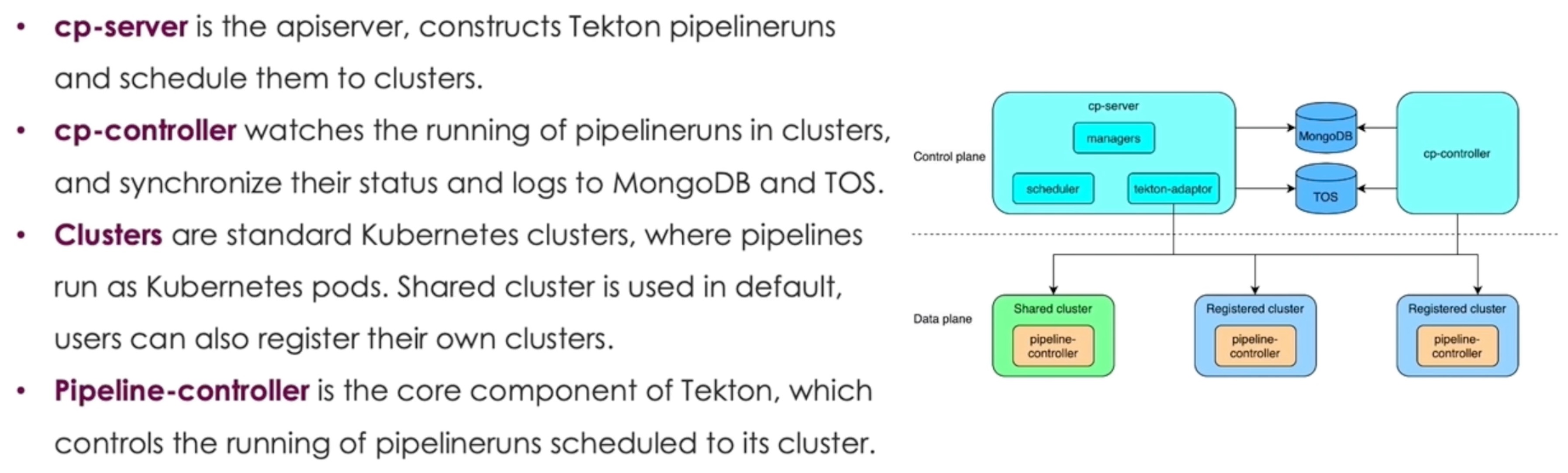
cp-controller 支持了 sharding。

解决 Etcd 性能问题的方案就是不用 Etcd,改用 database。
Improve FUSE Filesystem Performance and Reliability
这个 Session 也很硬核。
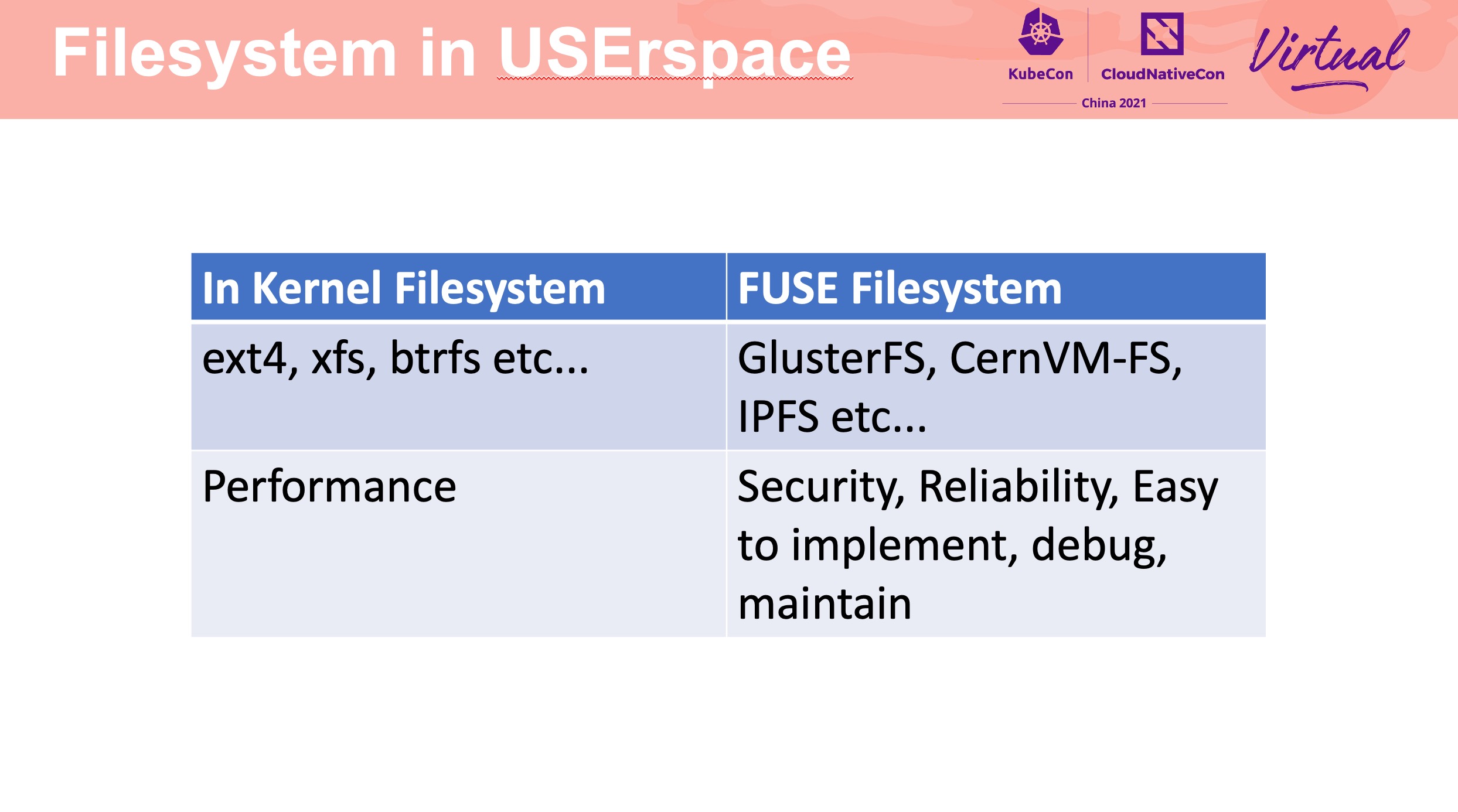
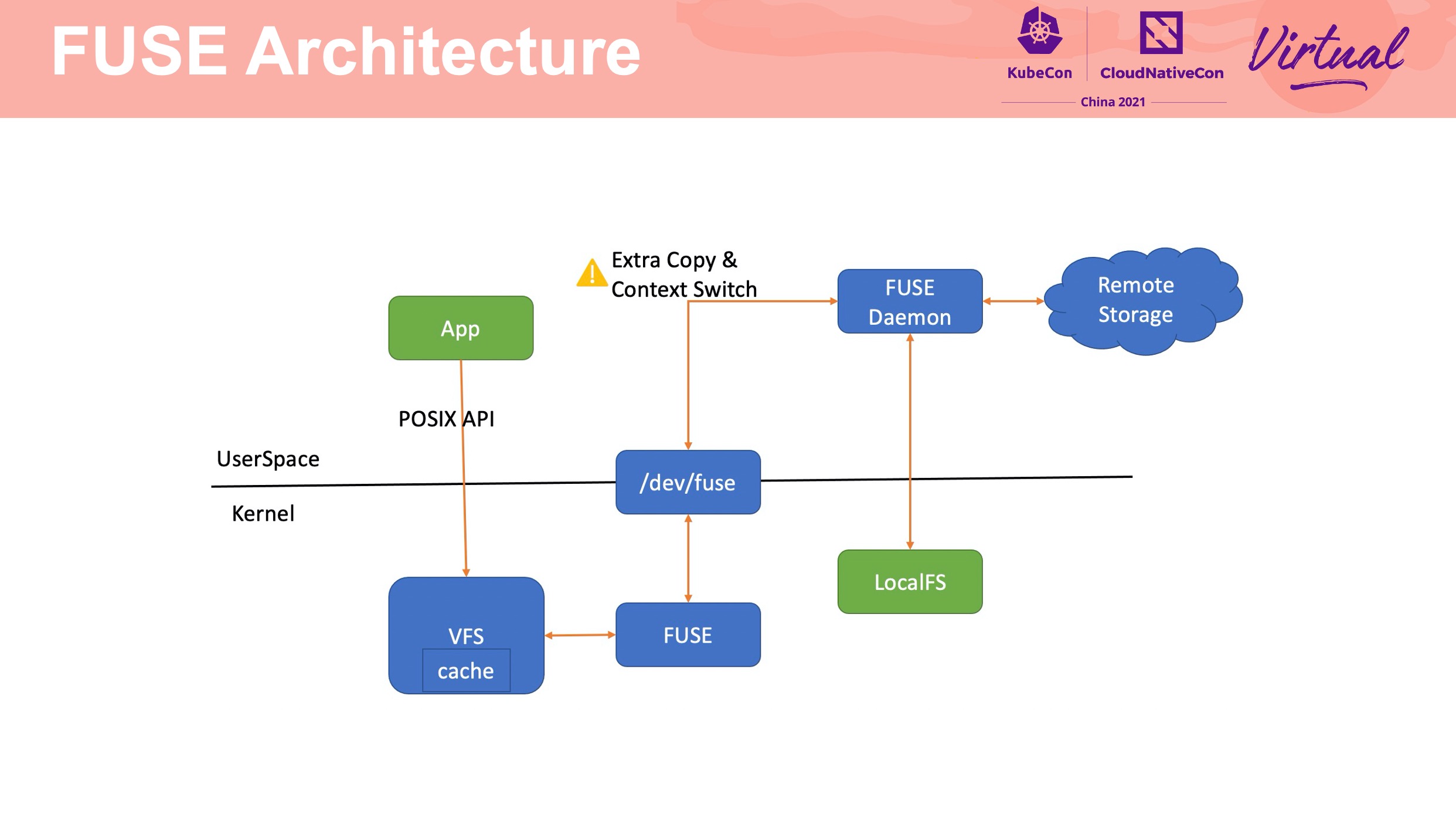
FUSE device driver 会有额外的数据拷贝和上下文切换,是造成性能损耗的关键因素。
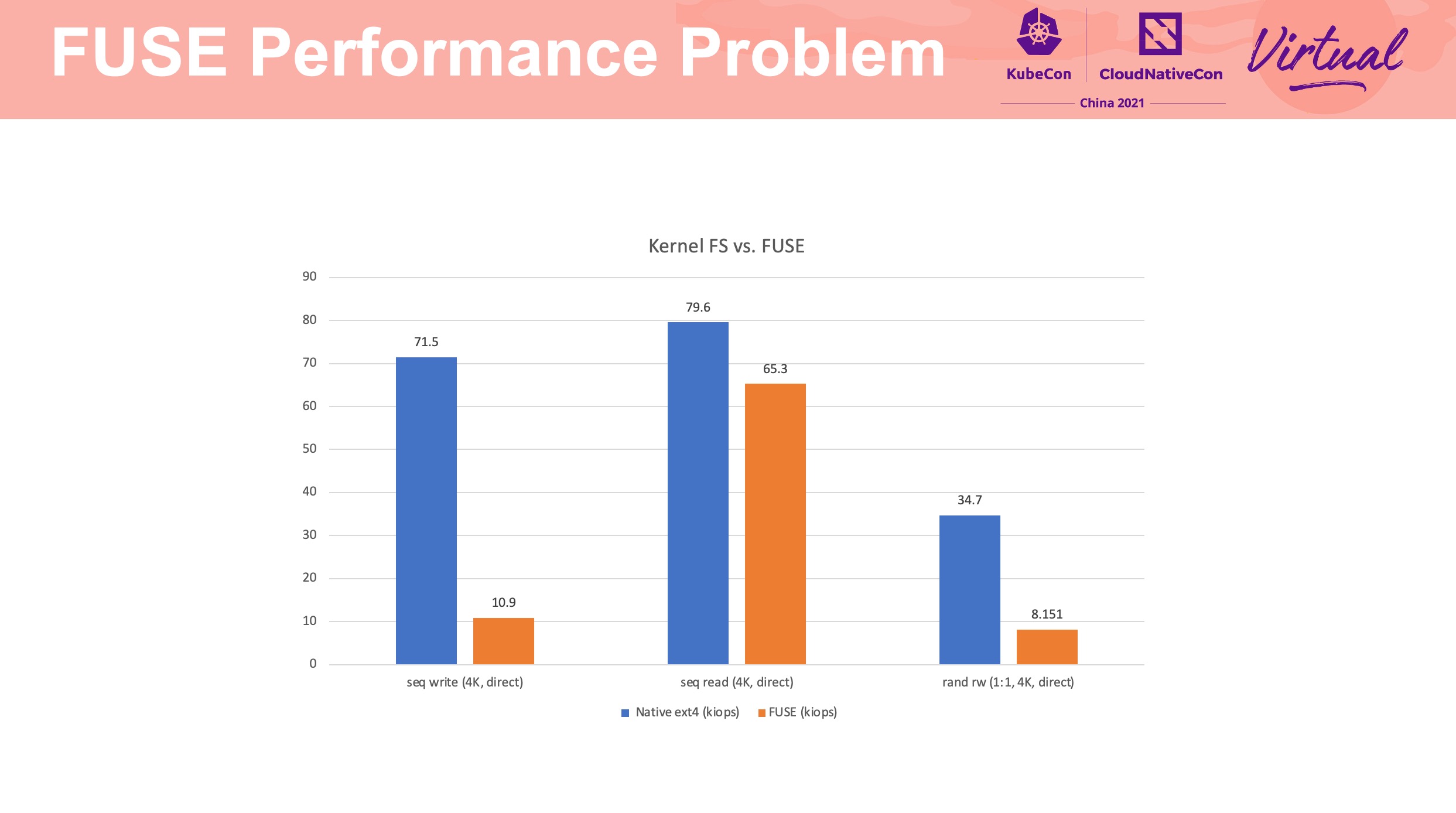



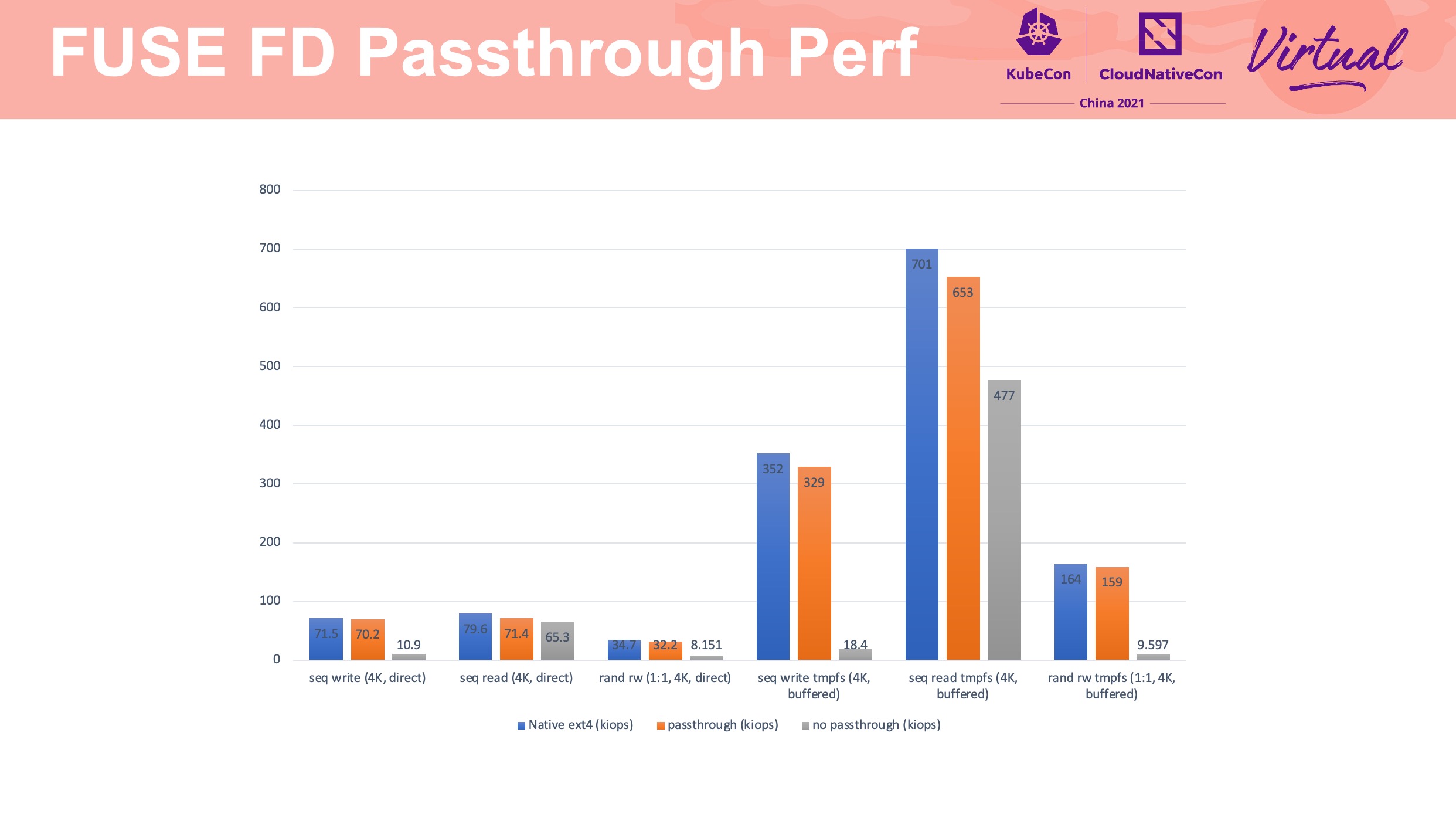
FUSE FD Passthrough 这块参考 PPT 中的链接一起看会好一点: https://lwn.net/Articles/843093/

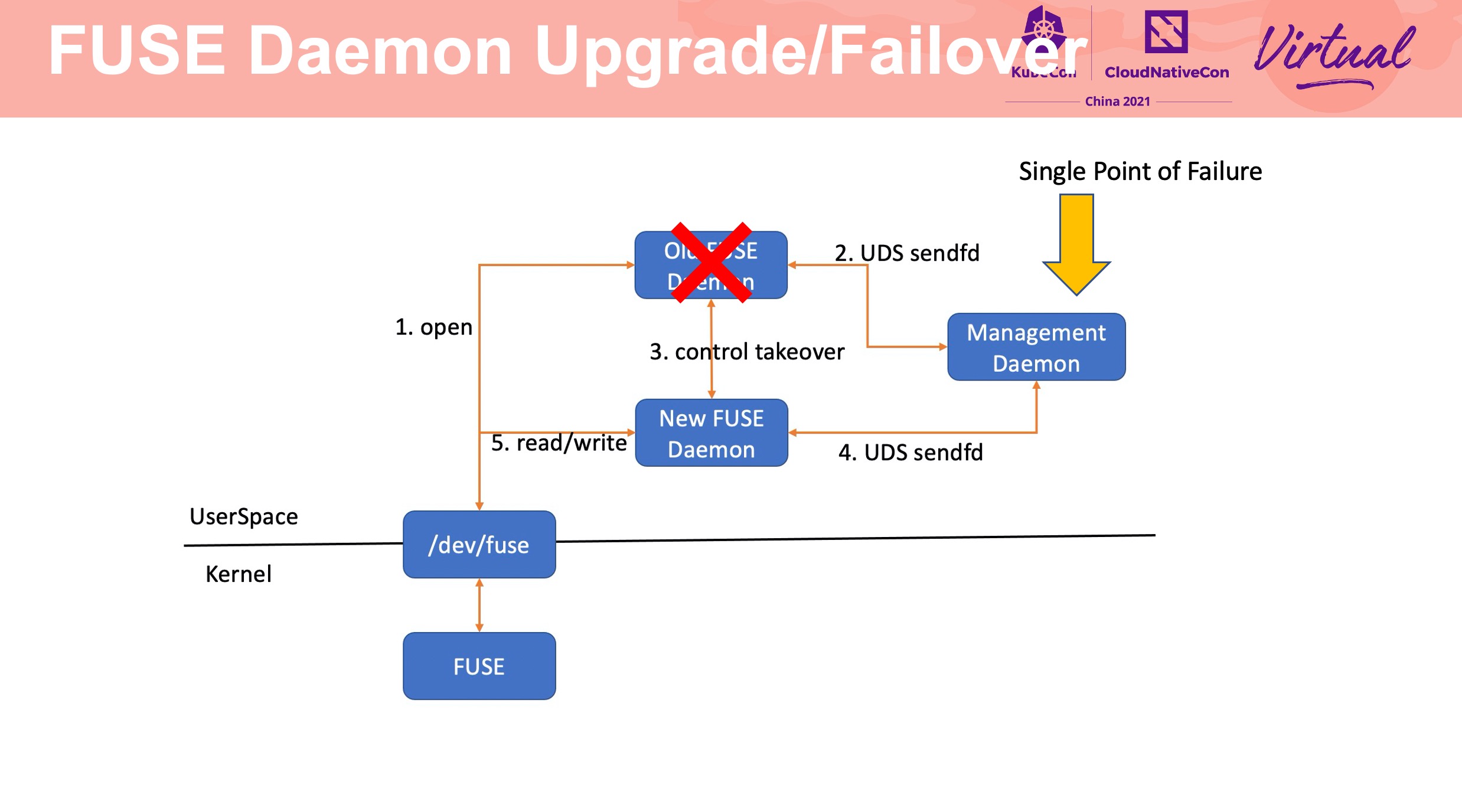

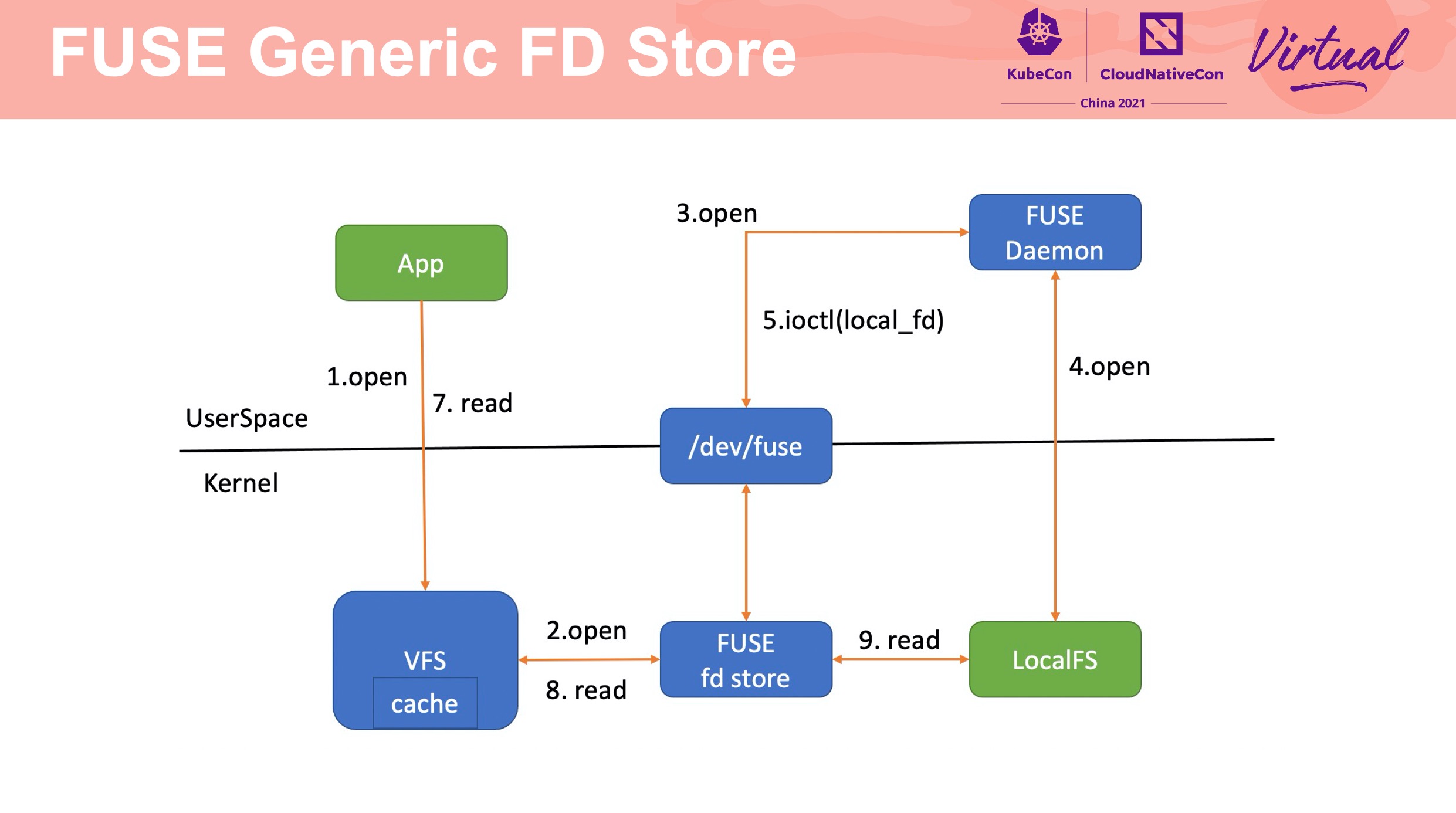
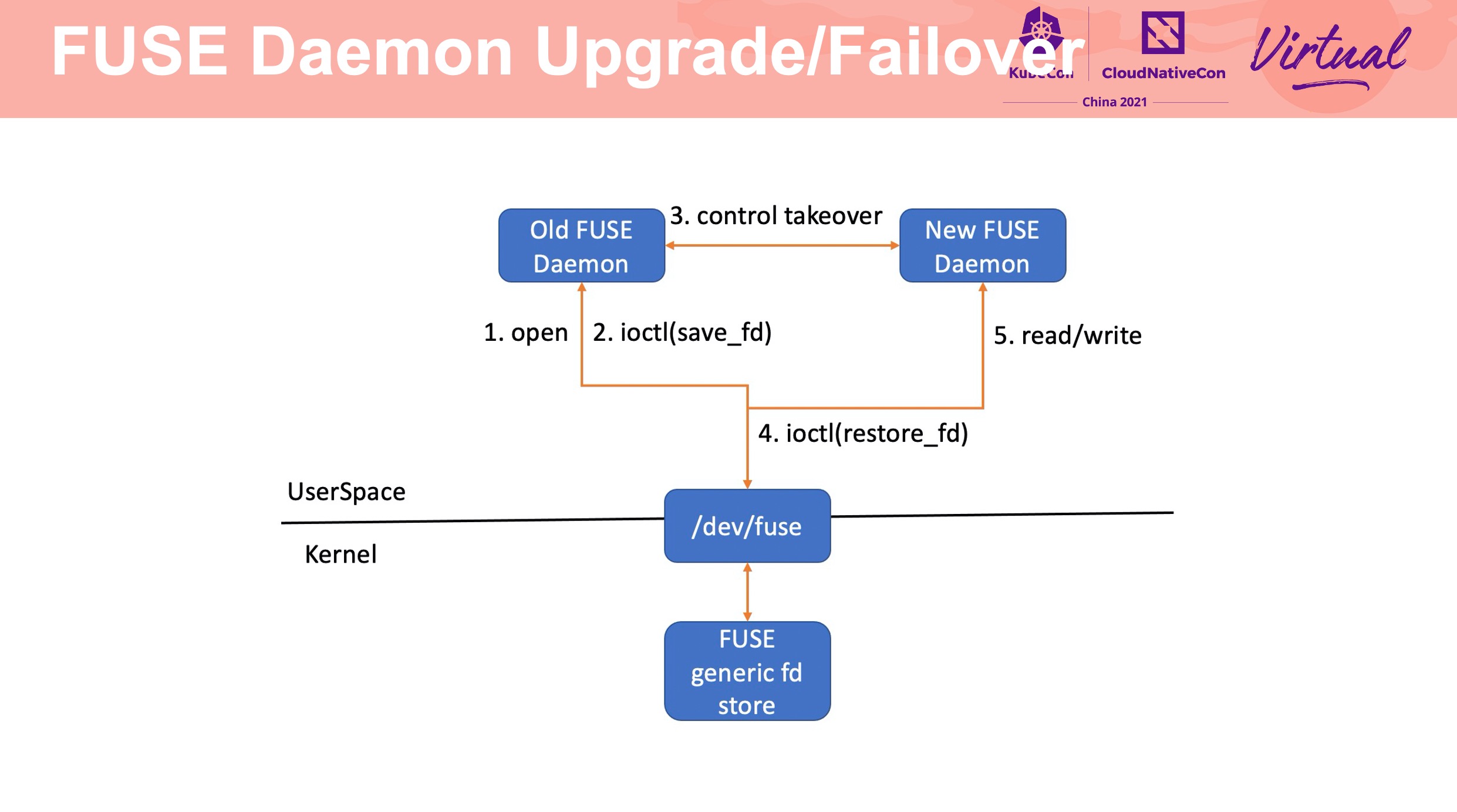
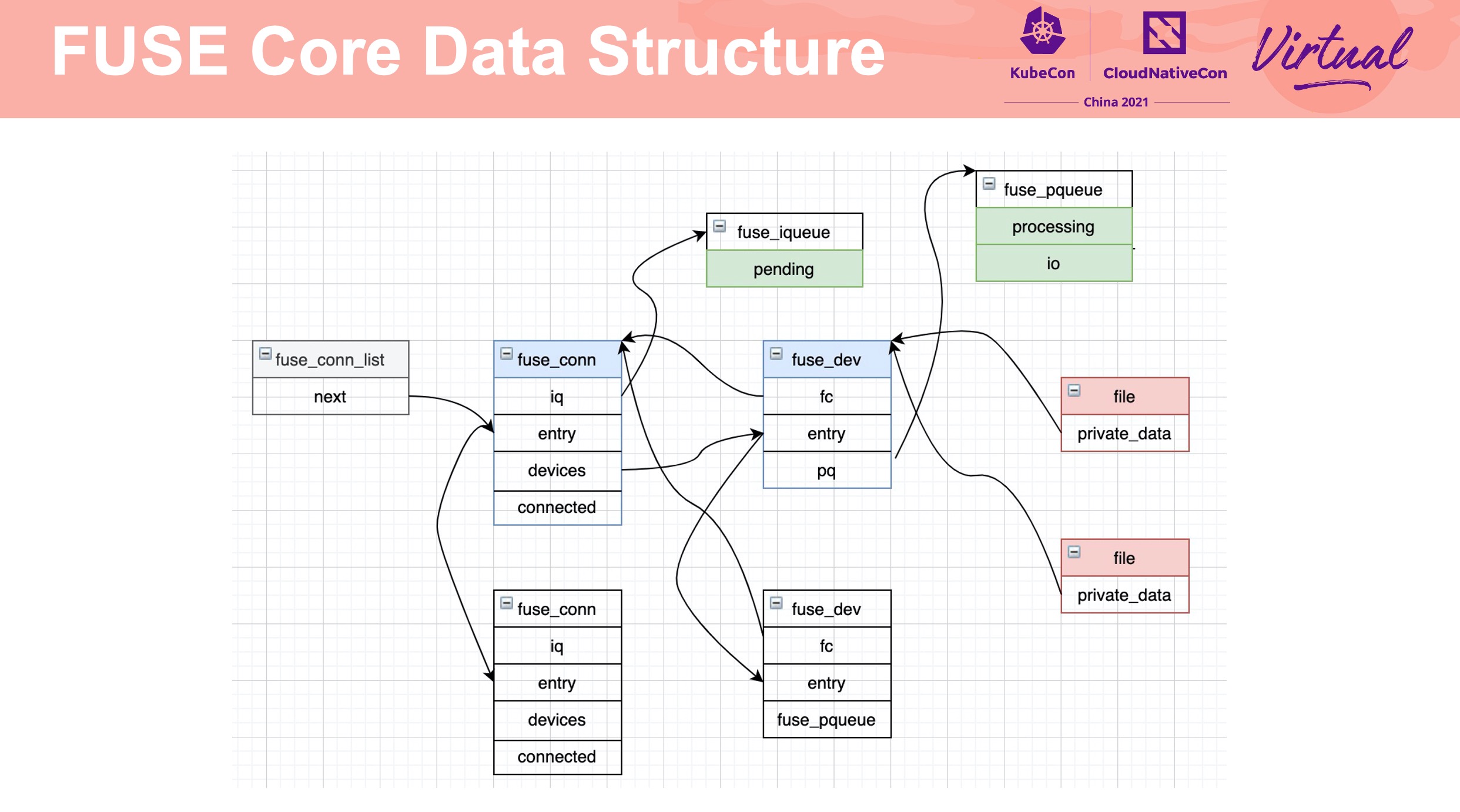

通过 fuse_conn、fuse_dev 实现 failover。
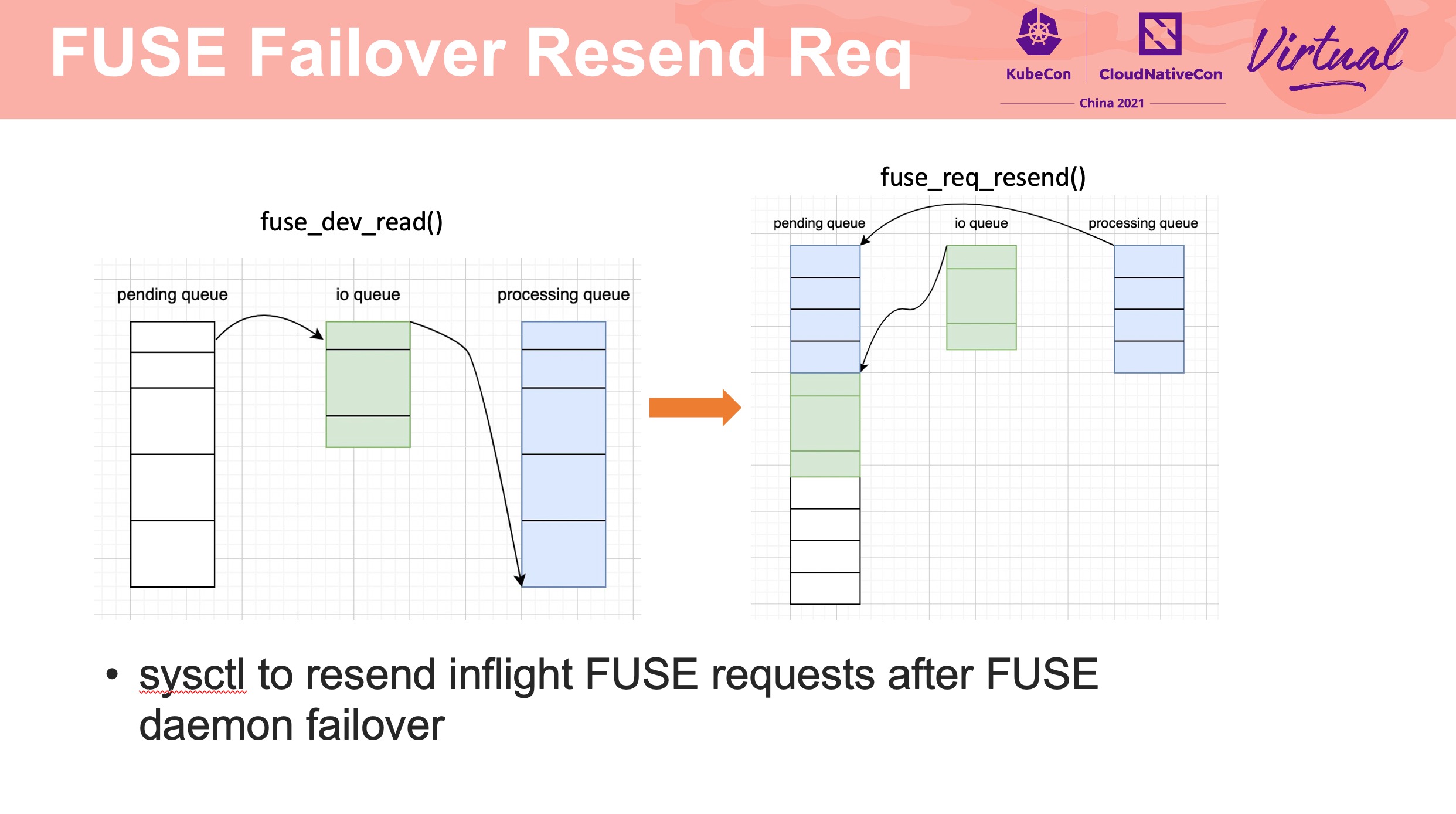

通过 requeue 操作防止在 failover 是 FUSE server panic 造成正在操作的文件发生异常。
Chaos Mesh 2.0 Make Chaos Engineering Easy
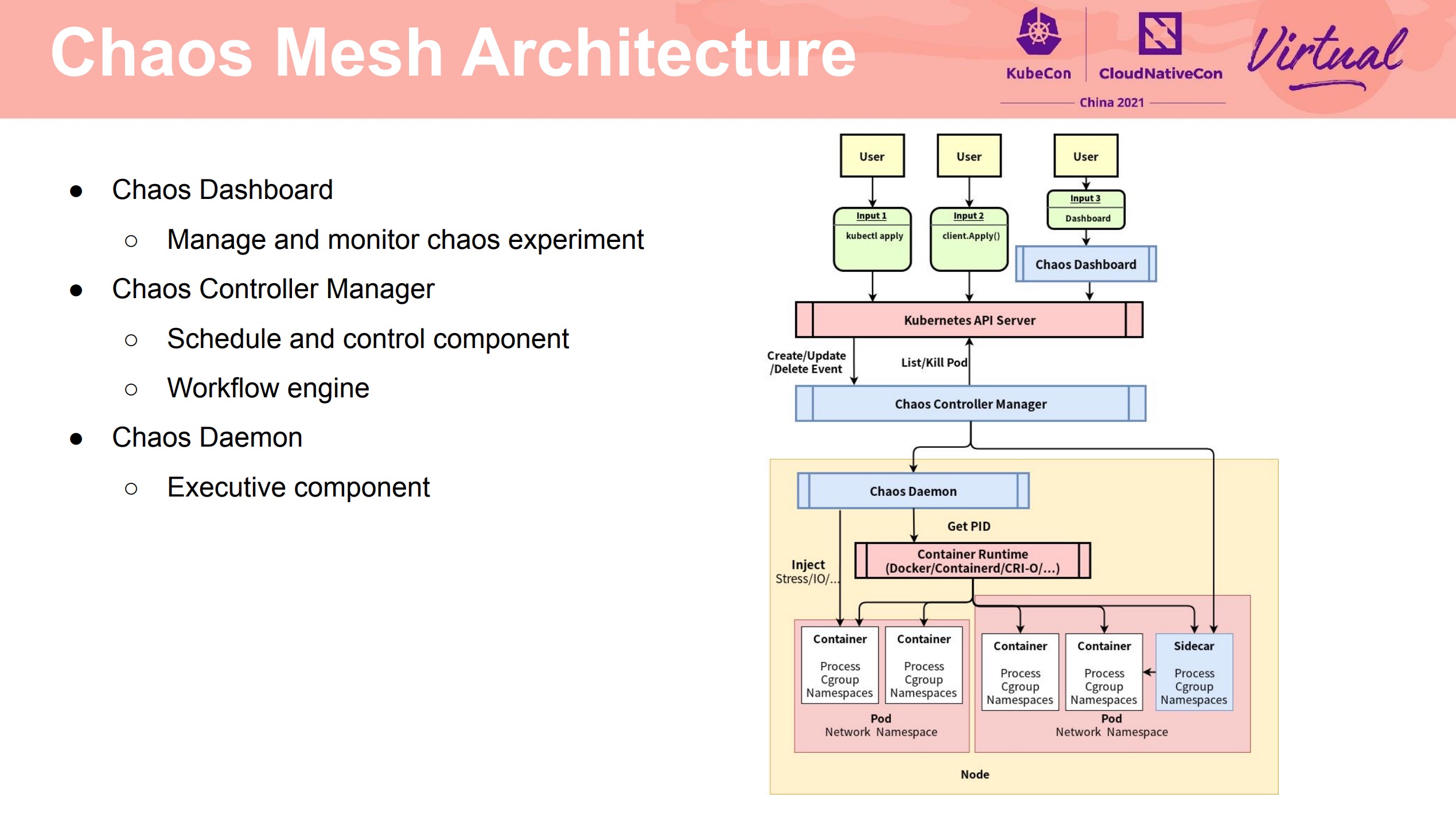
终于有 Workflow 了。

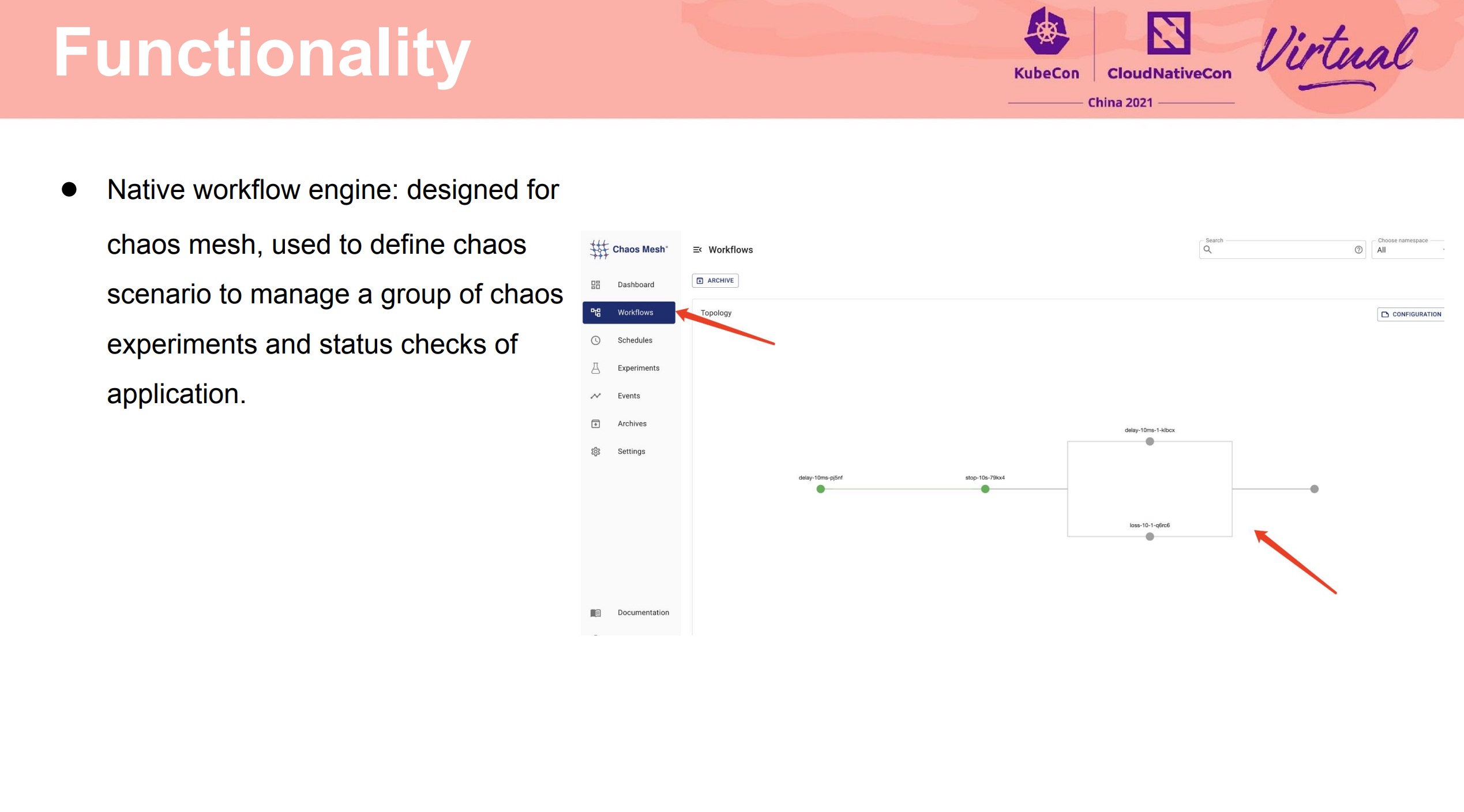
那么,问题来了,刚执行了主机关机的 Chaos 实验,如何开机呢?

Run wasm applications on kubernetes edge cluster
K3s + Krustlet,有点非主流啊。
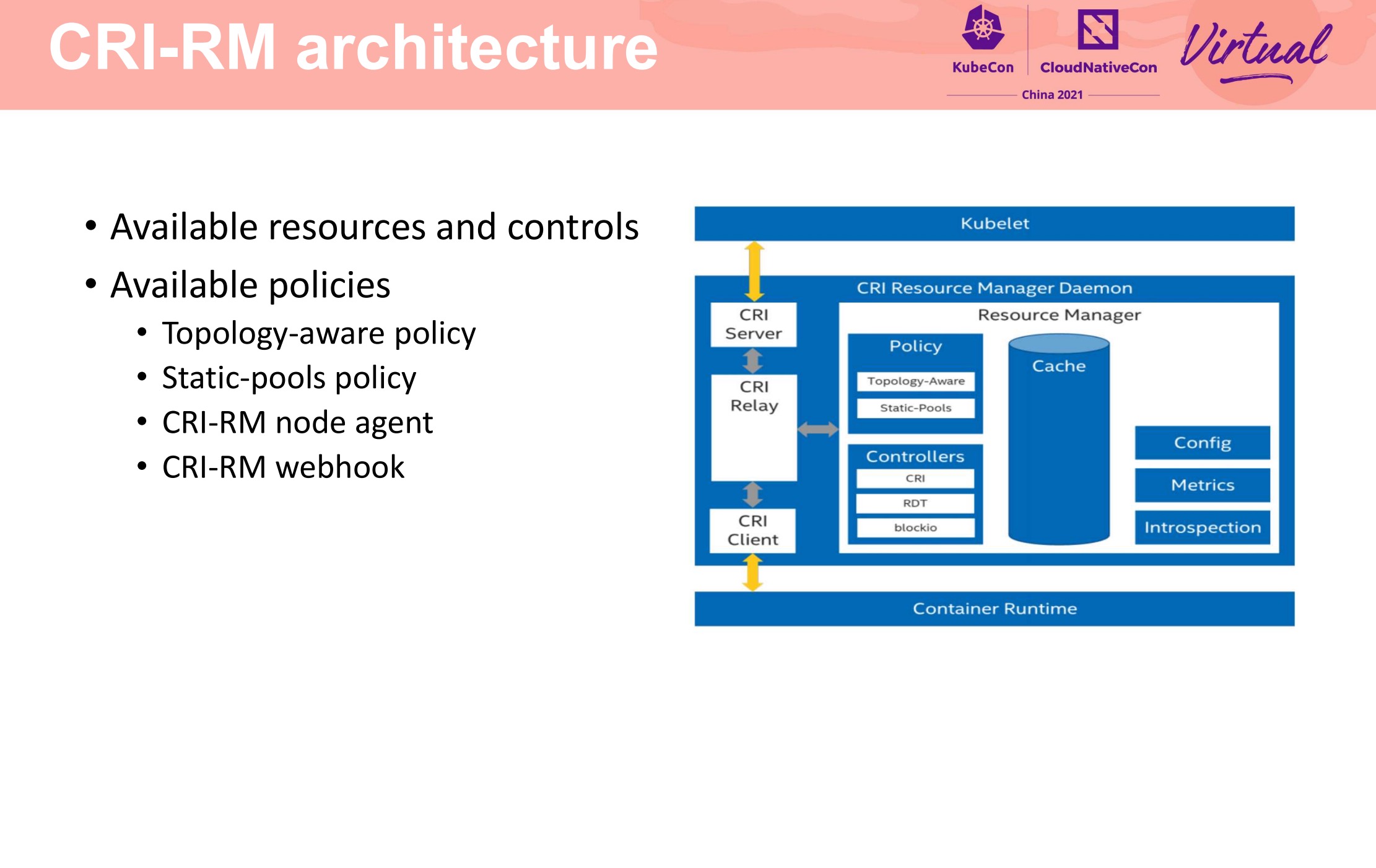
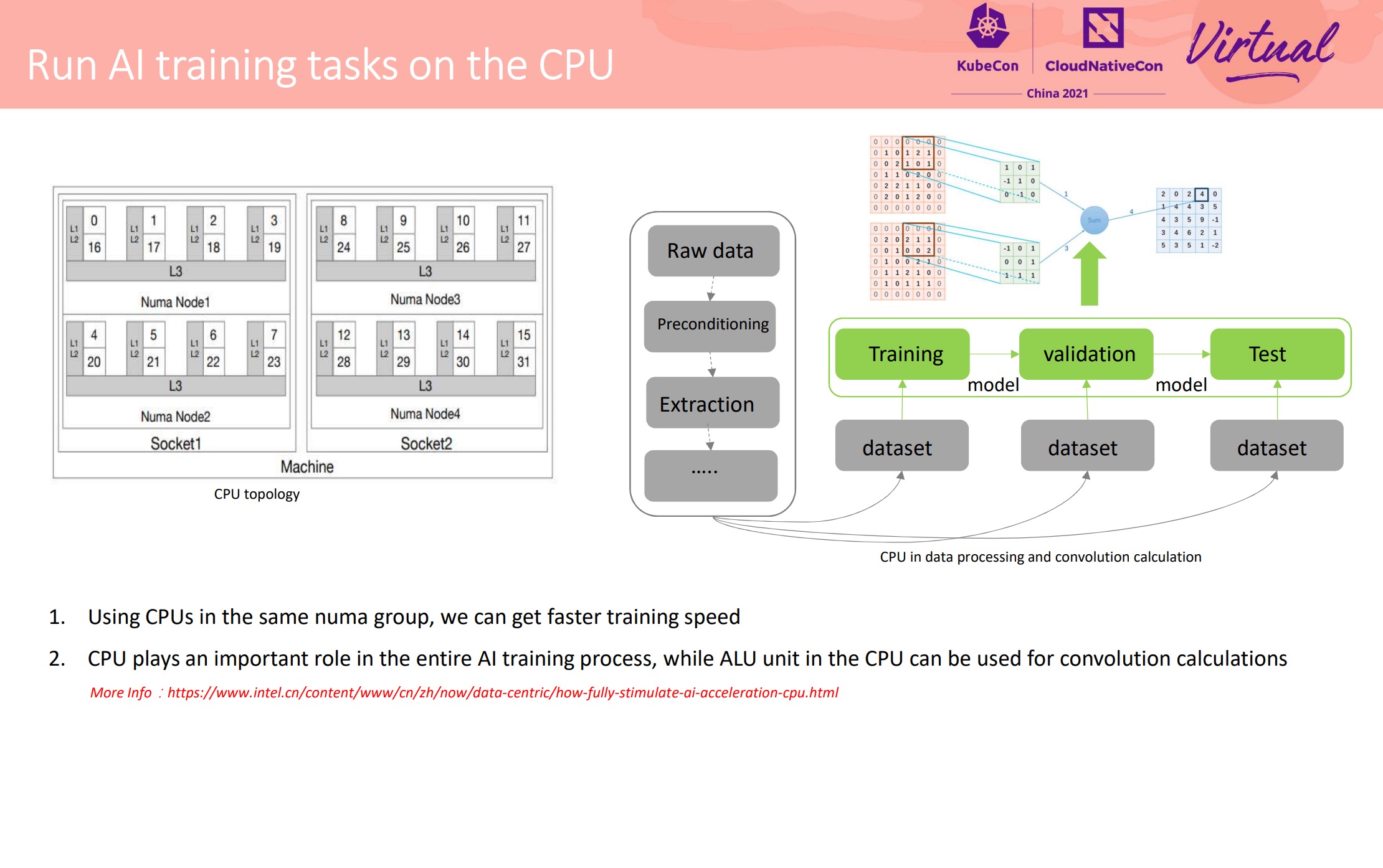
Deep Dive CRI-RM-based CPU and NUMA Affinity to Achieve AI Task Acceleration
不得不说 Intel 这个东西设计的可以的。 上篇还说 Kubelet 应该出个插件机制来解决这种问题,Intel 就换另一个思路解决了。

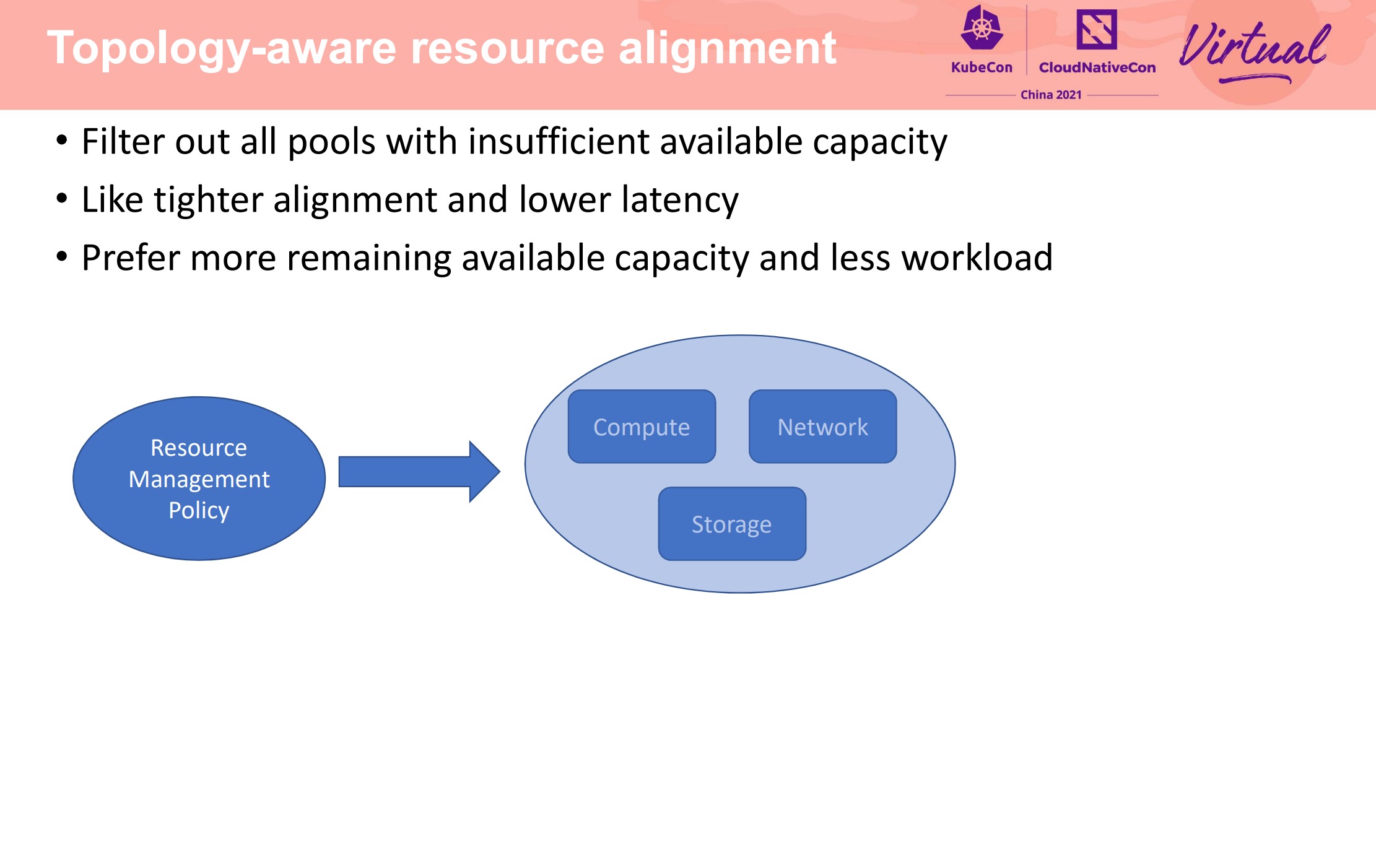
“吵闹的邻居”经典问题。


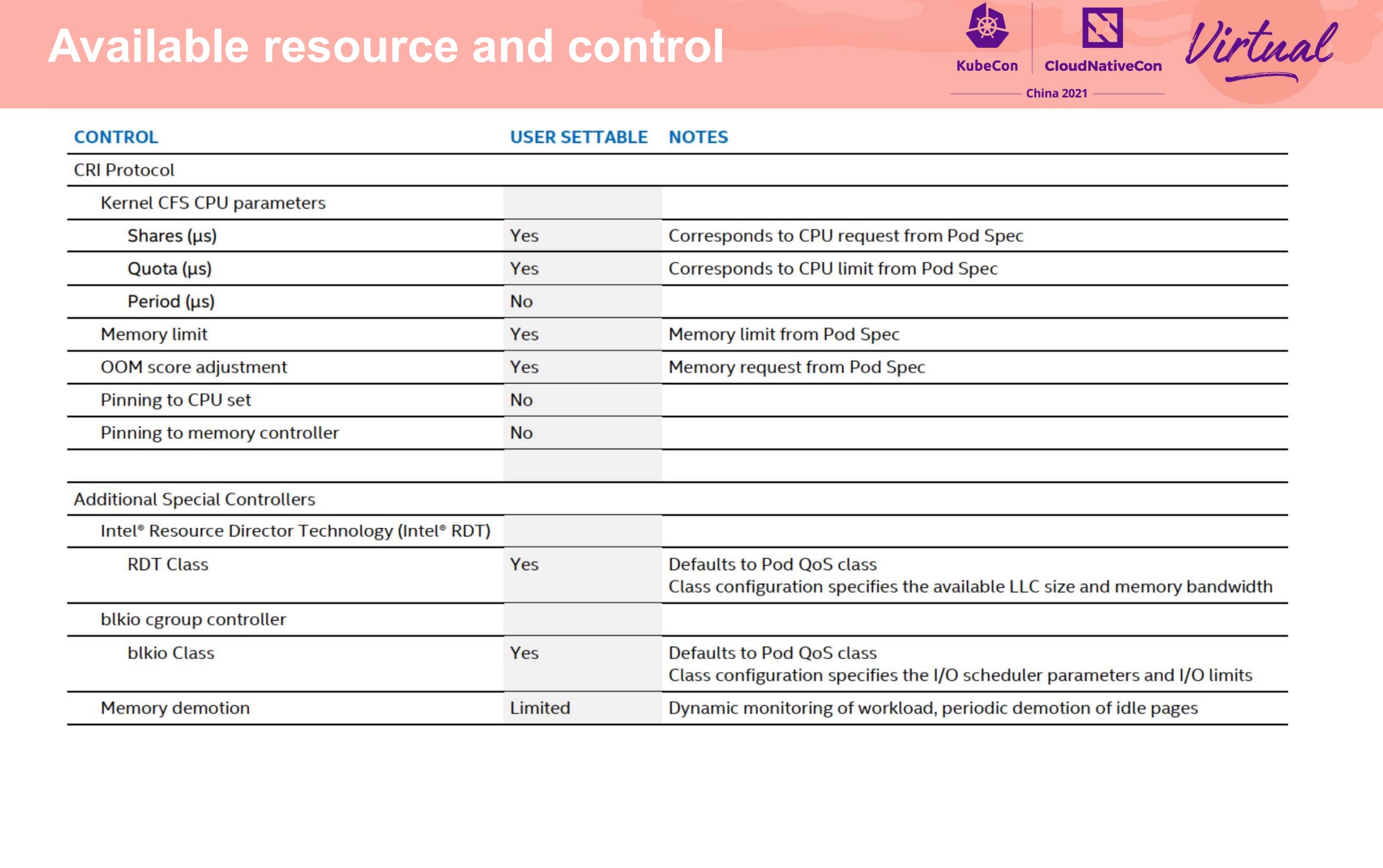
还支持了傲腾。

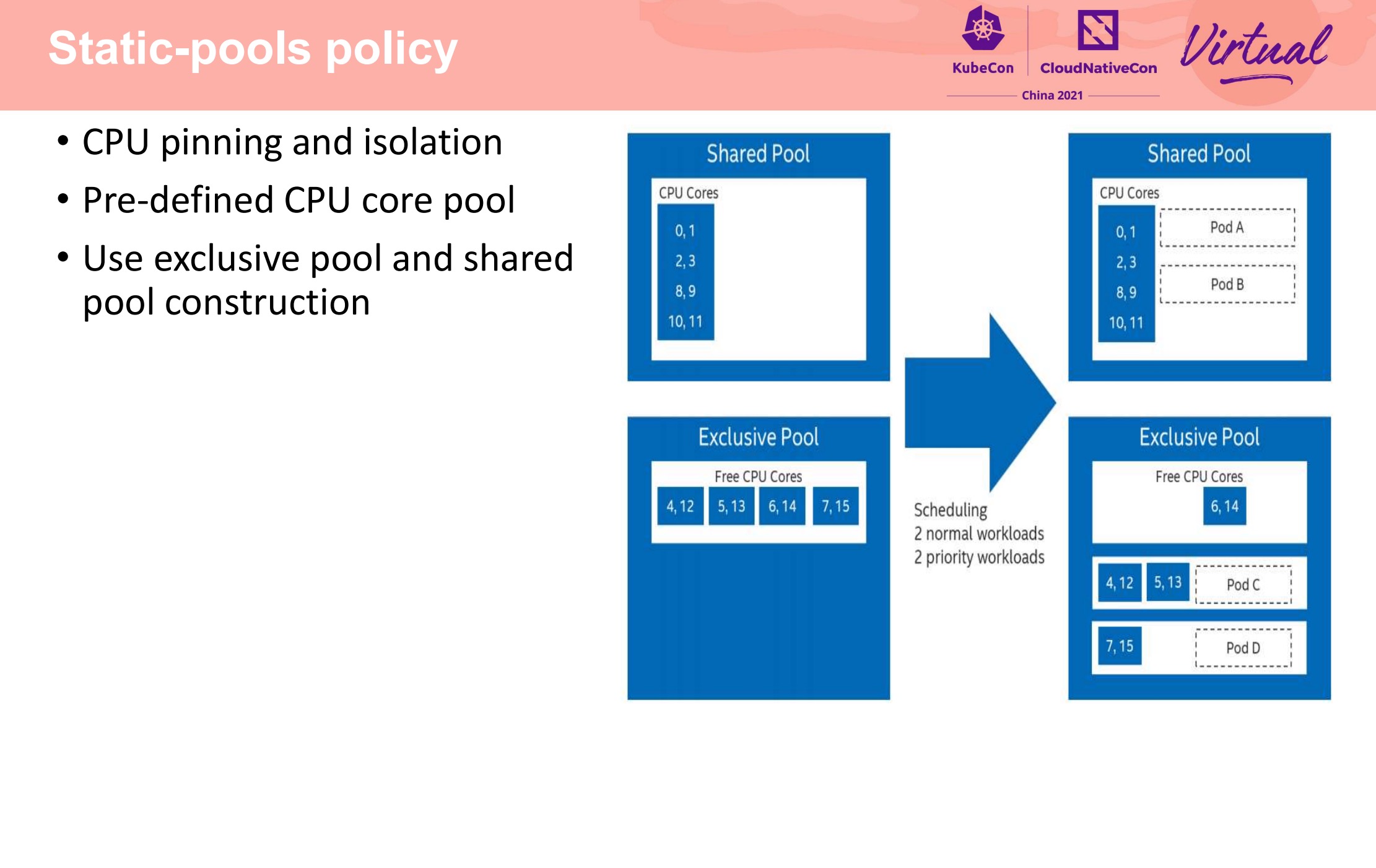
在每个节点上做了小粒度的 CPU 池化,将 CPU 分成能共享和不能共享两类。
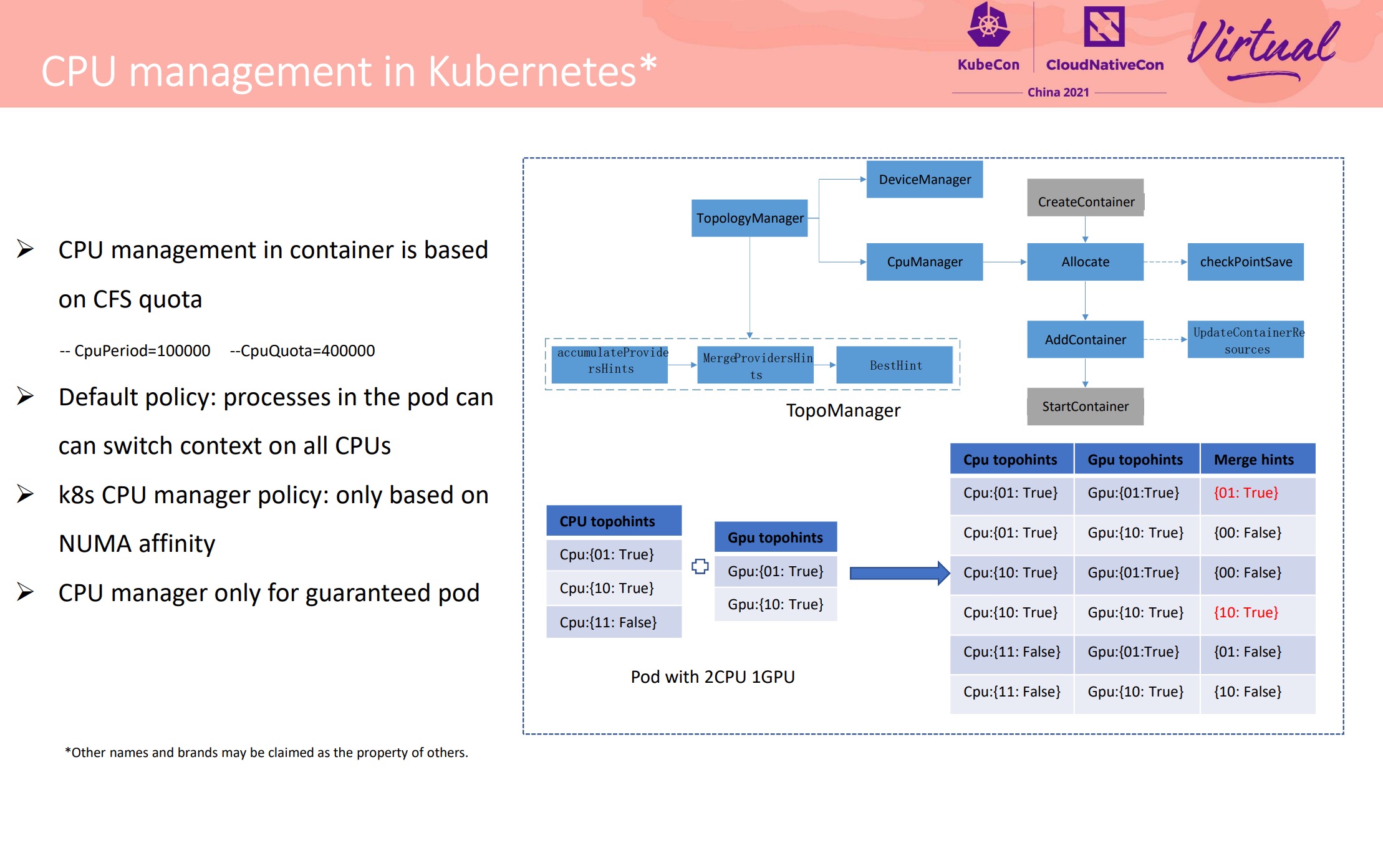
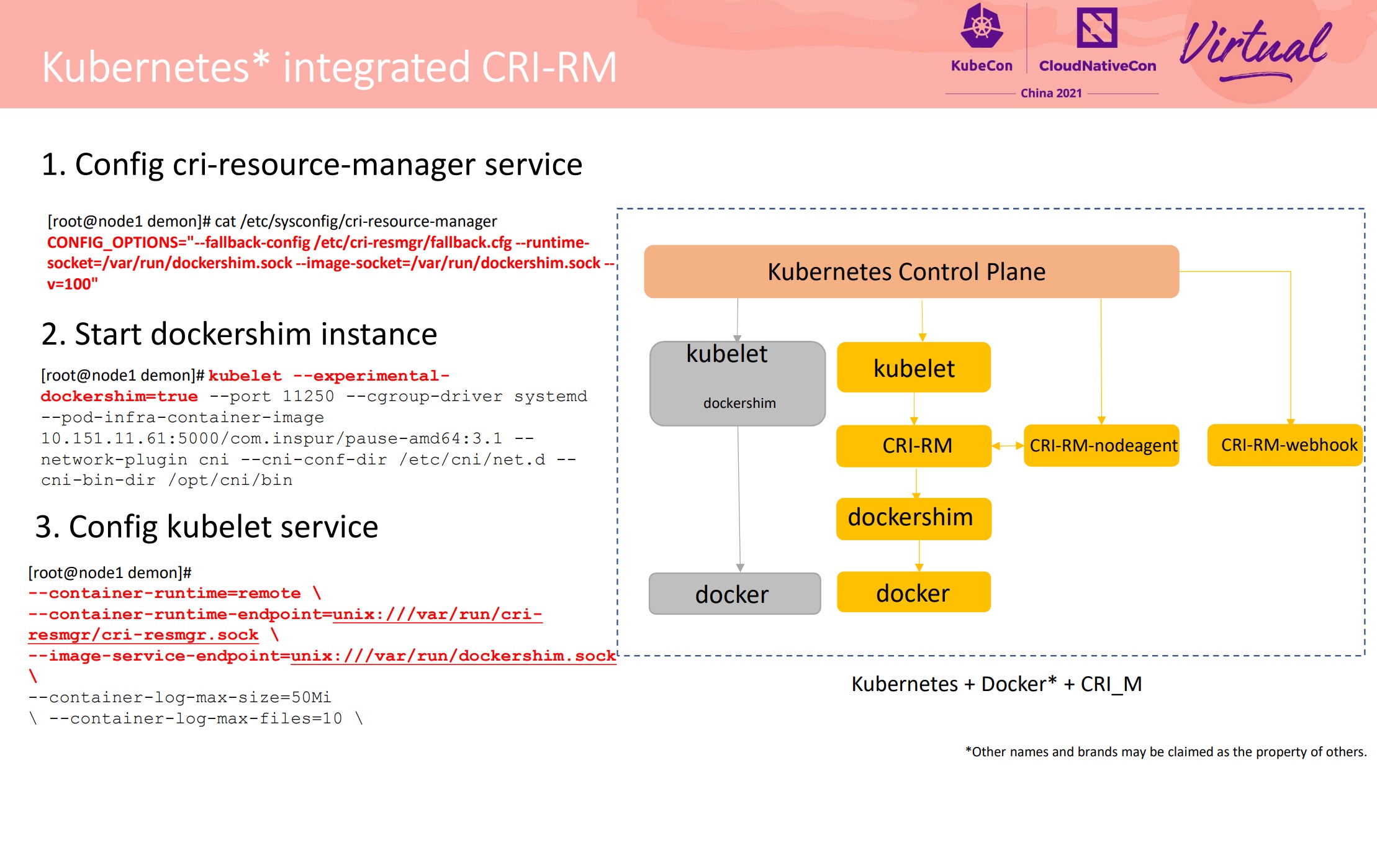

项目开源仓库地址: https://github.com/intel/cri-resource-manager
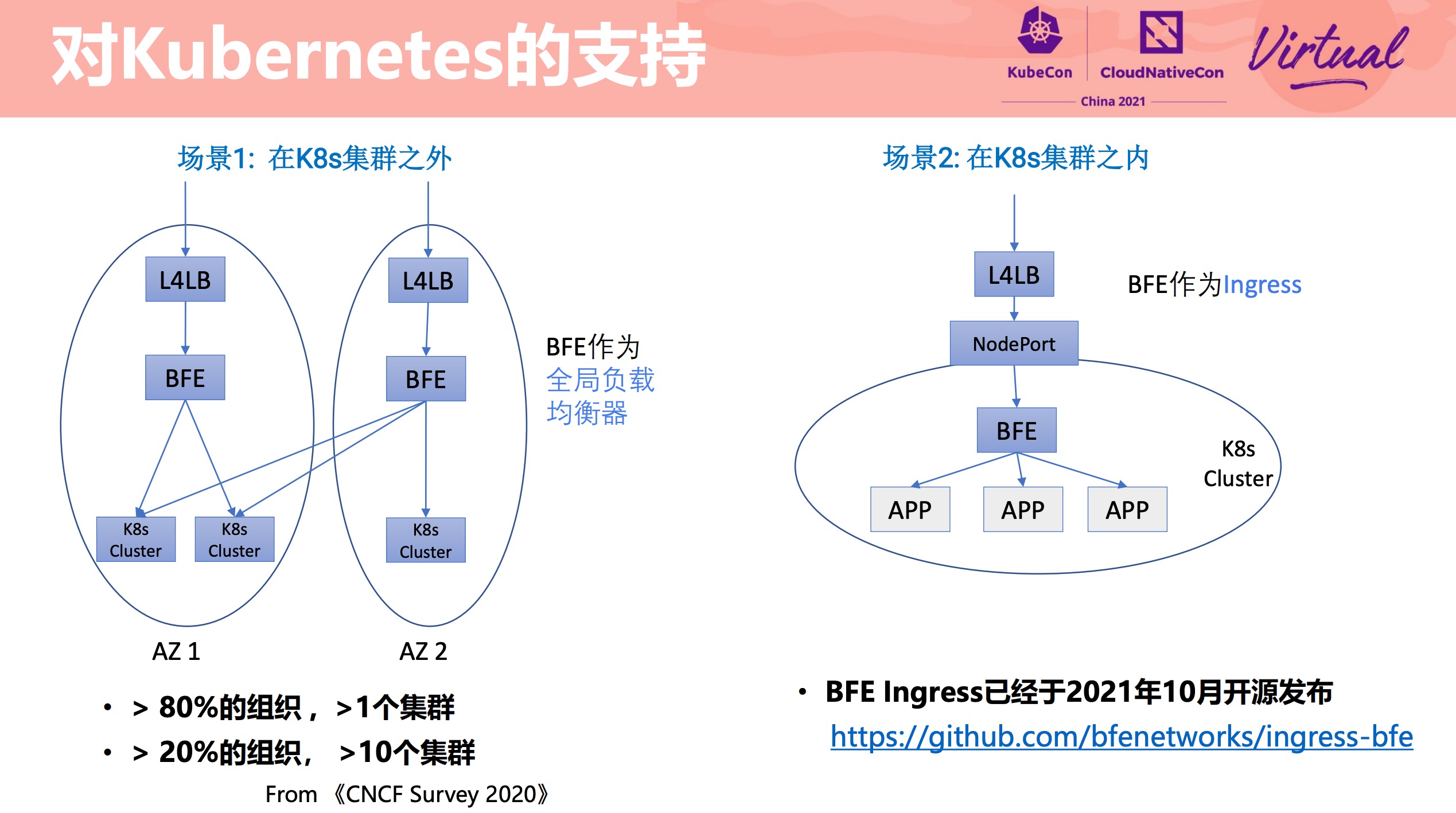
BFE Modern Layer 7 Load Balancer for Enterprise Application
BFE 支持了 Ingress。
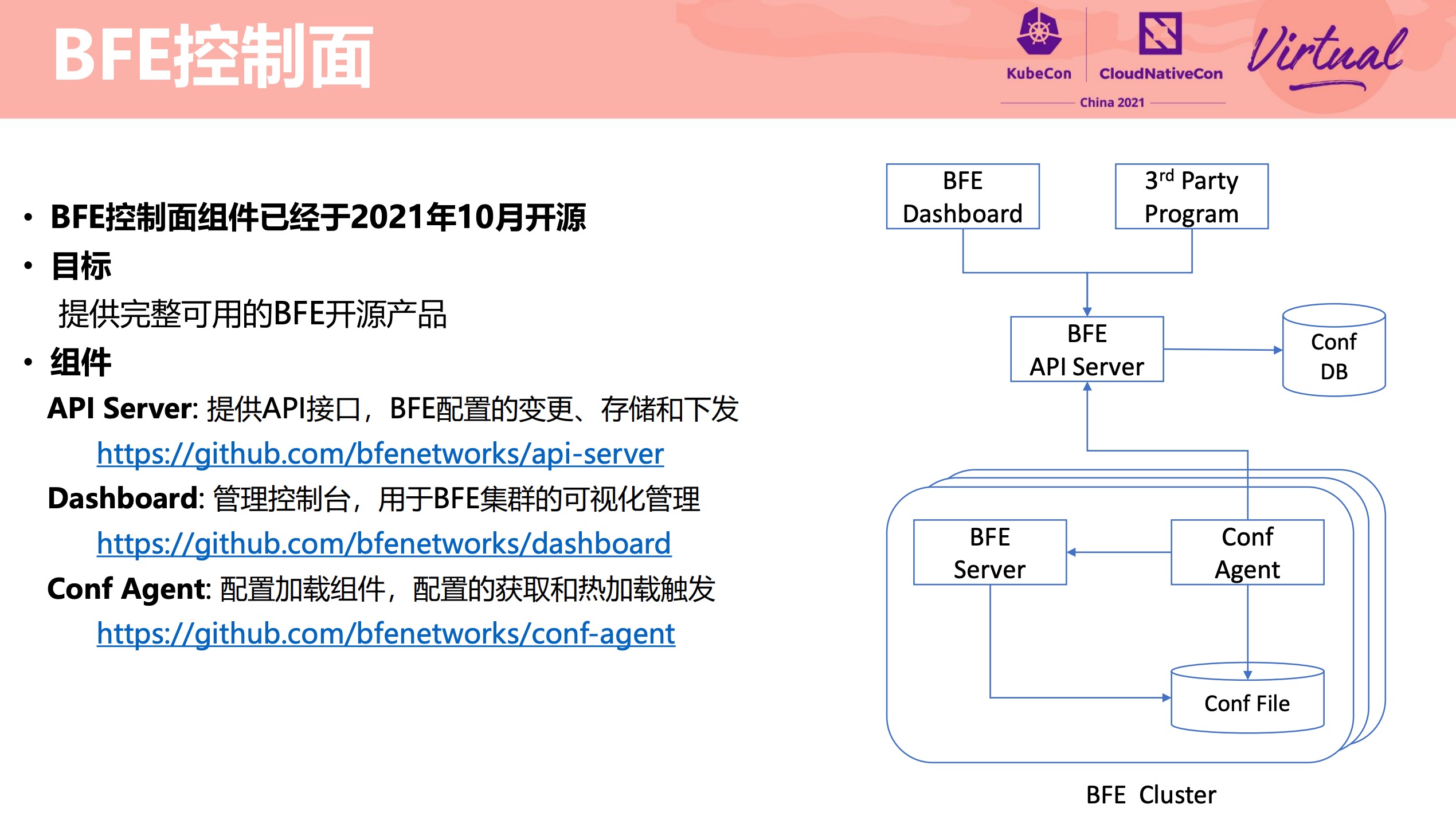
控制平面也开源了:
- https://github.com/bfenetworks/dashboard
- https://github.com/bfenetworks/api-server
- https://github.com/bfenetworks/conf-agent
BFE 没什么好说的,用就对了。
Best Practice DNS Failure Observability and Diagnosis in Kubernetes
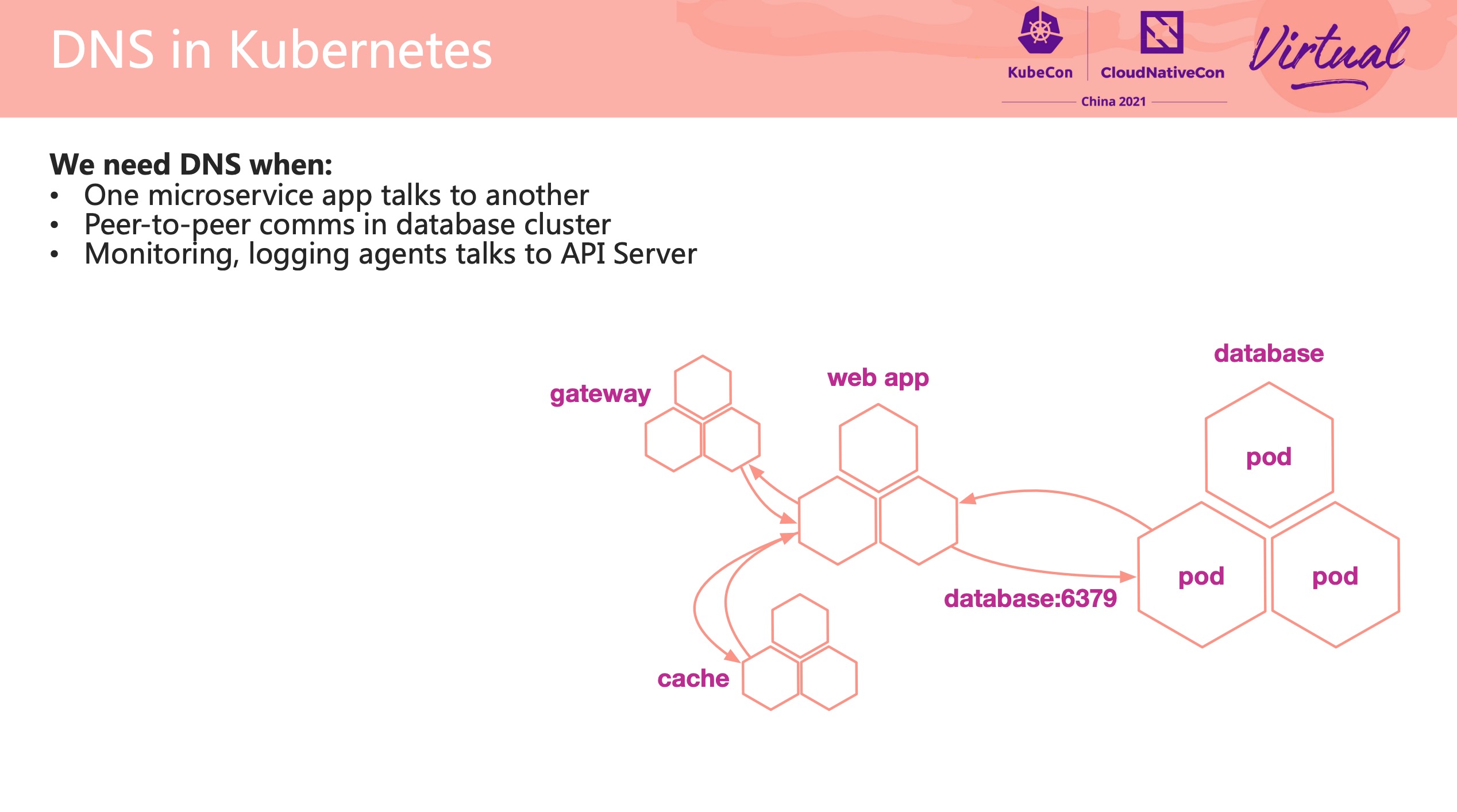
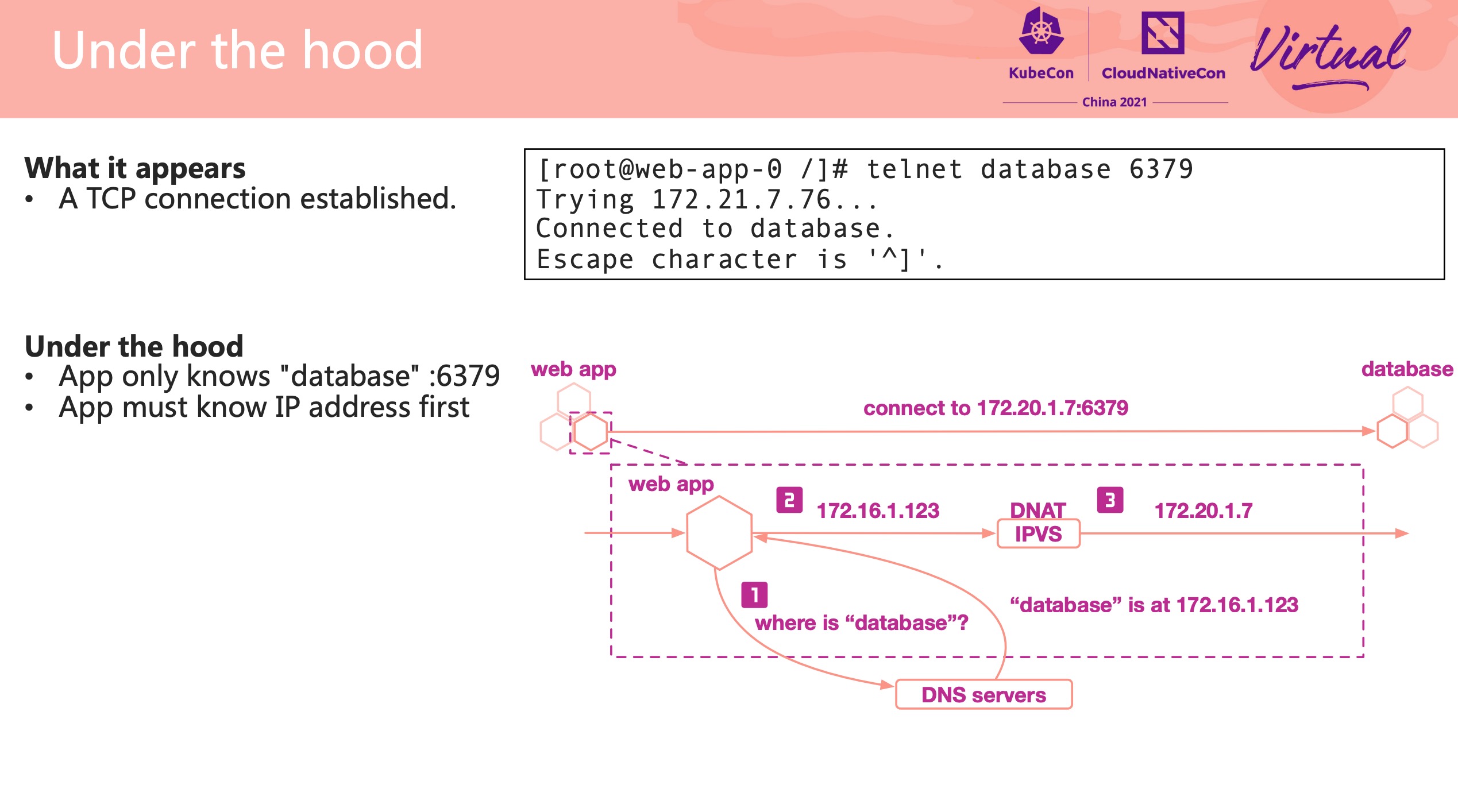
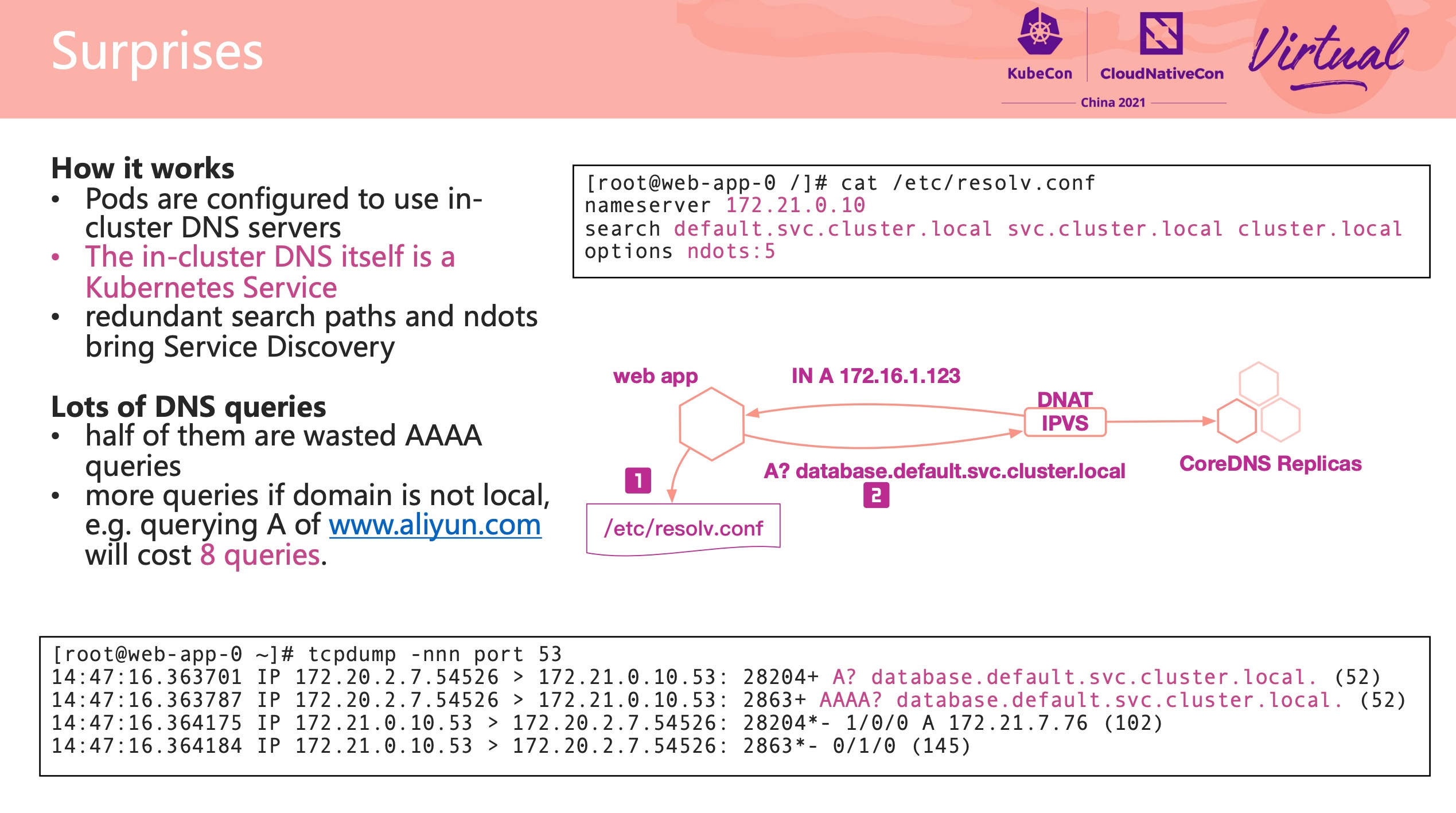


都是常见问题,基本都遇到过。
可以配合官方文档食用: https://kubernetes.io/zh/docs/tasks/administer-cluster/dns-debugging-resolution/
服务端诊断:

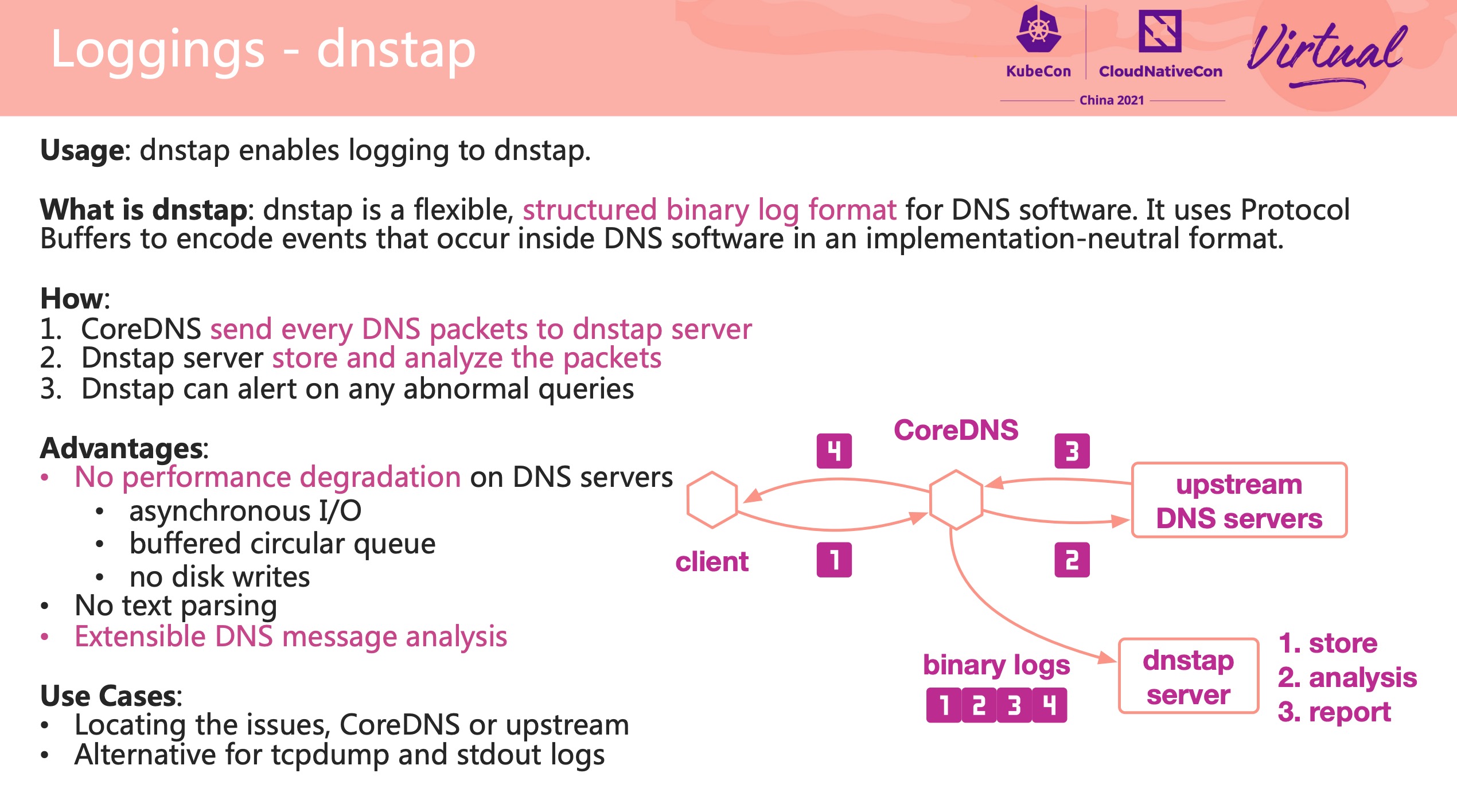


dnstap 插件比较有用。
客户端诊断:

https://gist.github.com/xh4n3/61d8081b834d7e21bff723614e07777c
果然,也提到了 pwru。 pwru 才是 YYDS。
pwru 刚开源没多久: https://github.com/cilium/pwru

Packet, Where are you: https://www.youtube.com/watch?v=NhlR11Fp69g

More Secure and Confidential Computing on Linux with Nitro Enclaves
虽然也是打广告,但 Nitro Enclaves 这个东西还是挺有意思的。
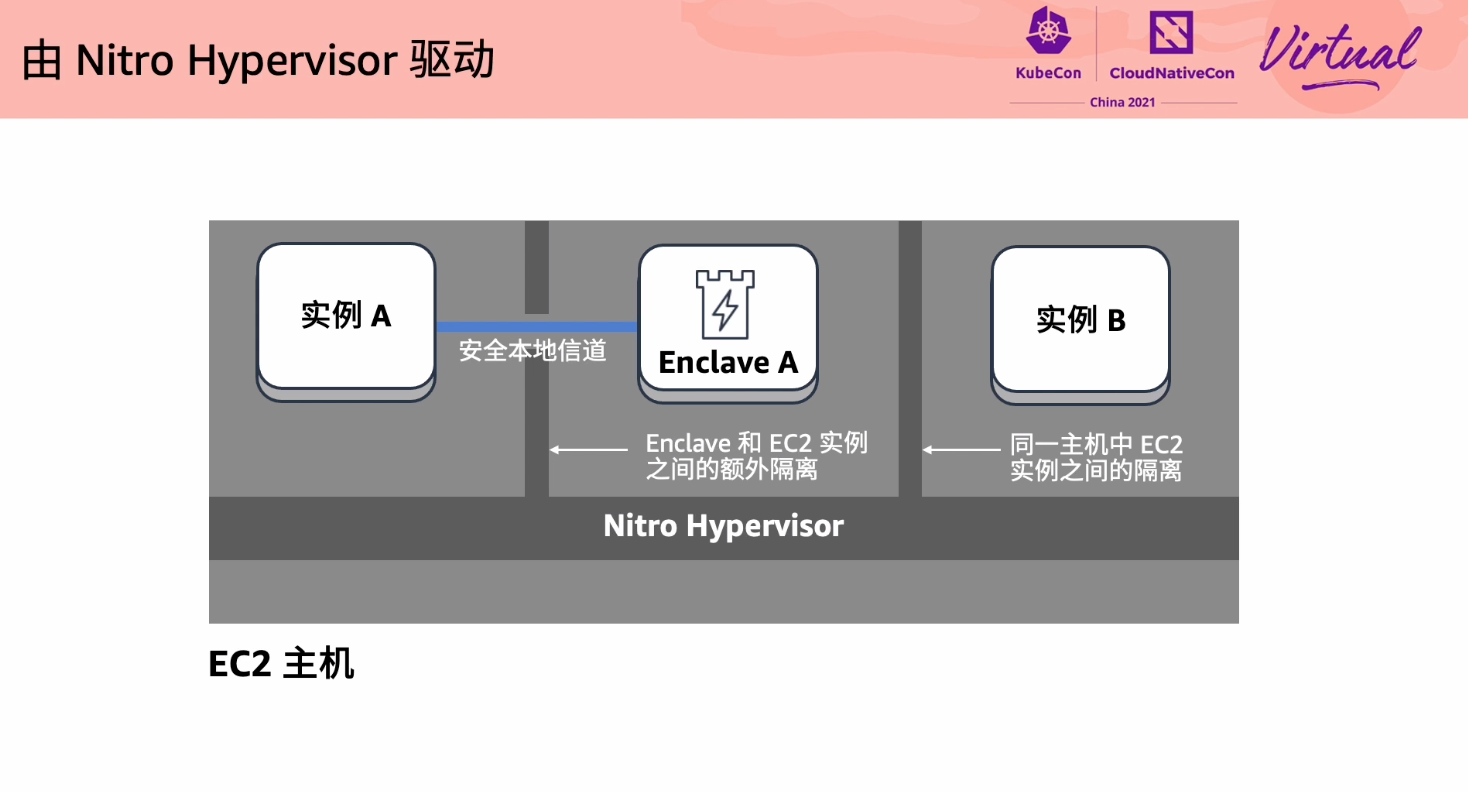
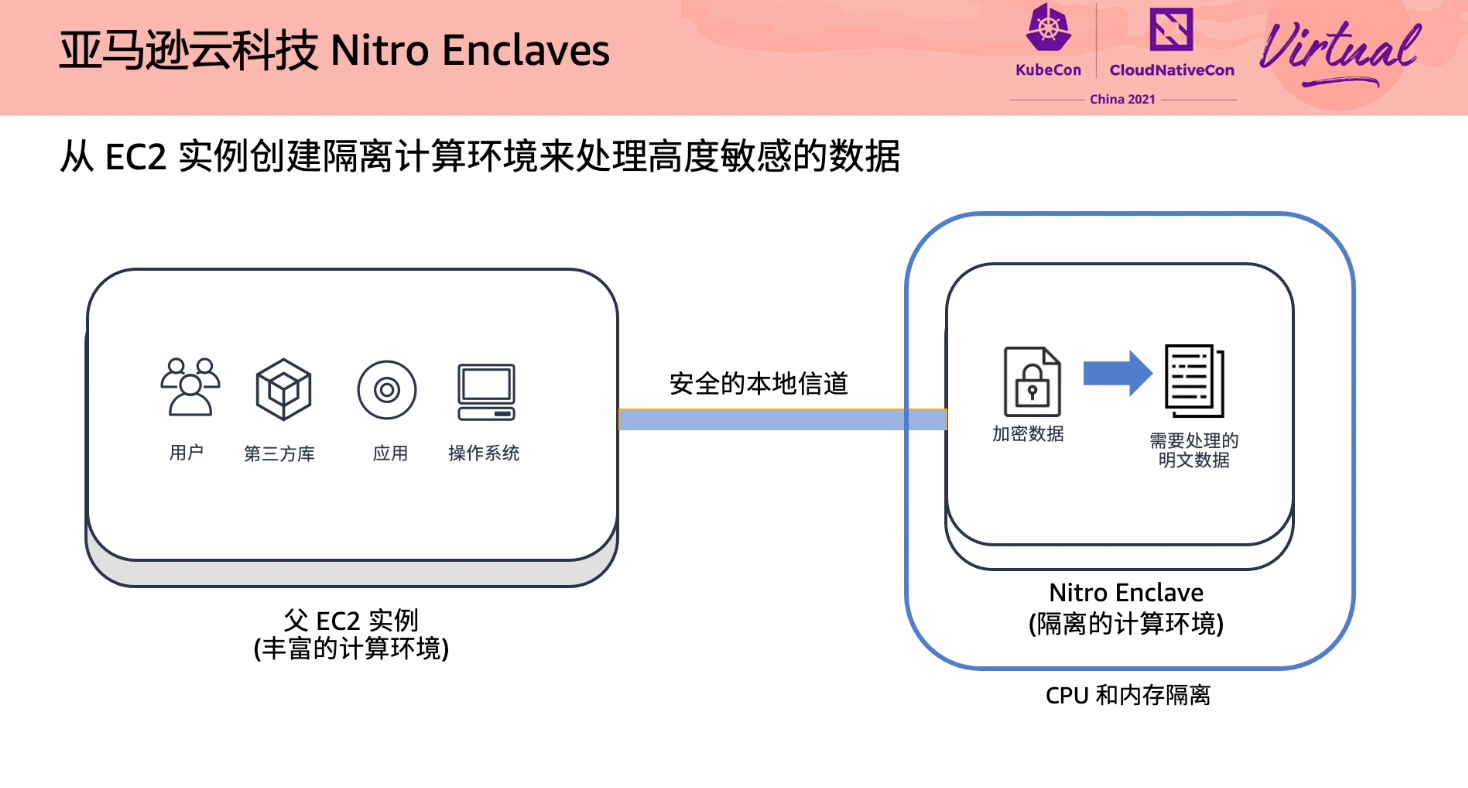

连 SSH 都没有。
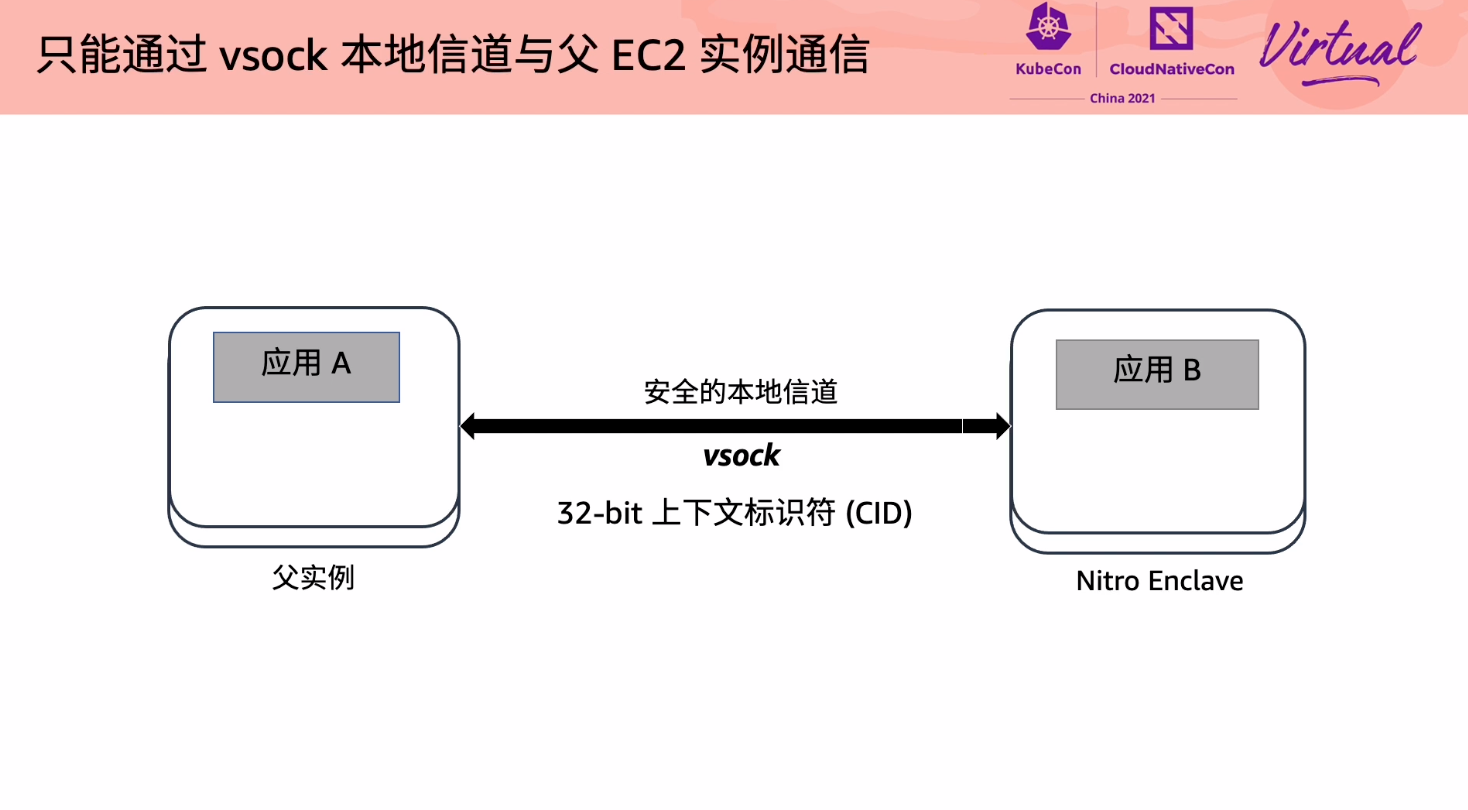

Exploring Cloud Native Big Data Platform in SPDB
一个新项目 Piraeus Datastore: https://github.com/piraeusdatastore/piraeus
DRBD 这个技术还是非常有意思的: https://github.com/LINBIT/drbd
DRBD 是一个基于软件的、shared-nothing、复制机制的存储解决方案,在主机之间镜像块设备(硬盘、分区、逻辑卷等)的内容。
- real time,数据的修改会被实时同步
- transparently,应用程序不需要感知数据存储在多个主机上
- synchronously or asynchronously
DRBD 构成了一个虚拟块设备的驱动程序,DRBD 位于系统 I/O 堆栈的底部。 DRBD 无法识别文件系统是否损坏。
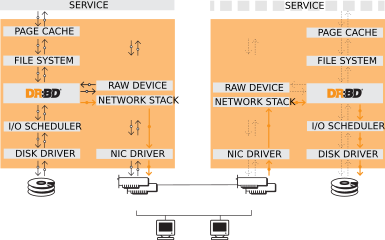
DRBD 是老技术了,没想到在 K8s 场景下还能接着用起来。
Vivo’s AI Computing Platform on Kubernetes
拼积木大合集,没有太多新意,但都非常落地,遇到了大家都可能会遇到的问题,也有一些通用的解决方案。

都是老生常谈的问题:
- Ring Allreduce
- 任务调度顺序

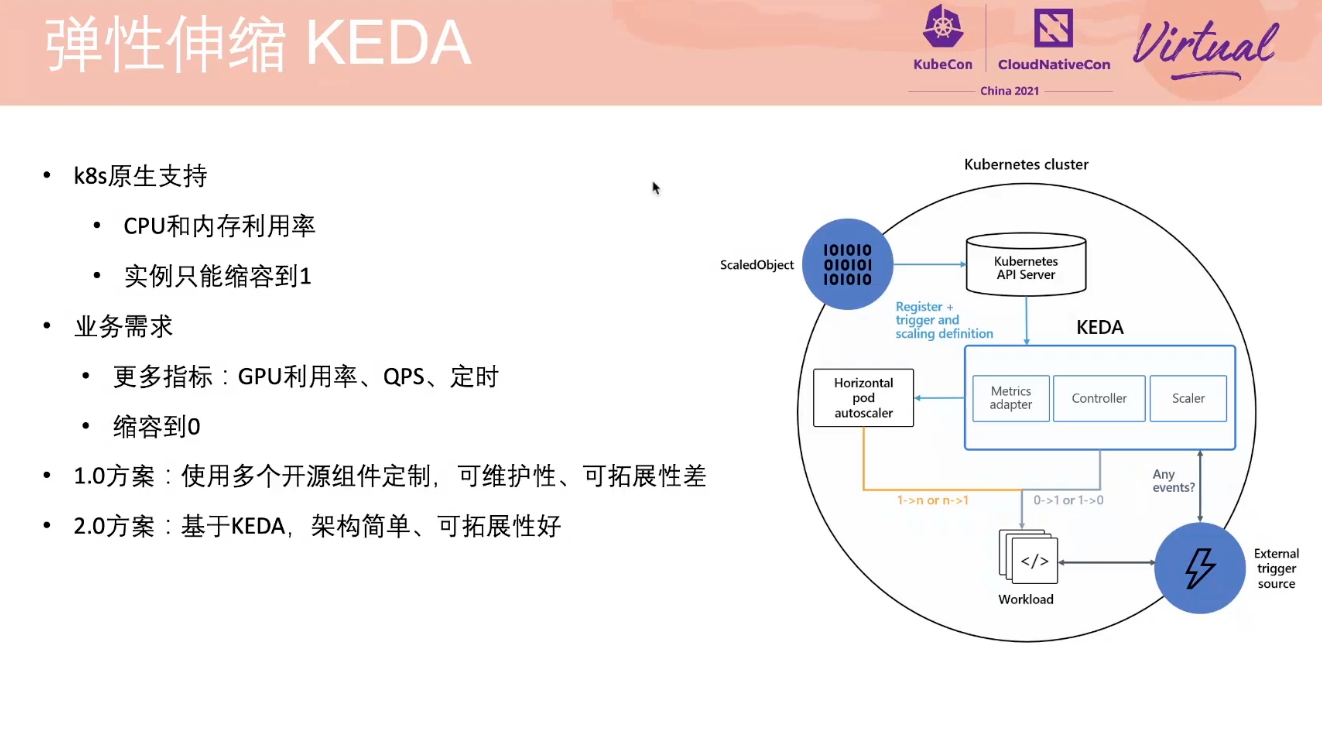
KEDA 其实也问题多多,即使自己写插件也只能解决一部分问题。
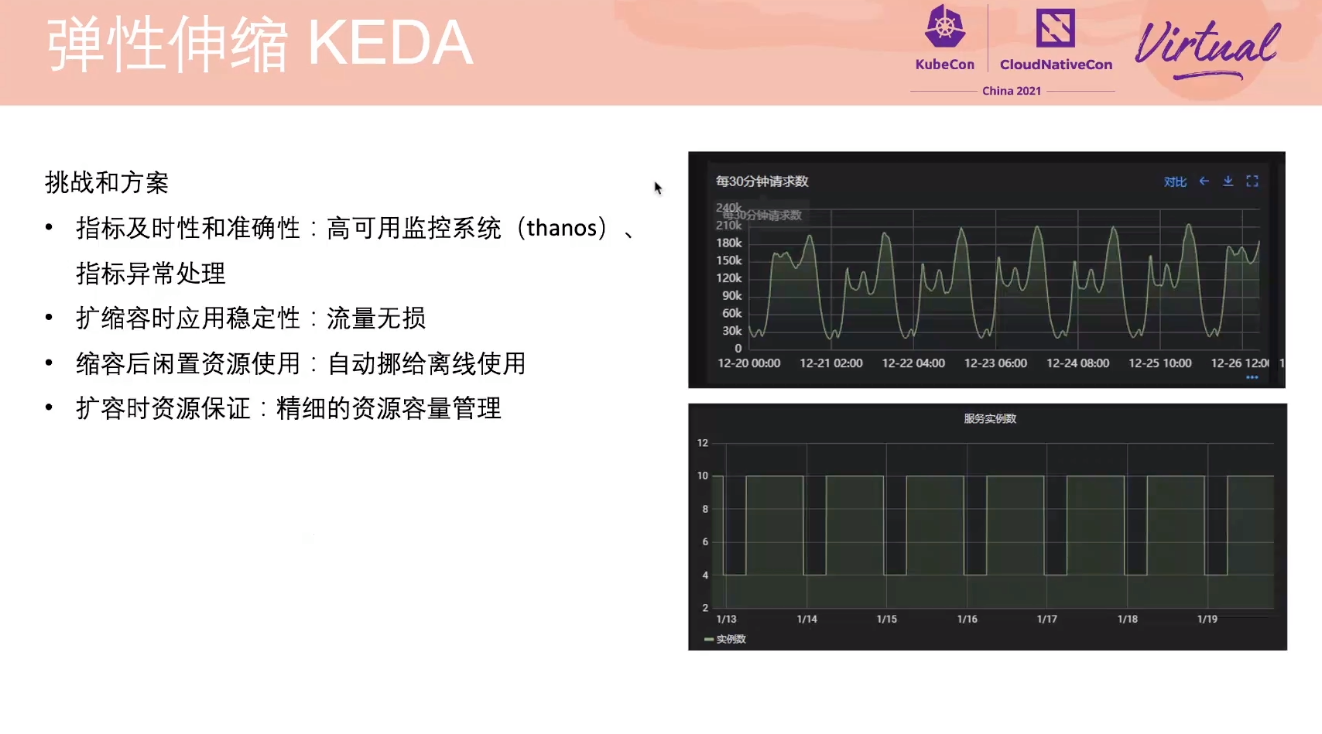
VictoriaMetrics 才是 Prometheus 的最佳归宿。

VK 问题也很多。
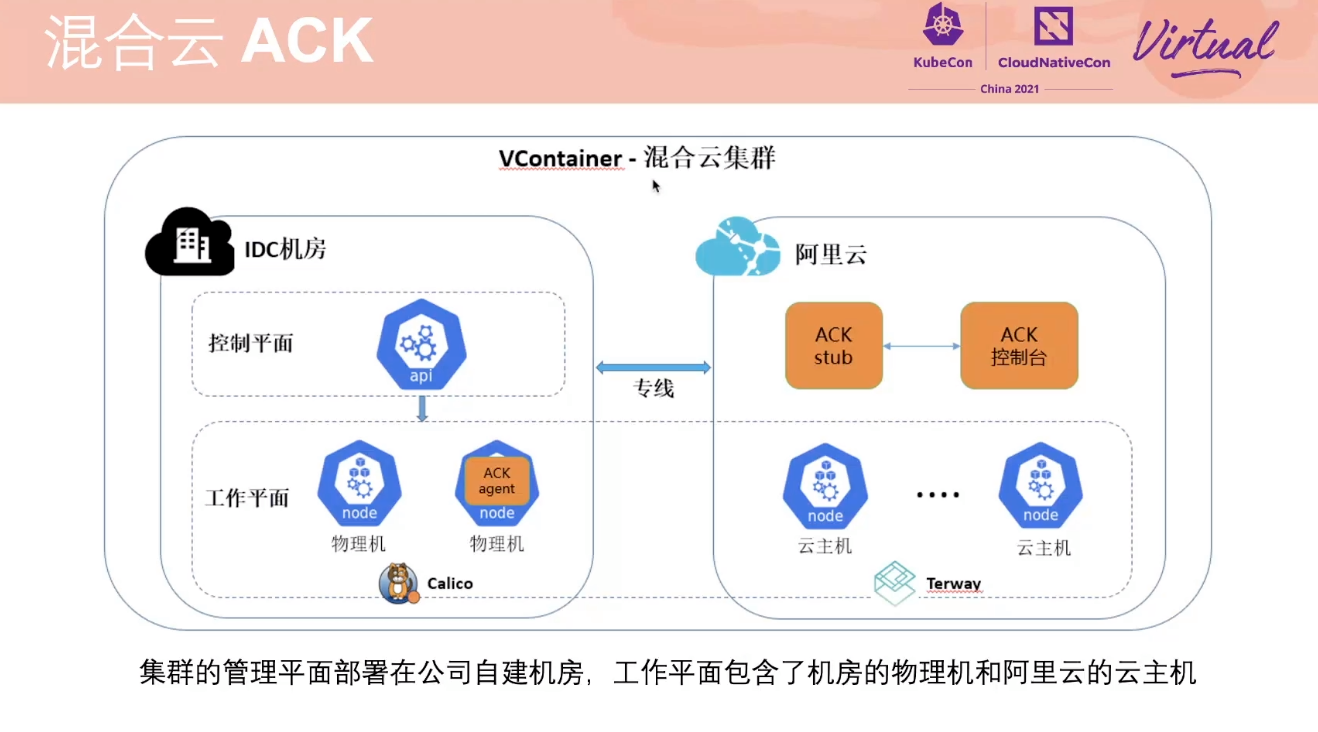
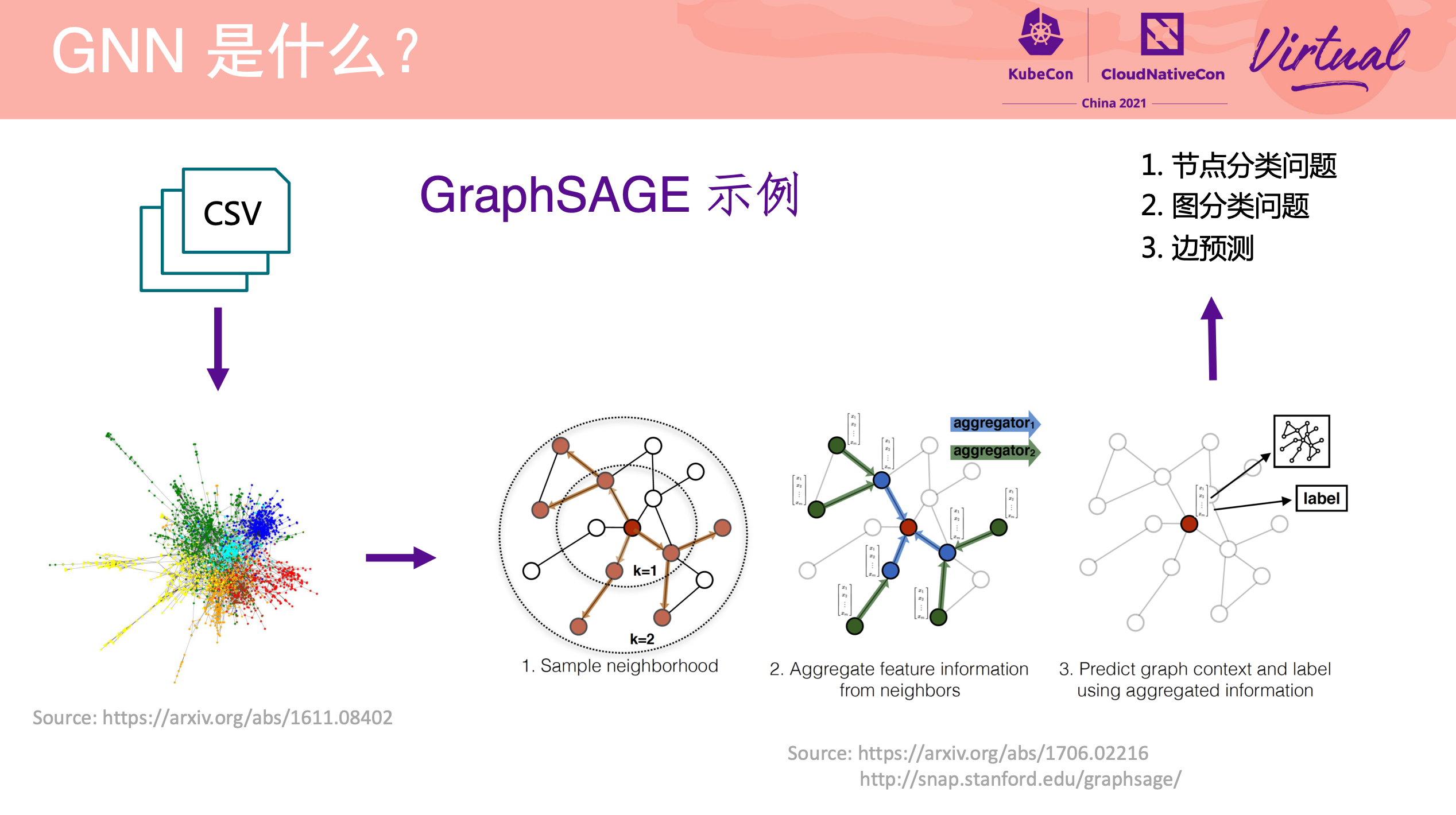
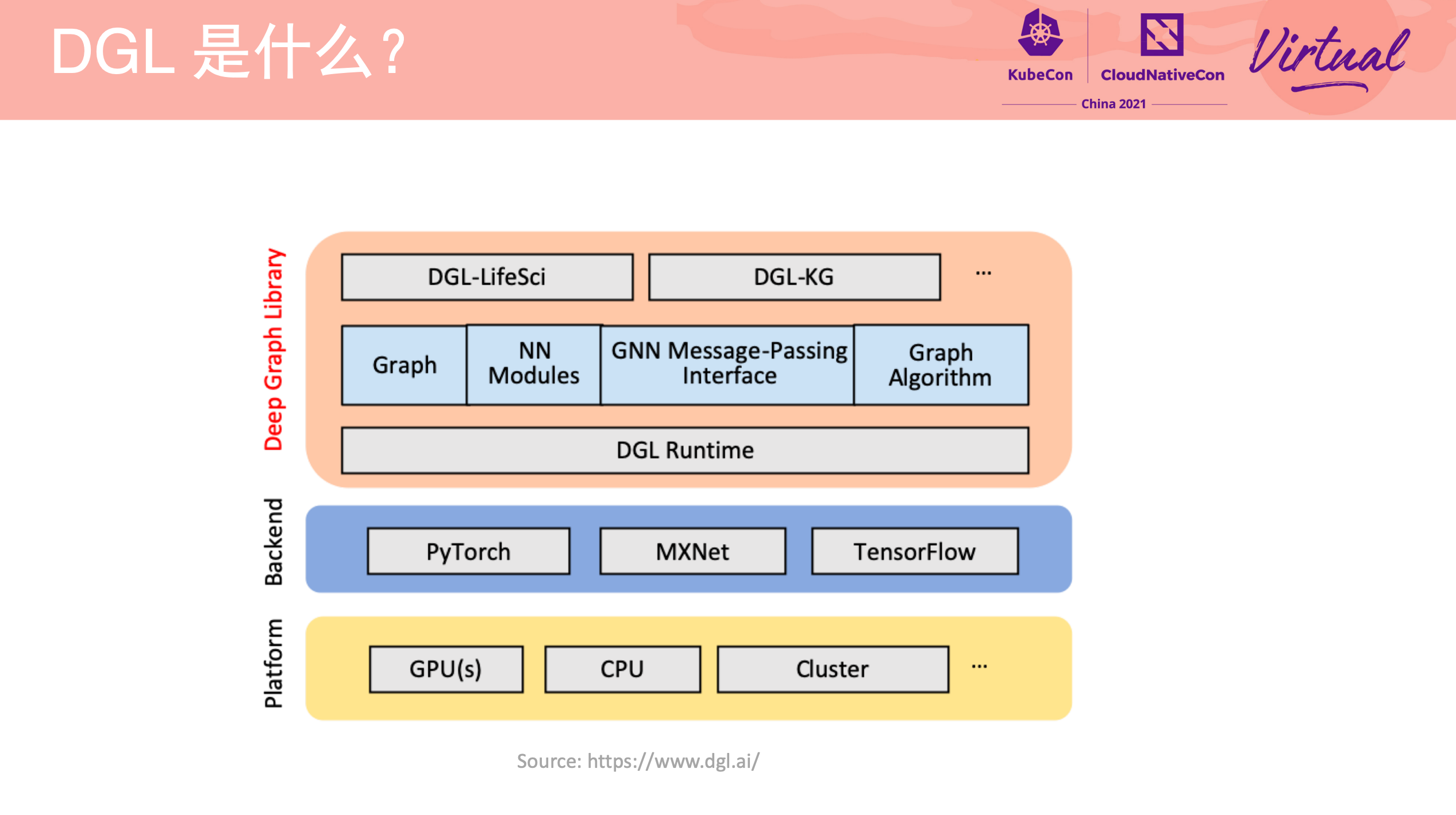
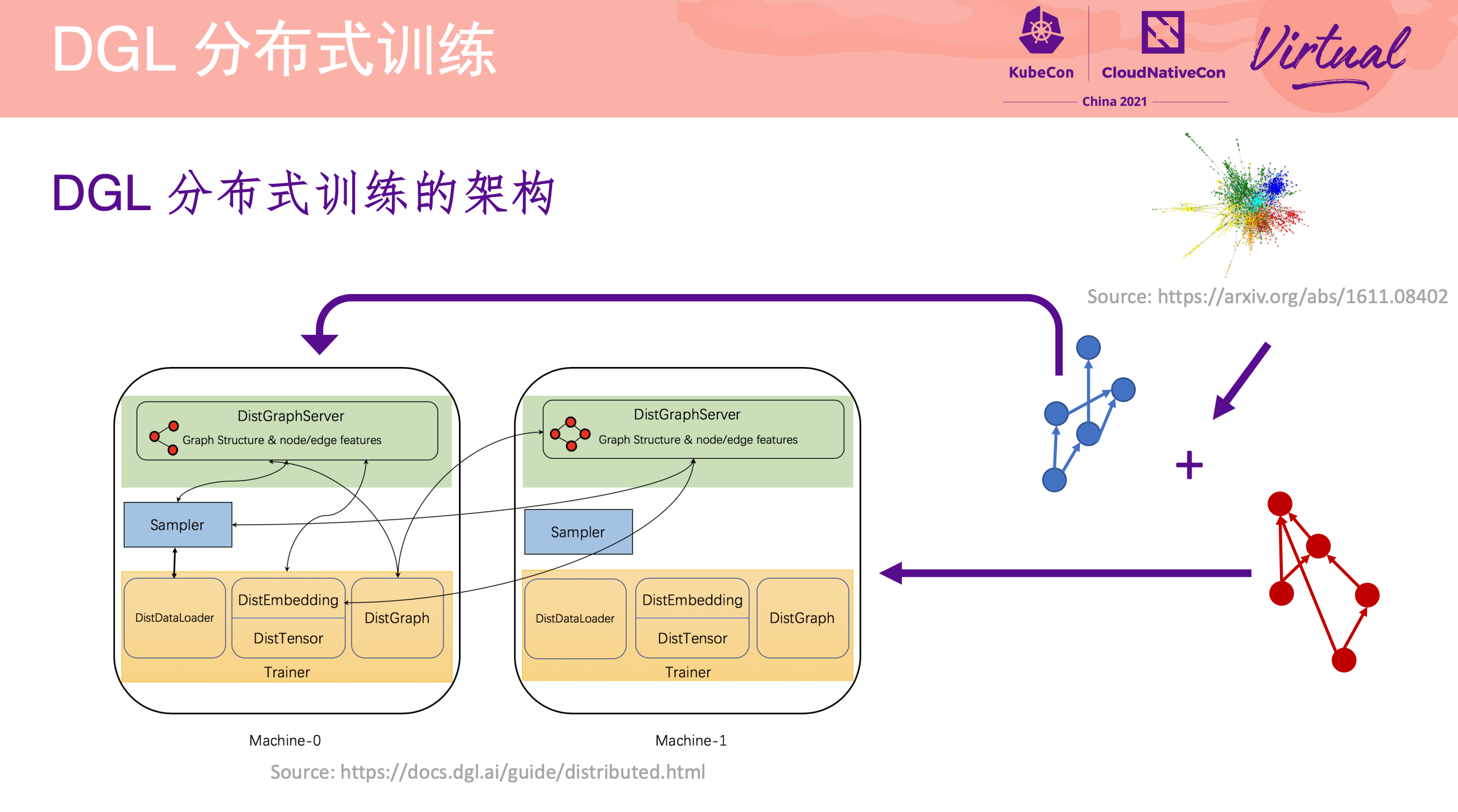
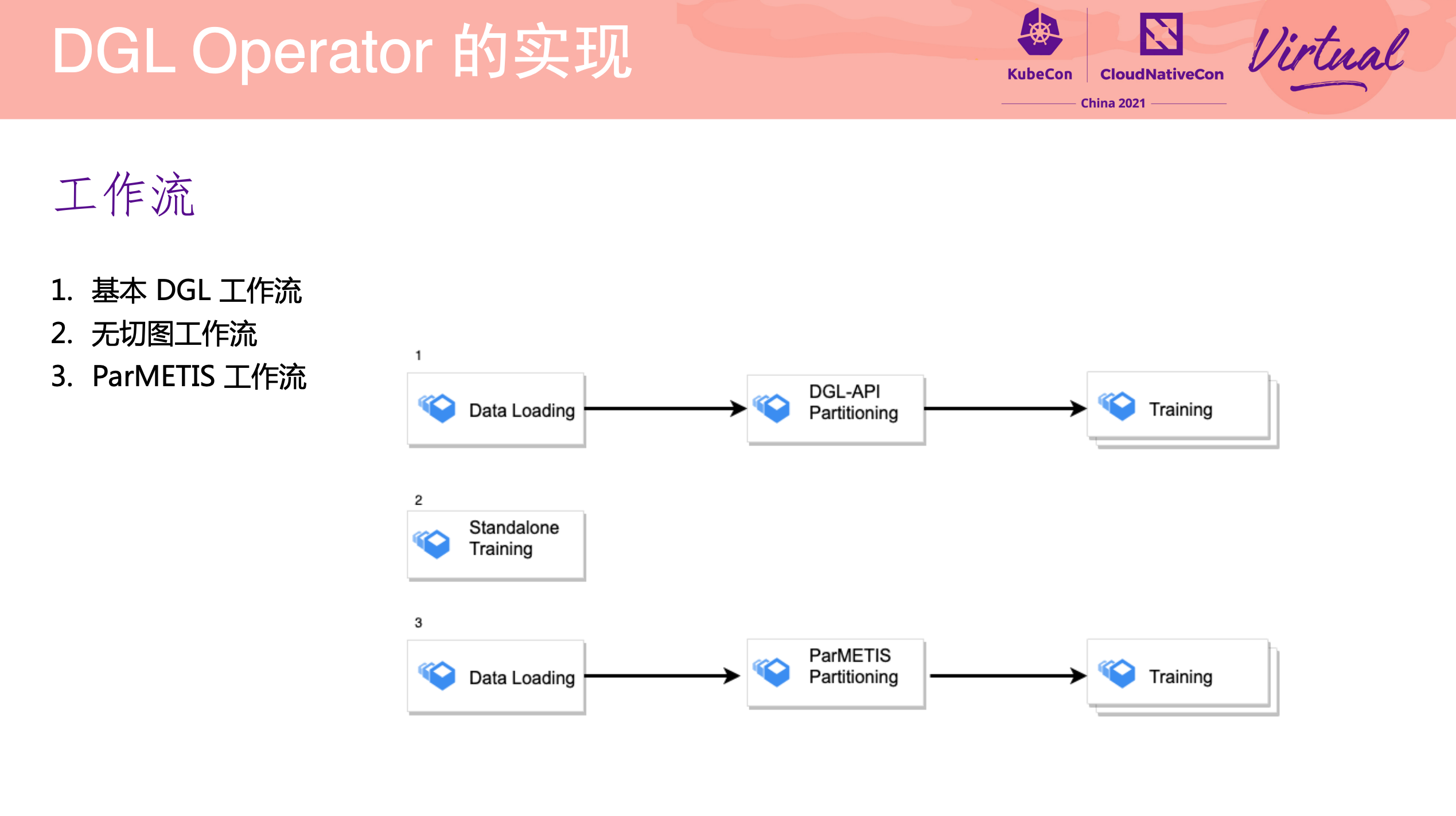
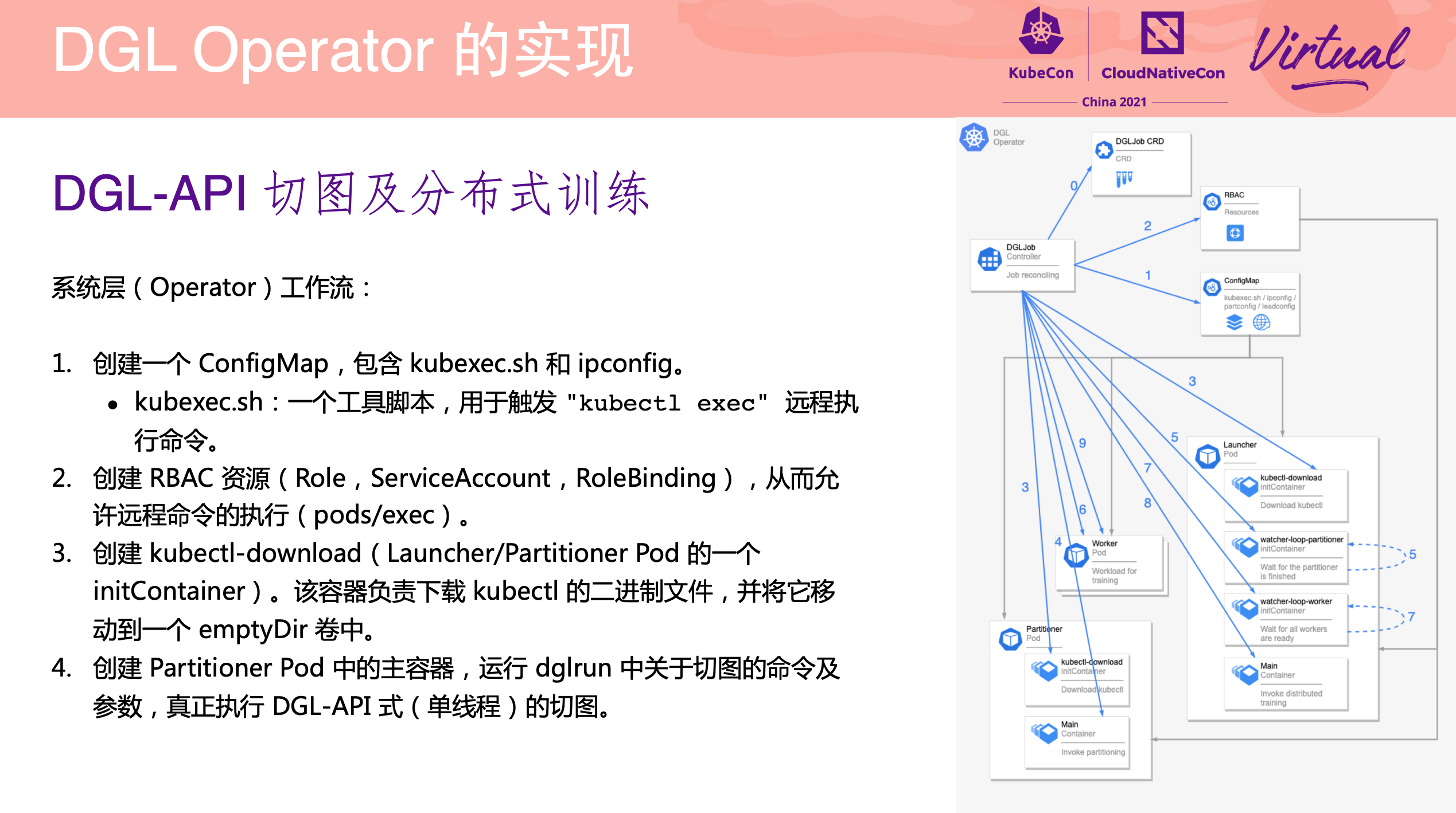
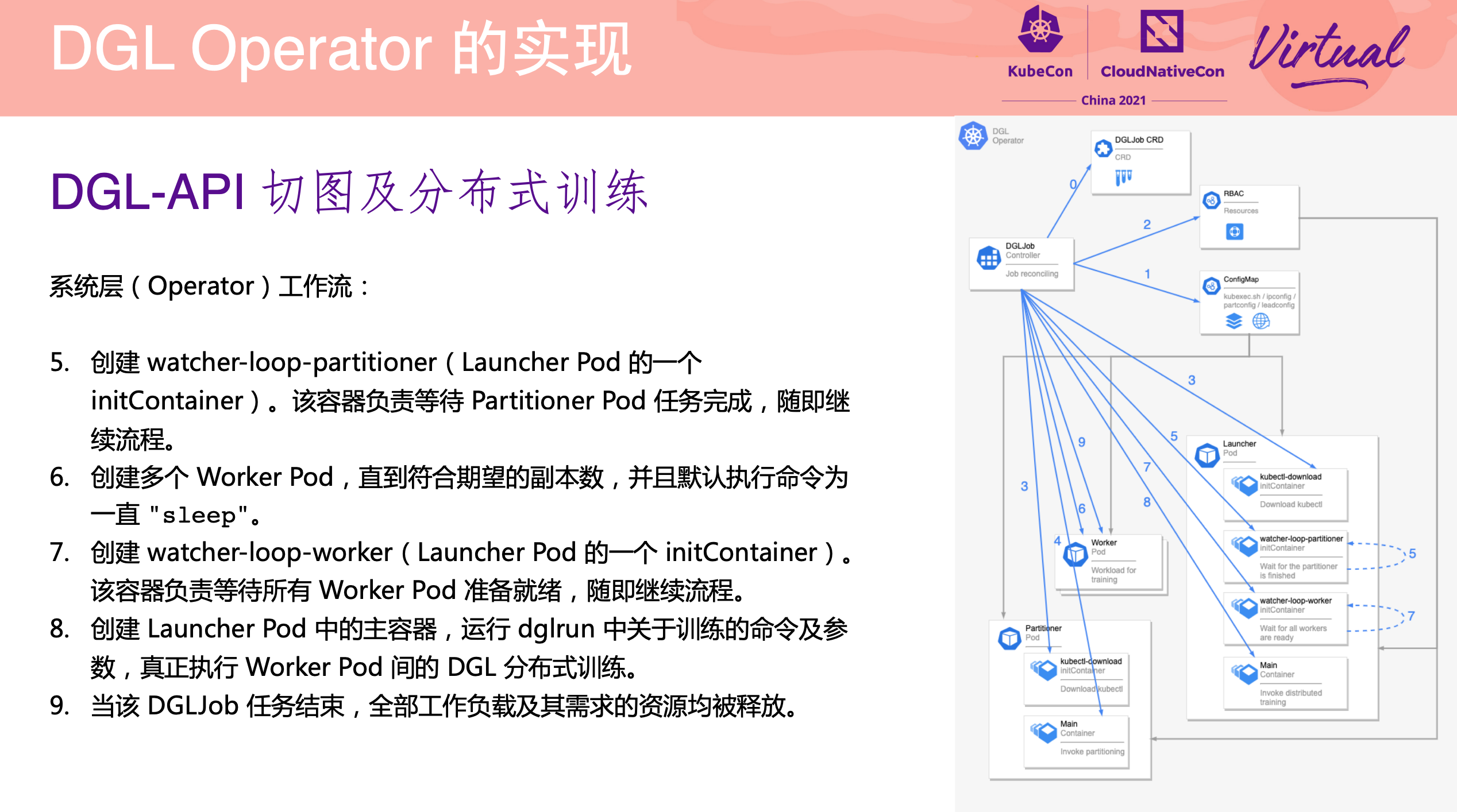
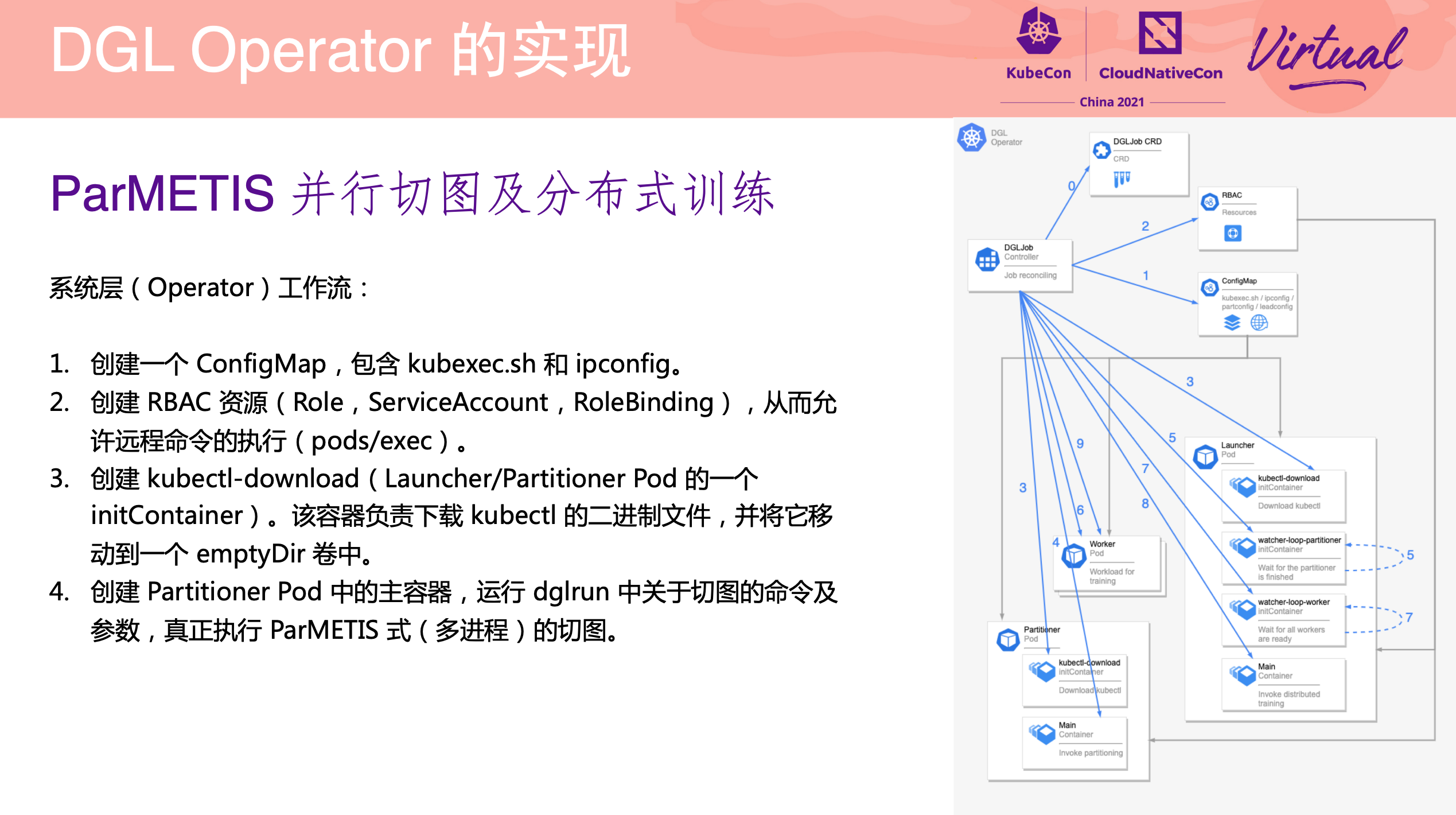
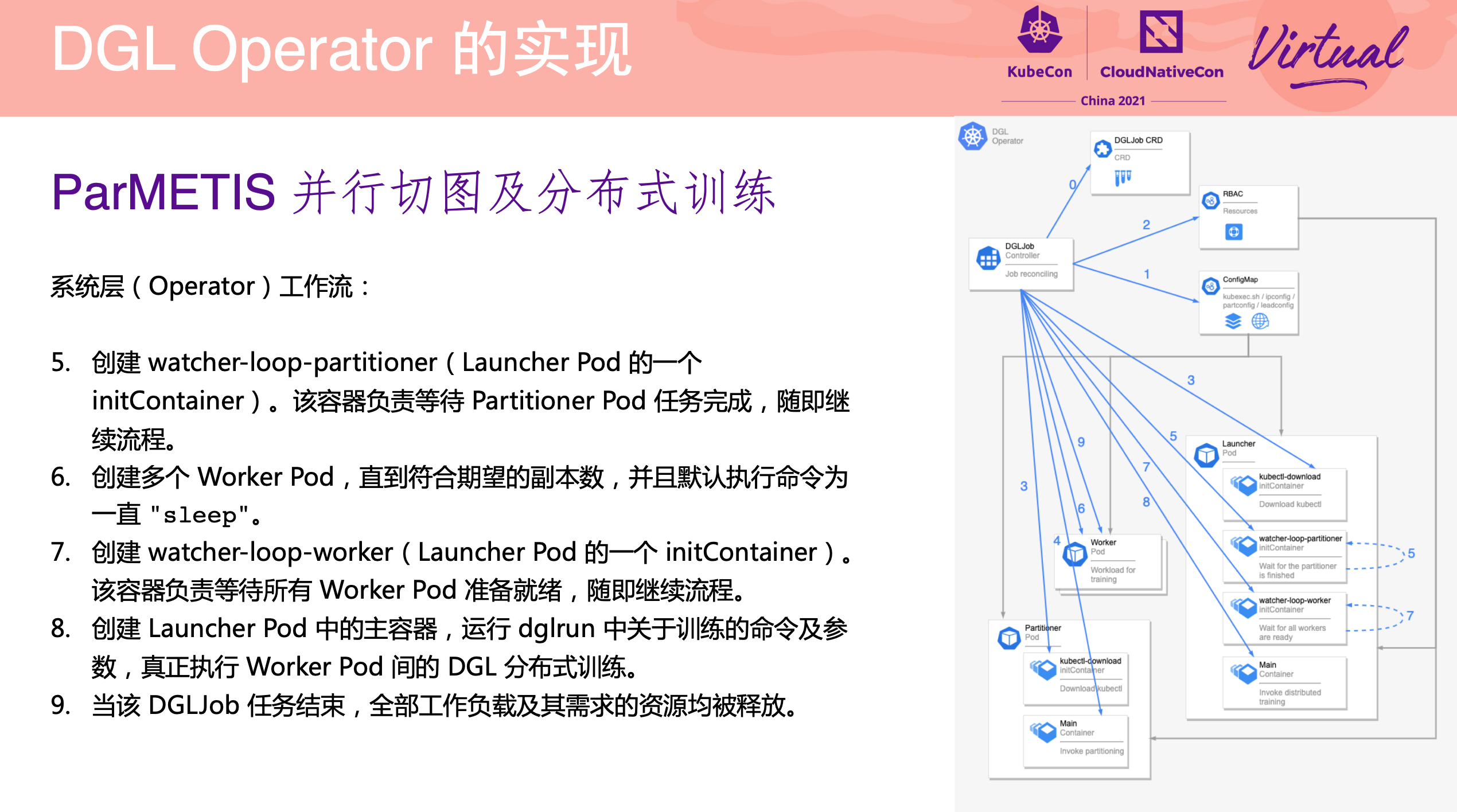
DGL Operator Distributed Graph Neural Network Training with DGL and K8s
一个 Operator 从 0 到 1 的实现过程。
项目已开源: https://github.com/Qihoo360/dgl-operator





SuperEdge Promoting Kubernetes to the Edge of Technology Decryption
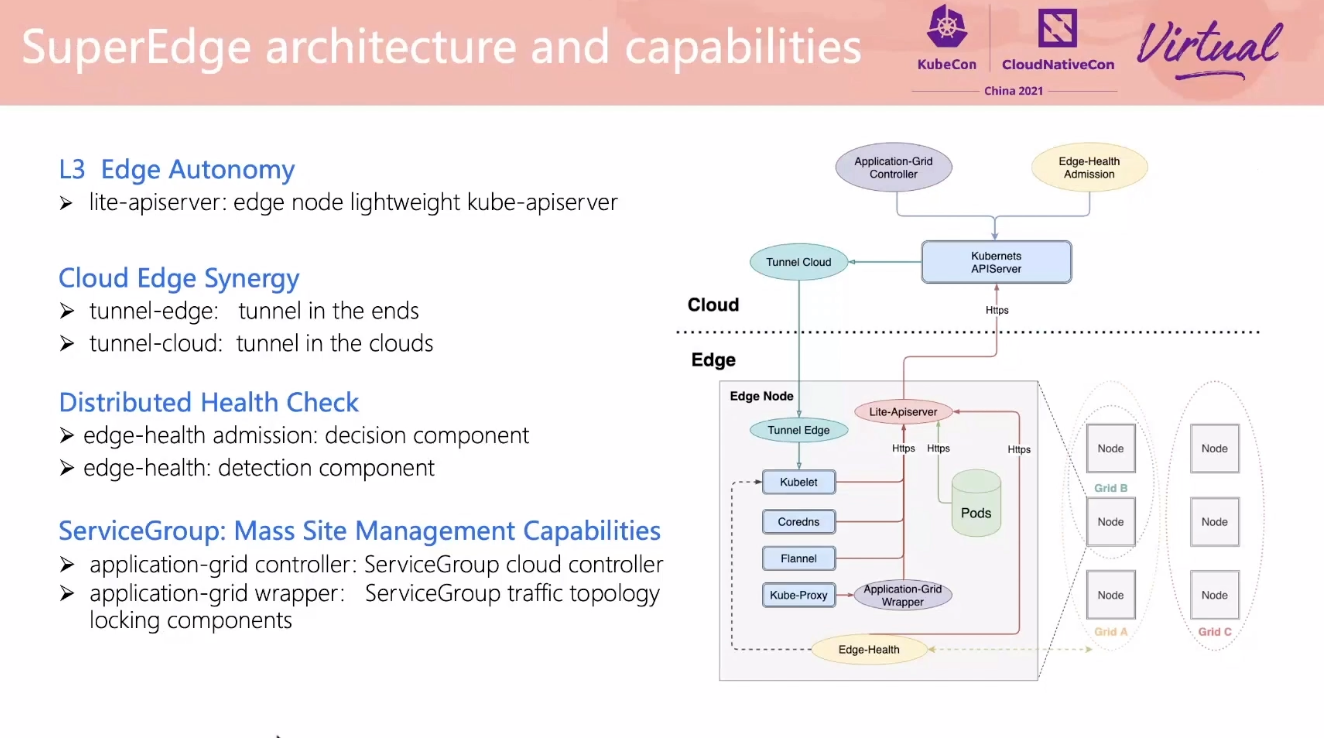
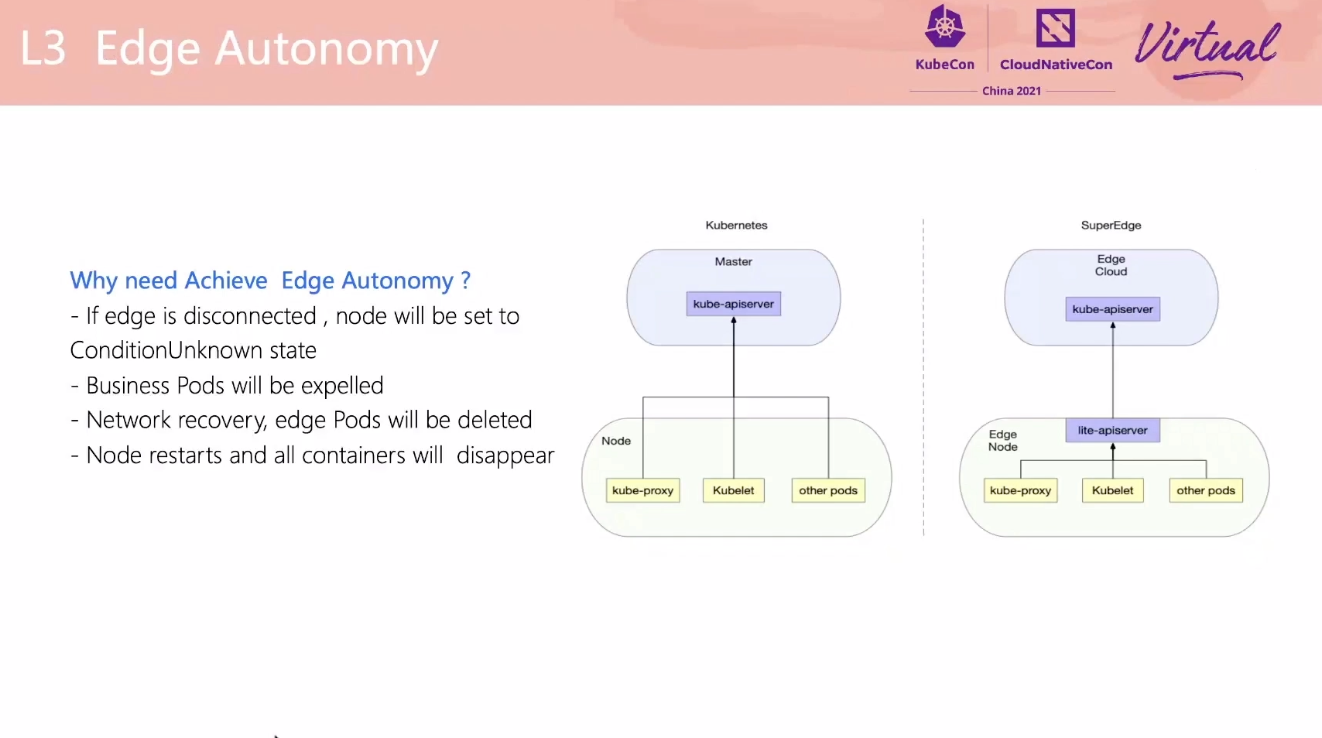
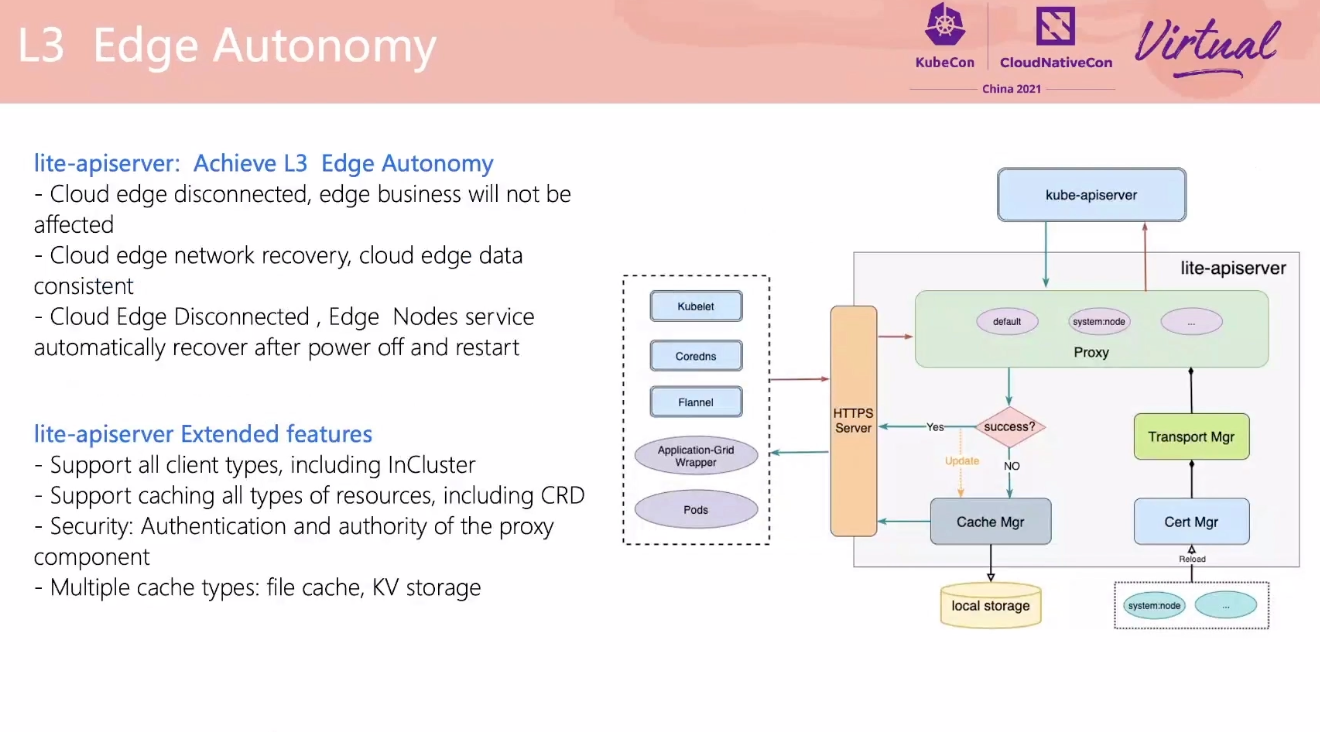
lite-apiserver 可以抽出来做通用的基础 apiserver 缓存层。
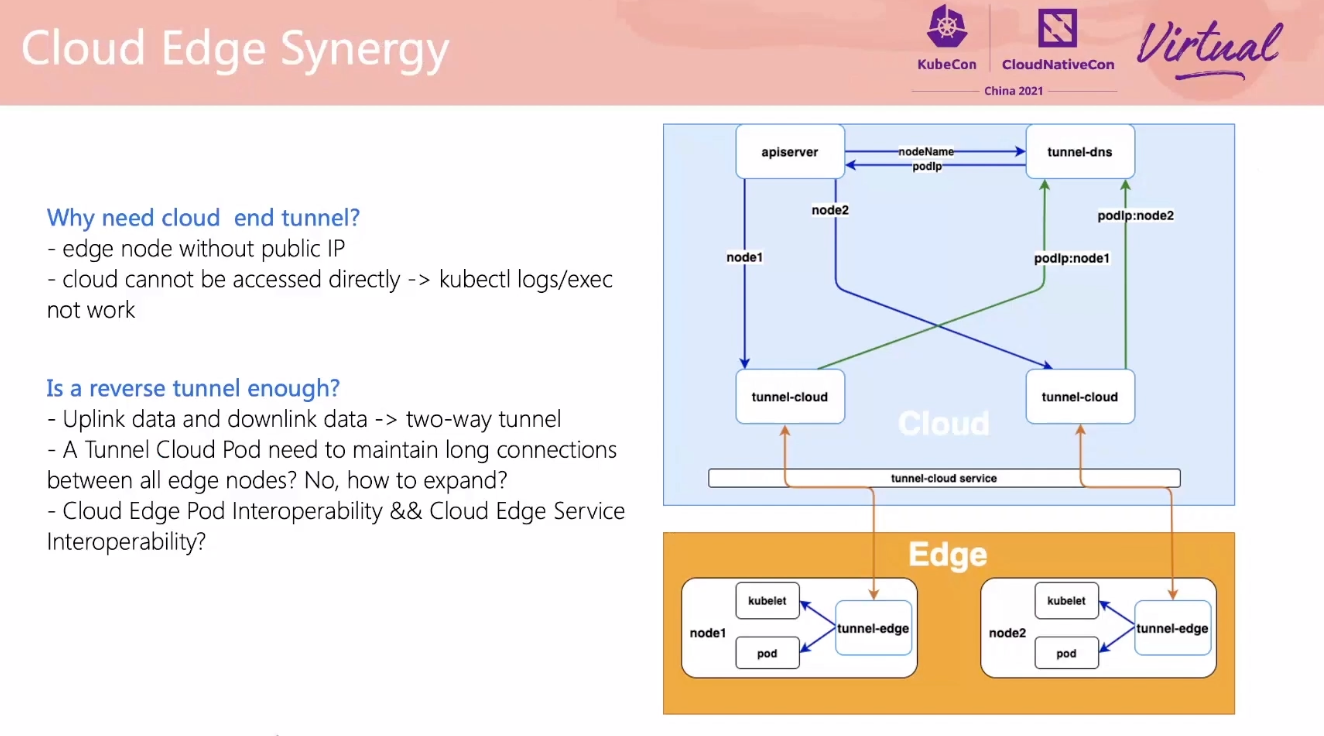
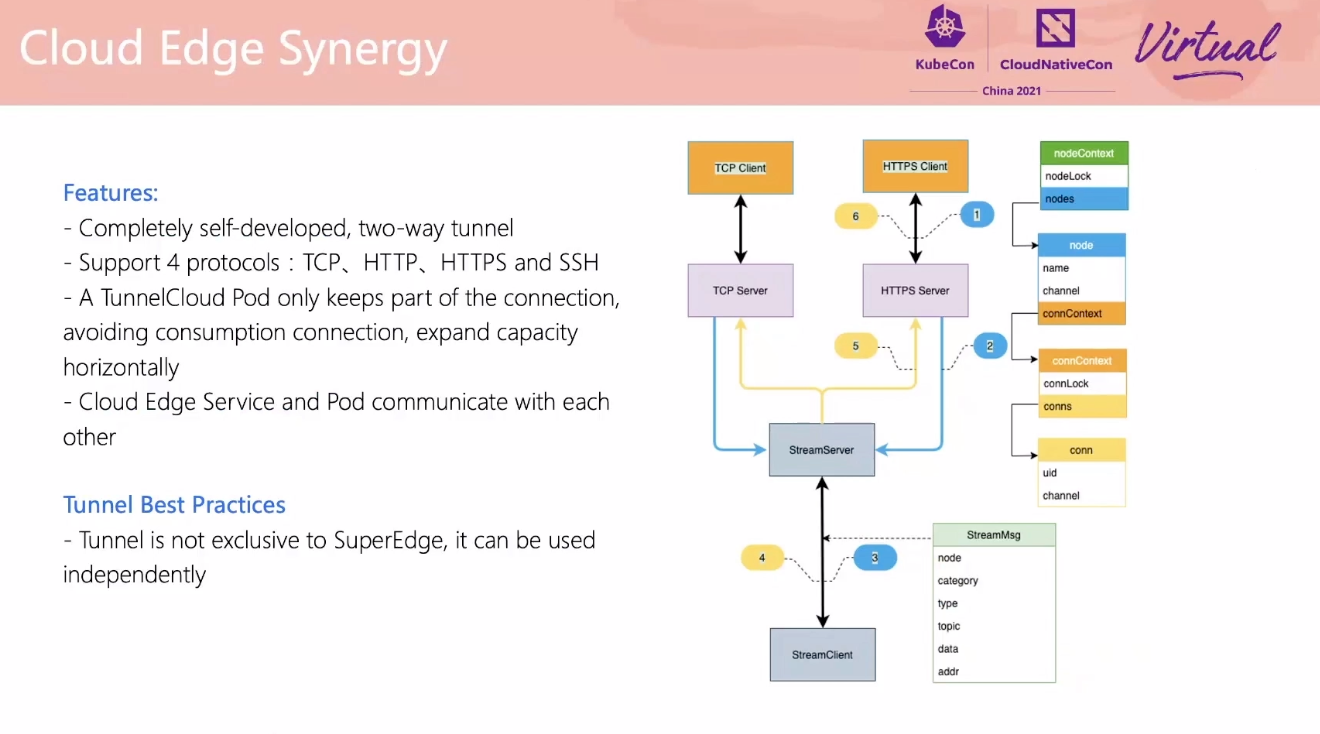
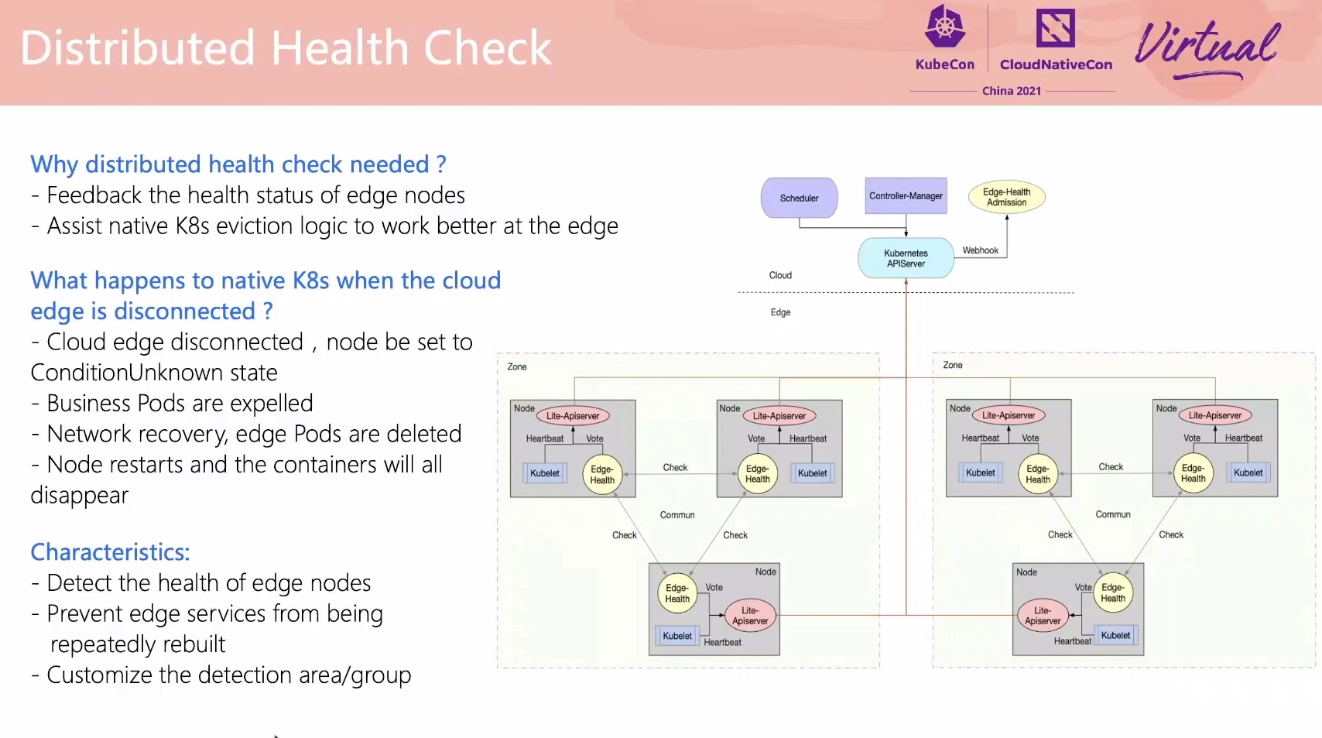
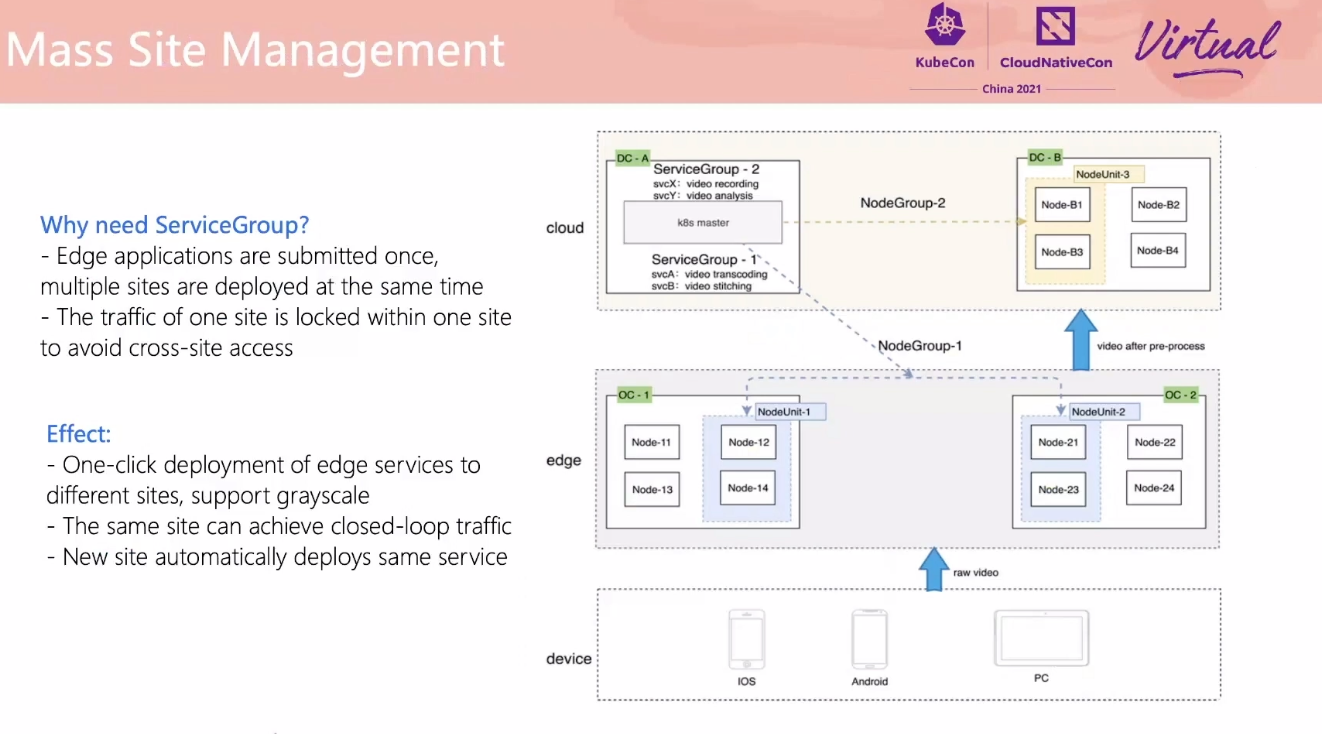
用 For 循环也能实现嘛。

云边通信还需要看一下 fabedge。
BPF Introduction, Programming Tips and Tricks
科普型 Session。




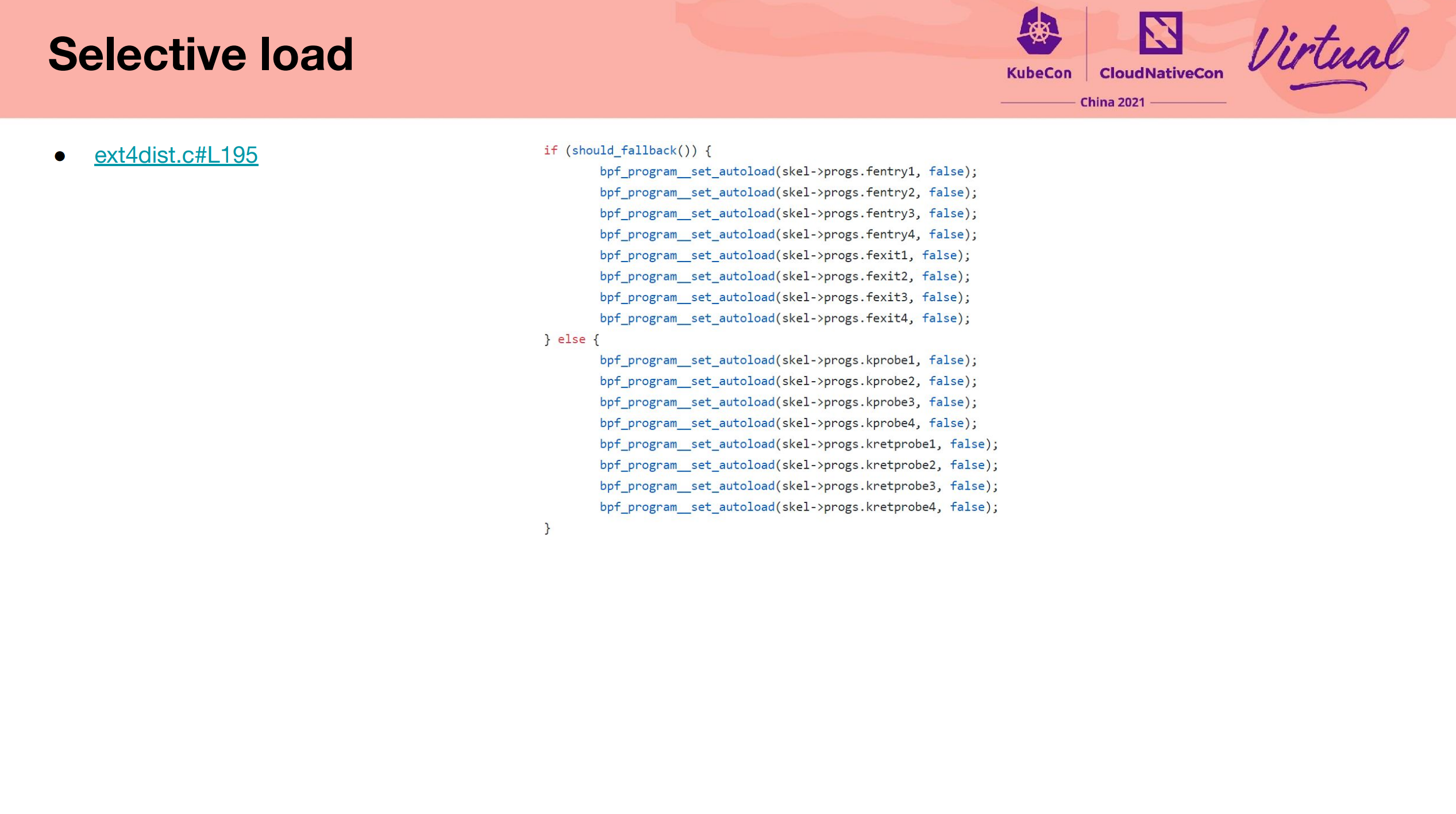



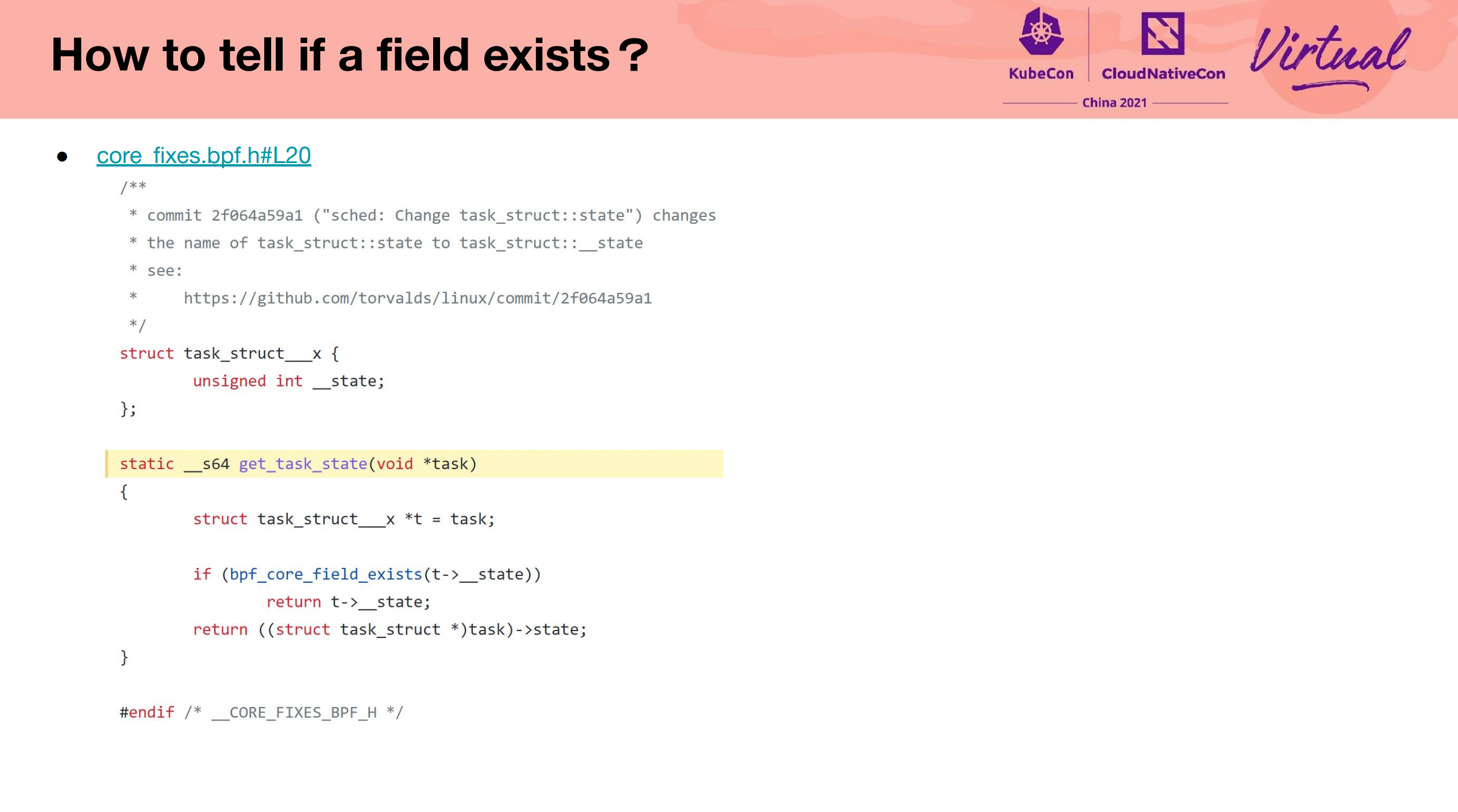





- https://nakryiko.com/posts/libbpf-bootstrap/
- https://github.com/libbpf/libbpf-bootstrap
- https://github.com/iovisor/bcc/tree/master/libbpf-tools
- https://nakryiko.com/posts/bcc-to-libbpf-howto-guide/
- https://en.pingcap.com/blog/tips-and-tricks-for-writing-linux-bpf-applications-with-libbpf
BPF 看似很火,实则用不起来的原因:
- 内核版本太低 3.10,不会升级也不敢升级内核
- 对操作系统知识很陌生,hold 不住,只能用用现成的 BCC 之类的工具,或许也不用
Monitor mesh for edge clusters
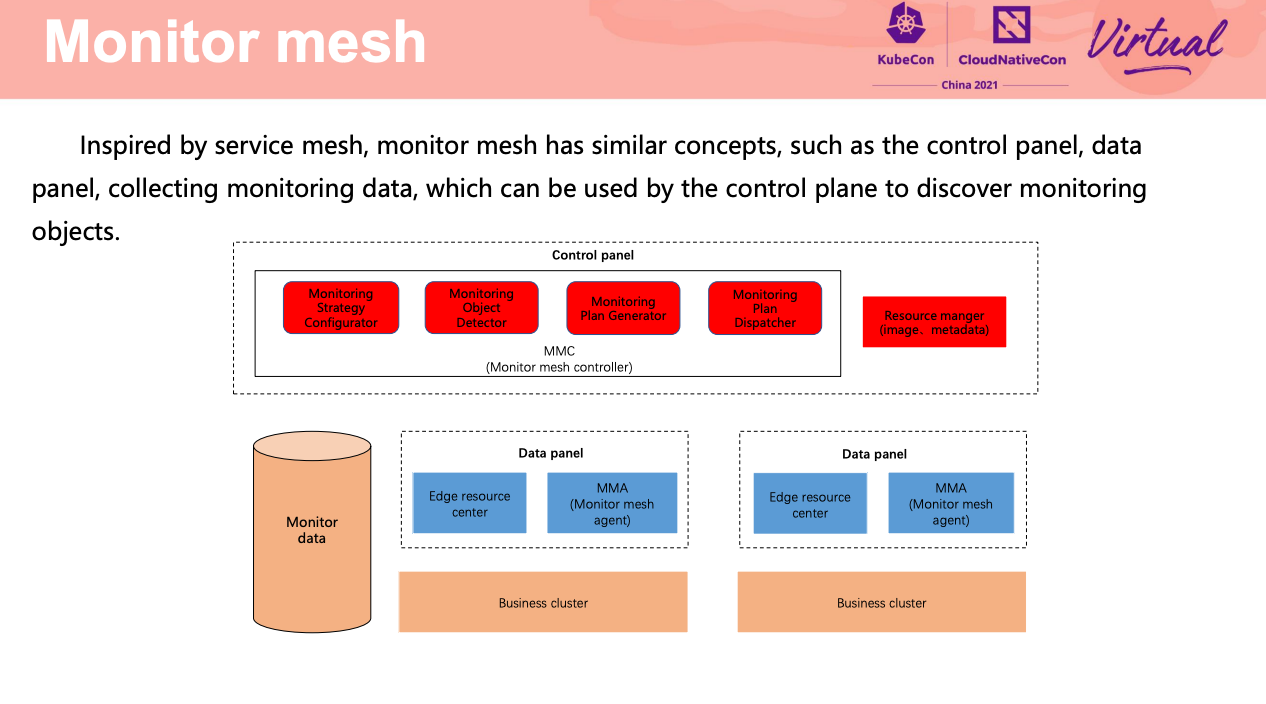
思路不错,应该也适用于用户自定义/多集群/多云/混合云场景。
Data panel 相当于做了 sharding。
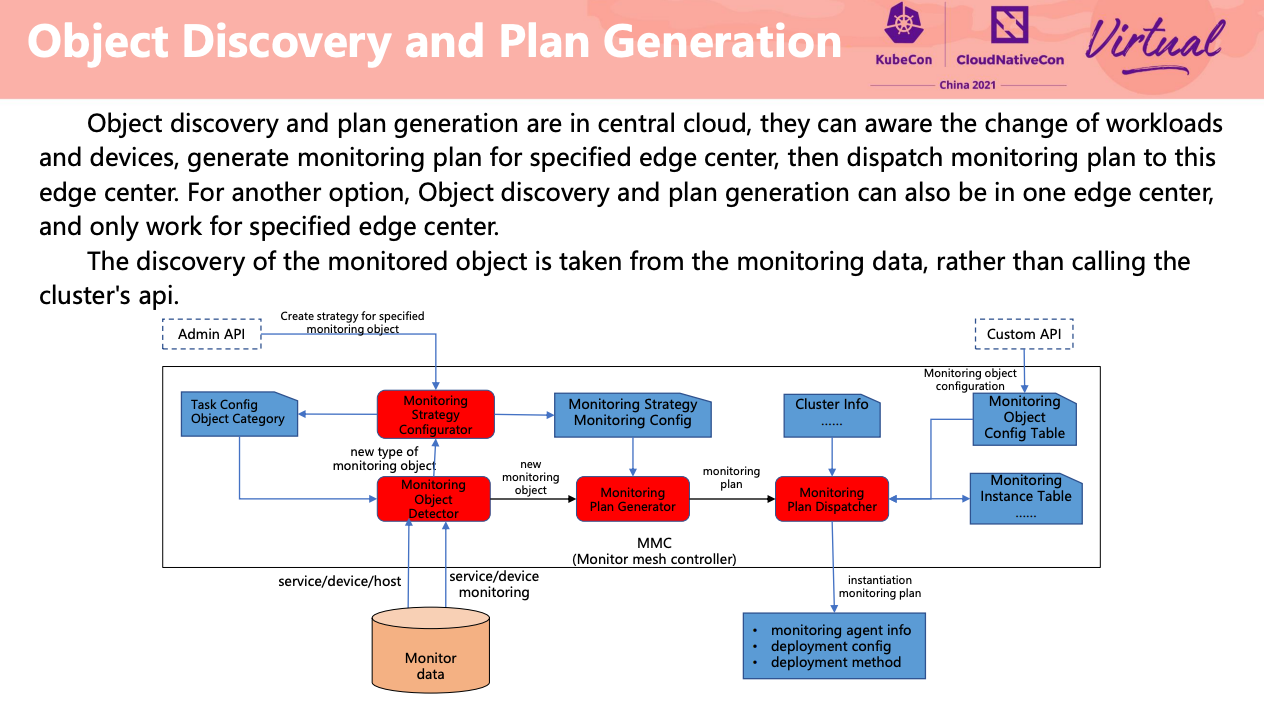
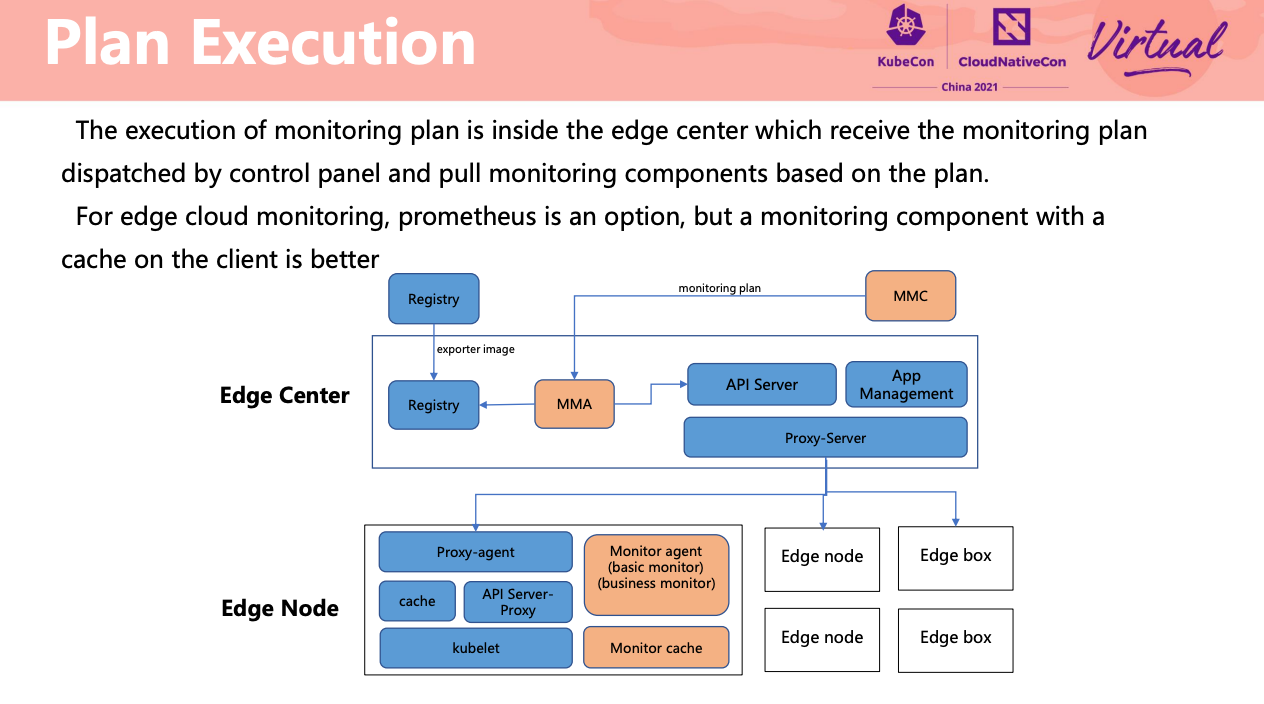
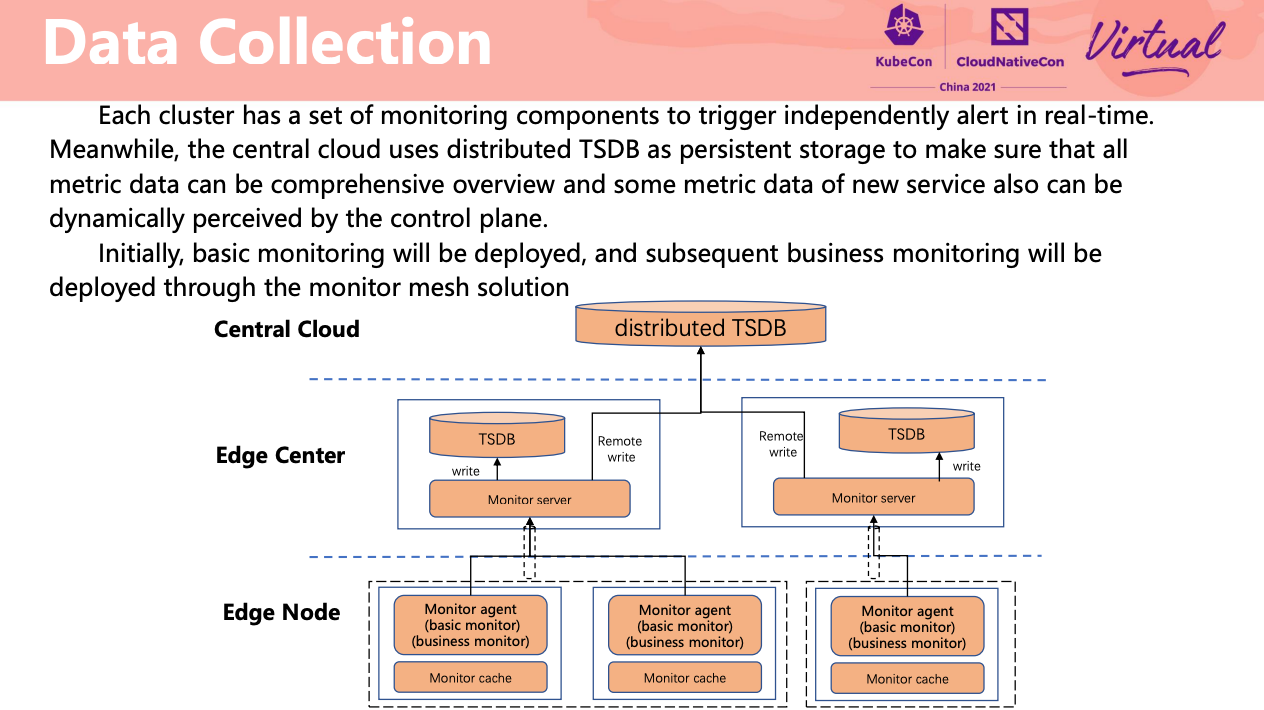
监控数据双写。
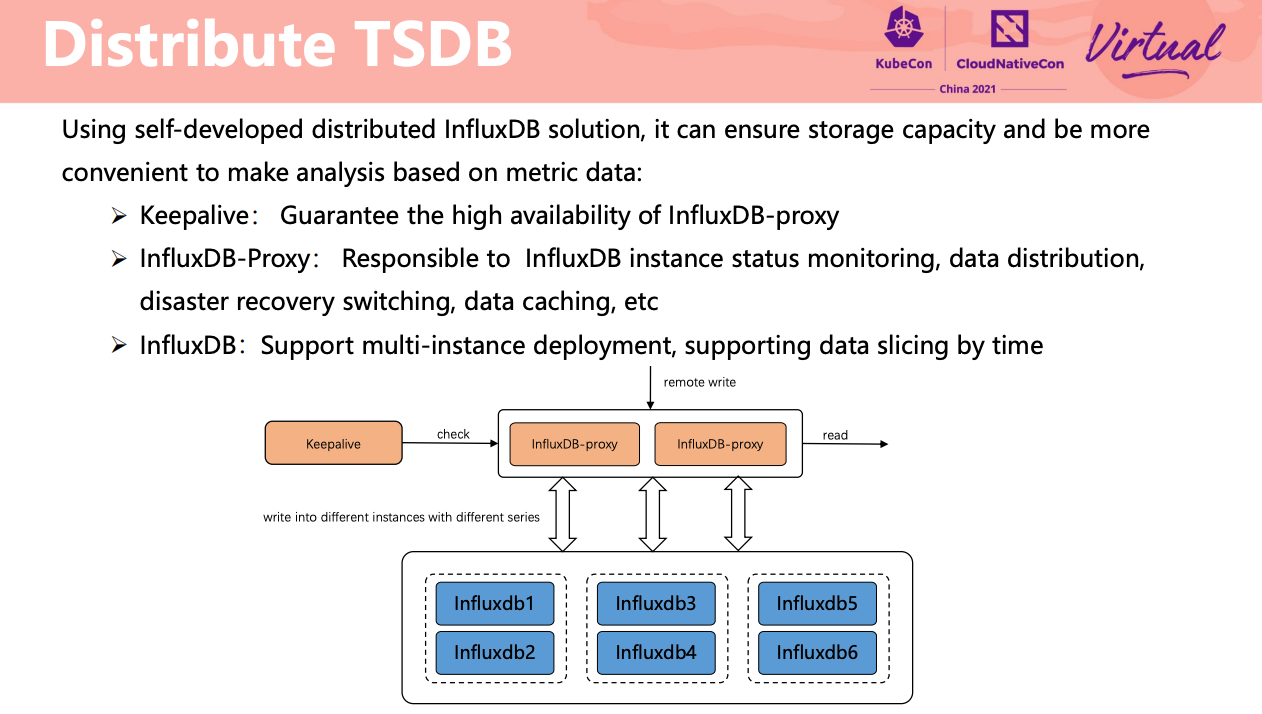
InfluxDB 主备 + 分片。
十个分布式时序数据库,七个用 InfluxDB,两个用 TDengine,还有一个用 Apache IoTDB。
Keep Persistent Volumes Healthy for Stateful Workloads
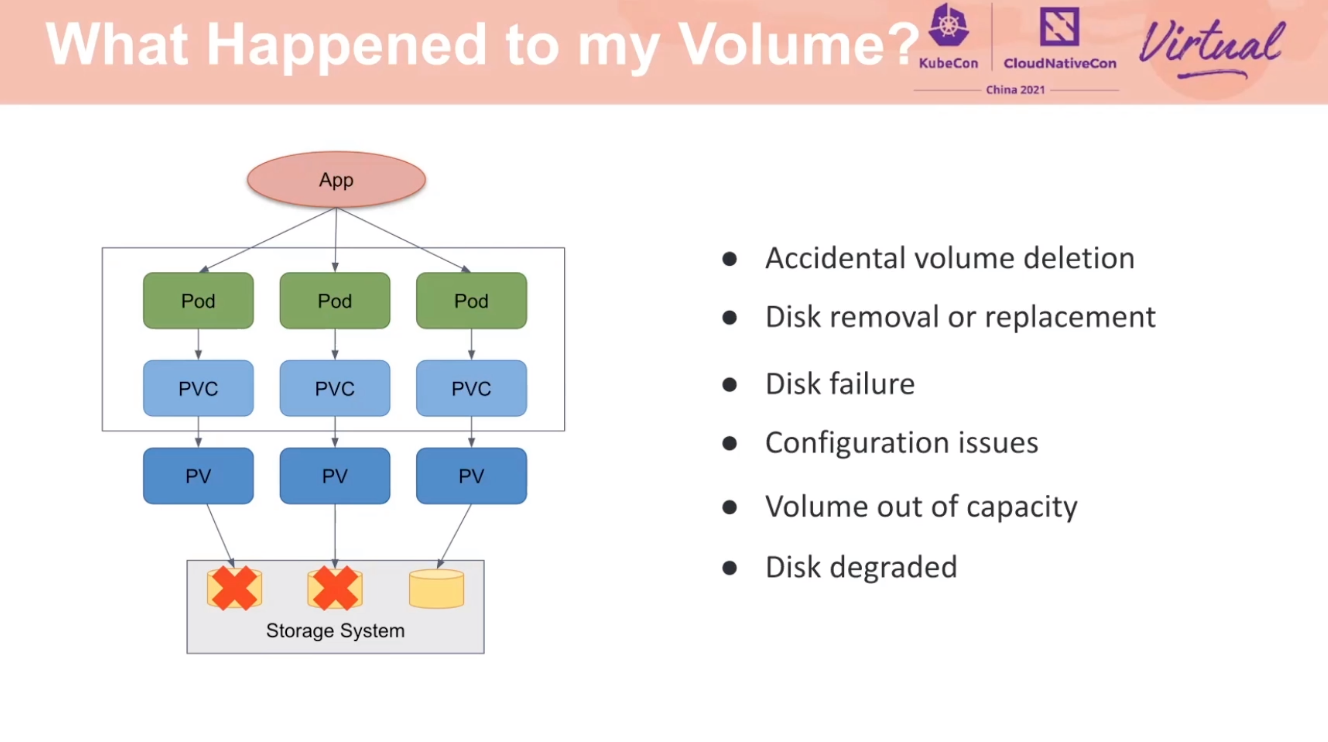
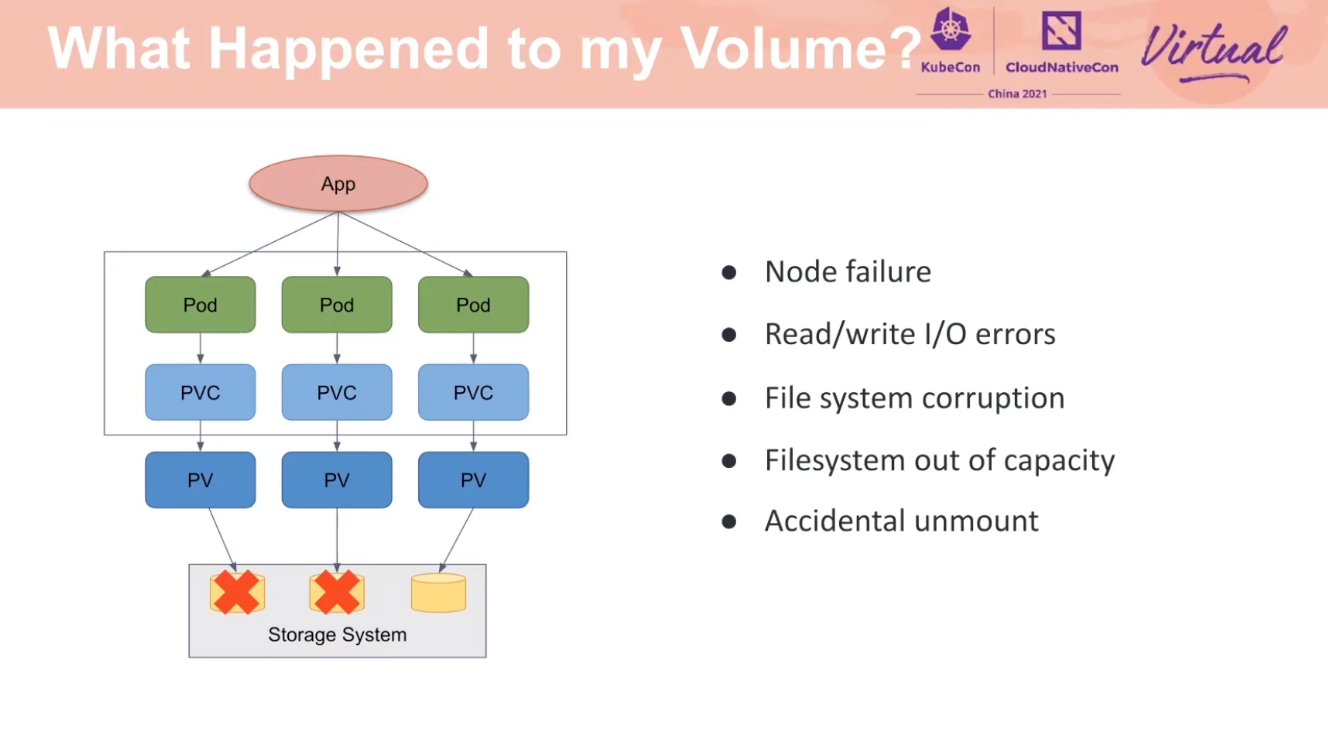

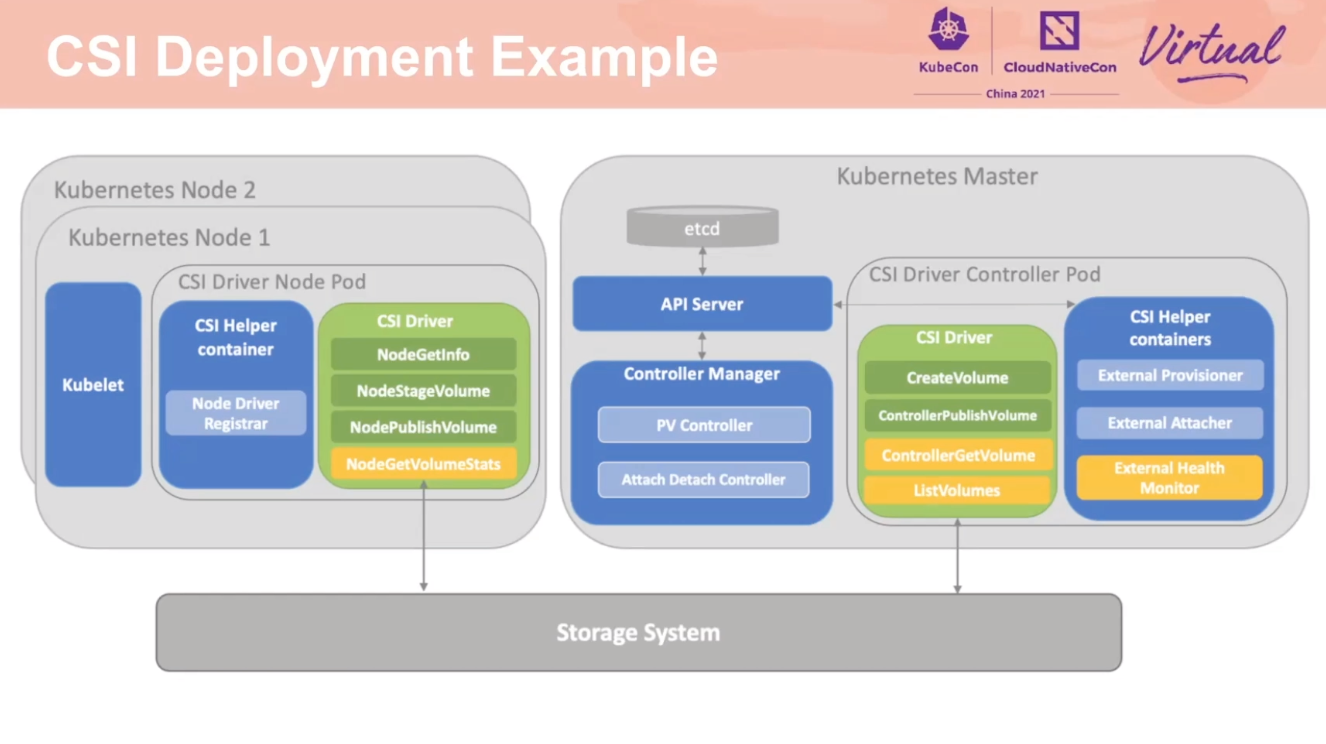




权限控制和操作滞后还是有必要的。
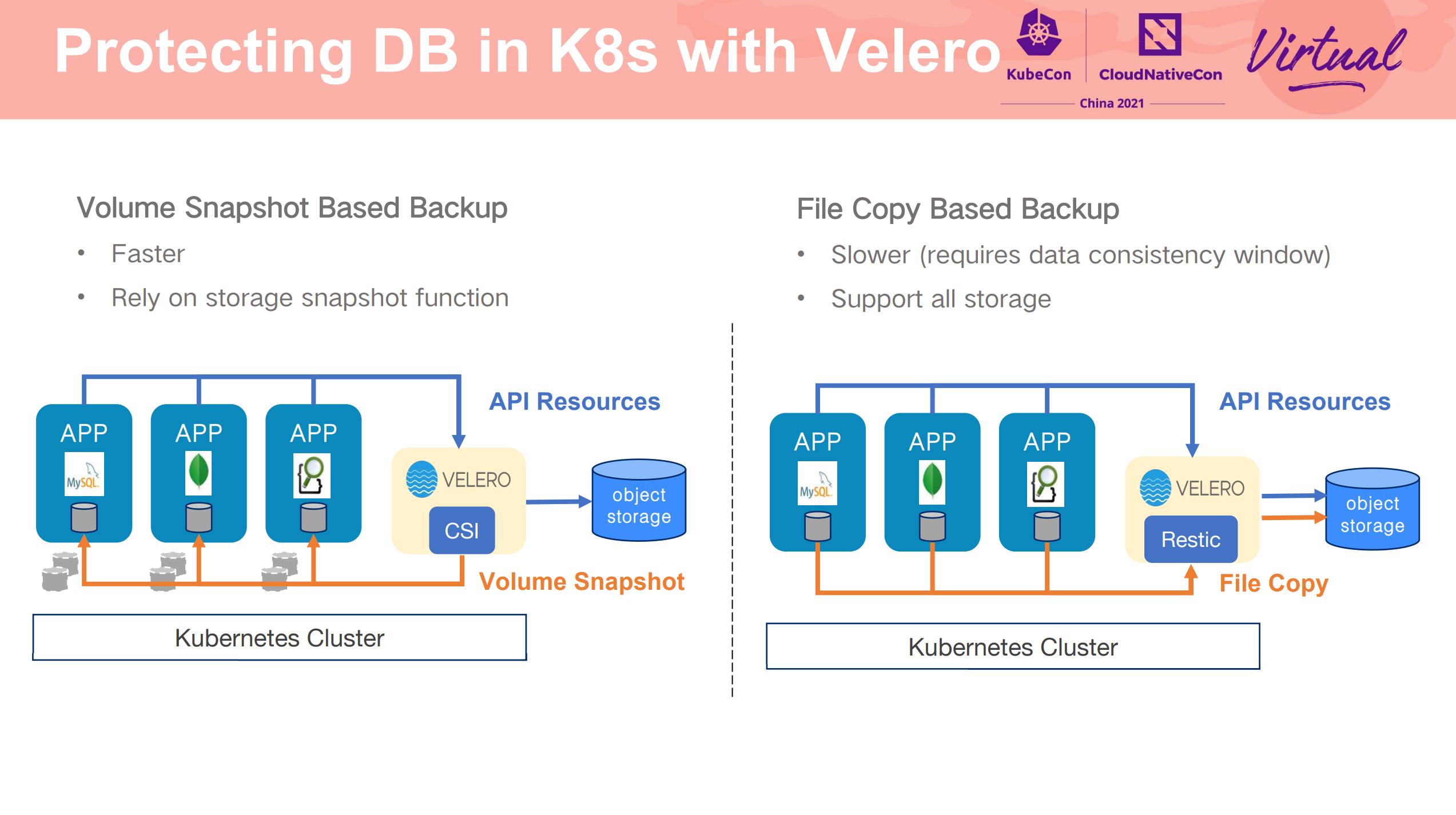
数据及时备份。 不过 Velero 能做的很有限。
CSI Driver 平滑重启/升级也是个问题。
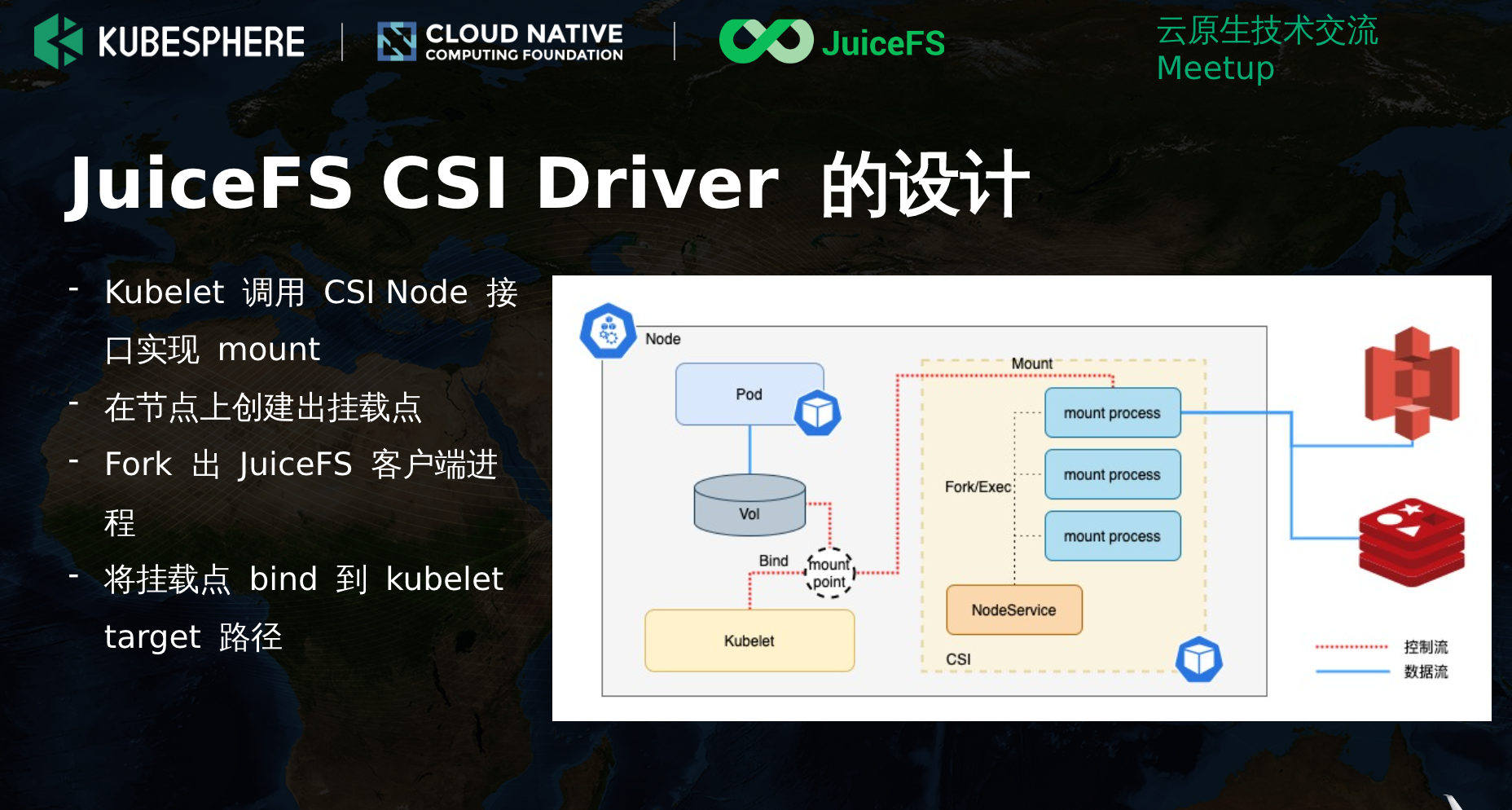

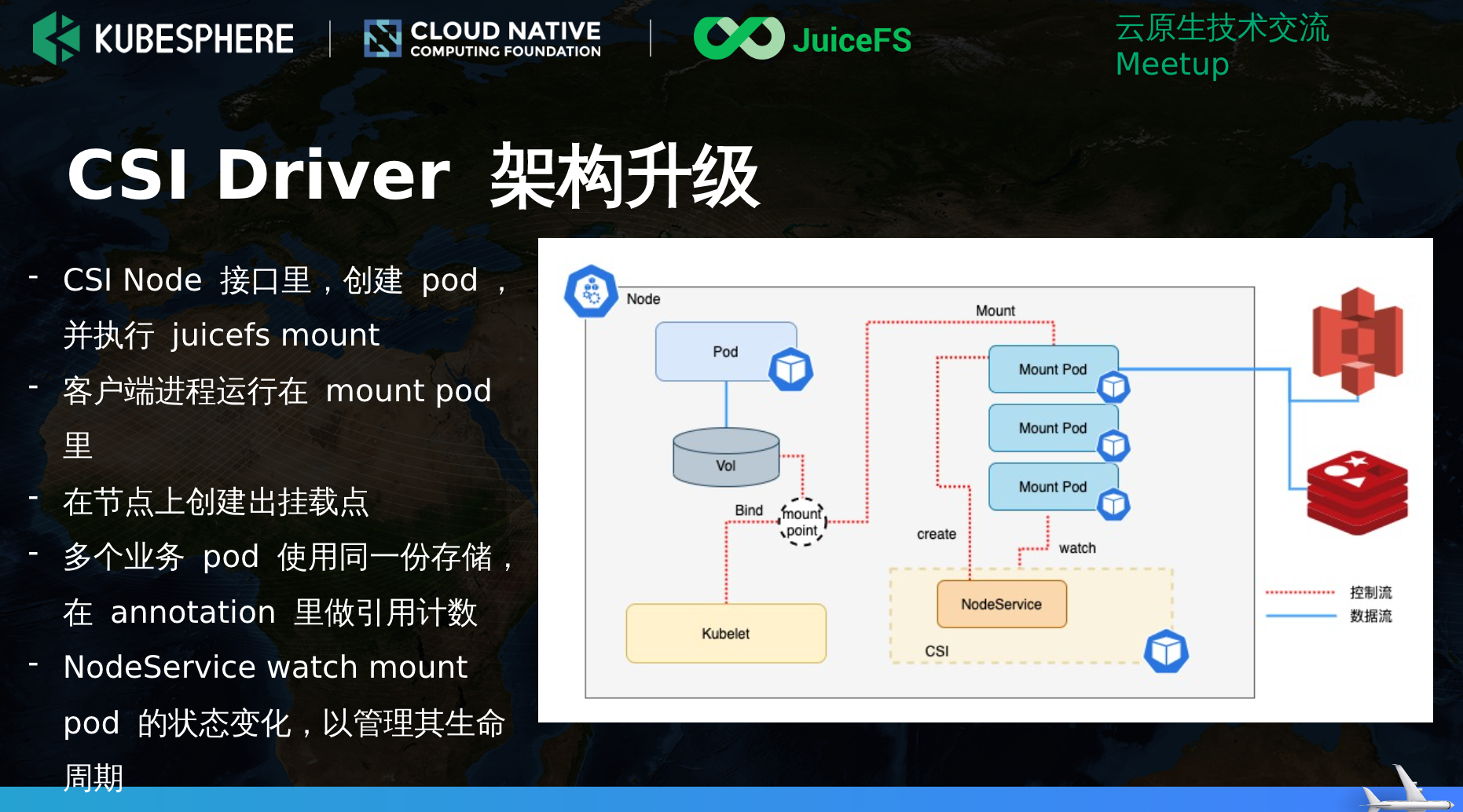
但这种对客户端要求有很高,好多客户端实现上不是那么优雅。
上述图片来自: https://yunify.anybox.qingcloud.com/s/VkmOPXFNFVjMdhbfvbTfDjk1AZuwqXqO?type=file&id=4312918
Effective Data Access In Kubernetes for Data-Intelligence Application
Fluid,没有什么好说的,用就对了。
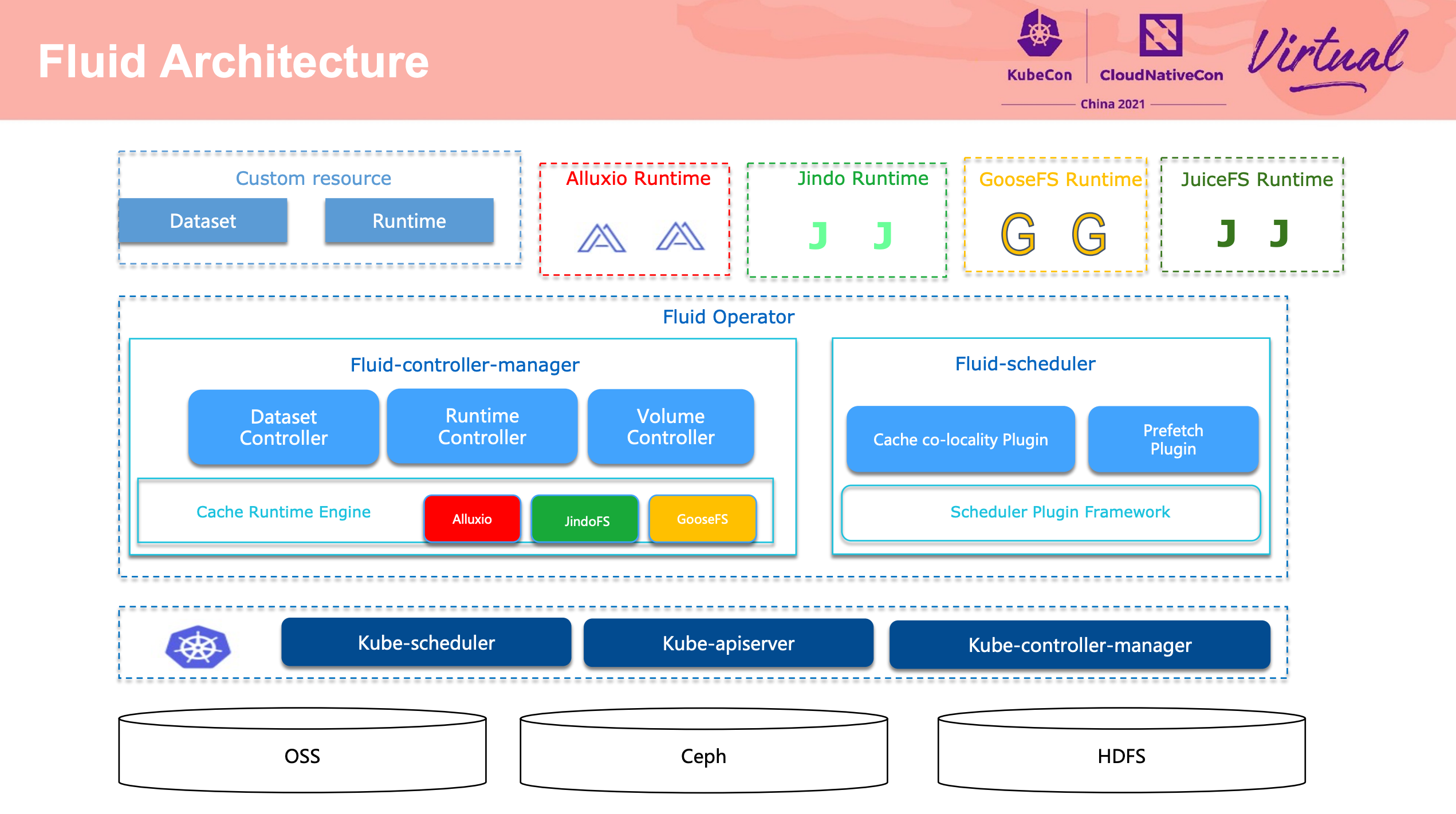
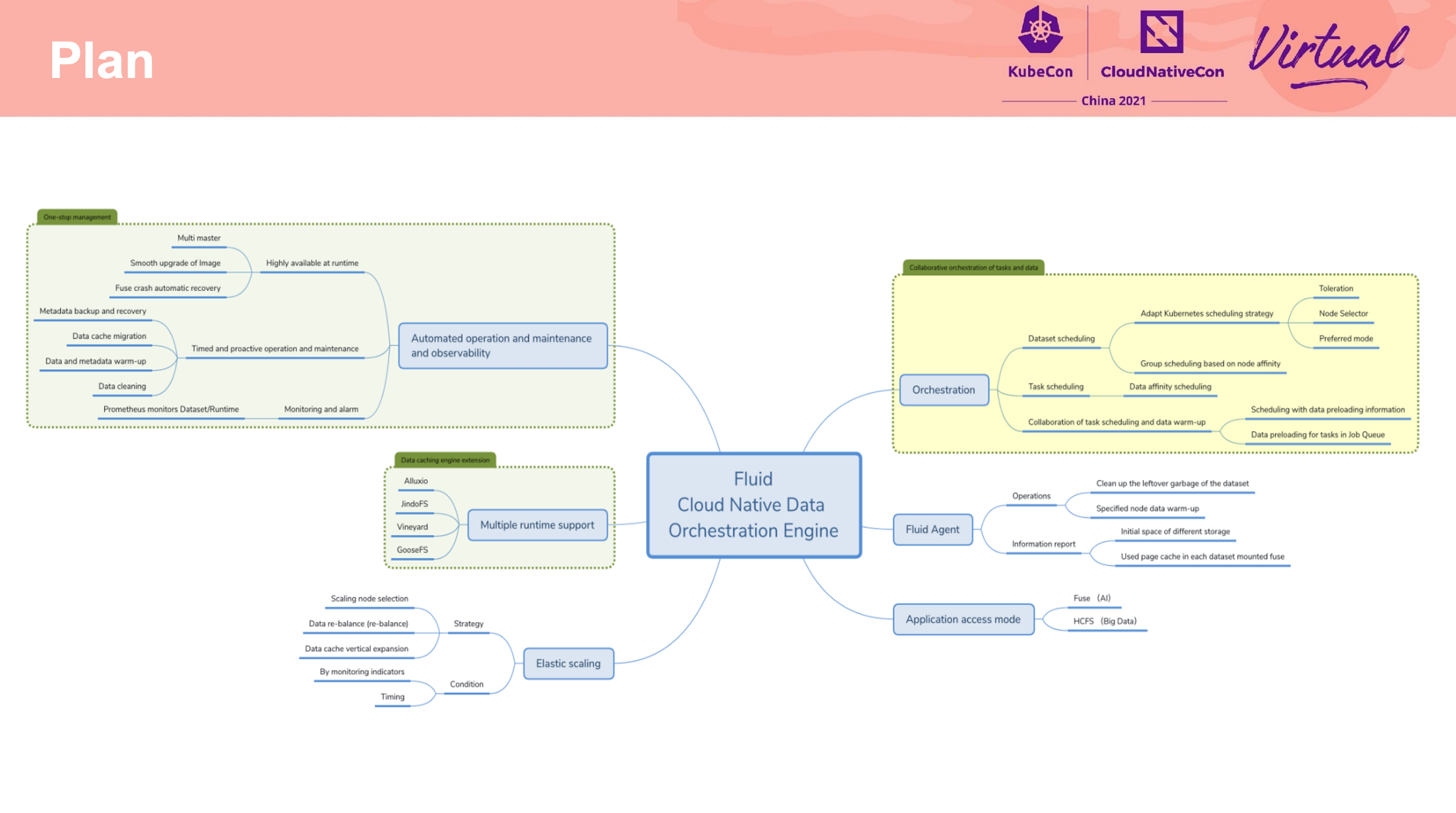
期待 Fluid 能支持更多的 Runtime,为更多的数据调度场景服务。
Intro and Deep Dive into ChubaoFS
ChubaoFS 还是很好用的。
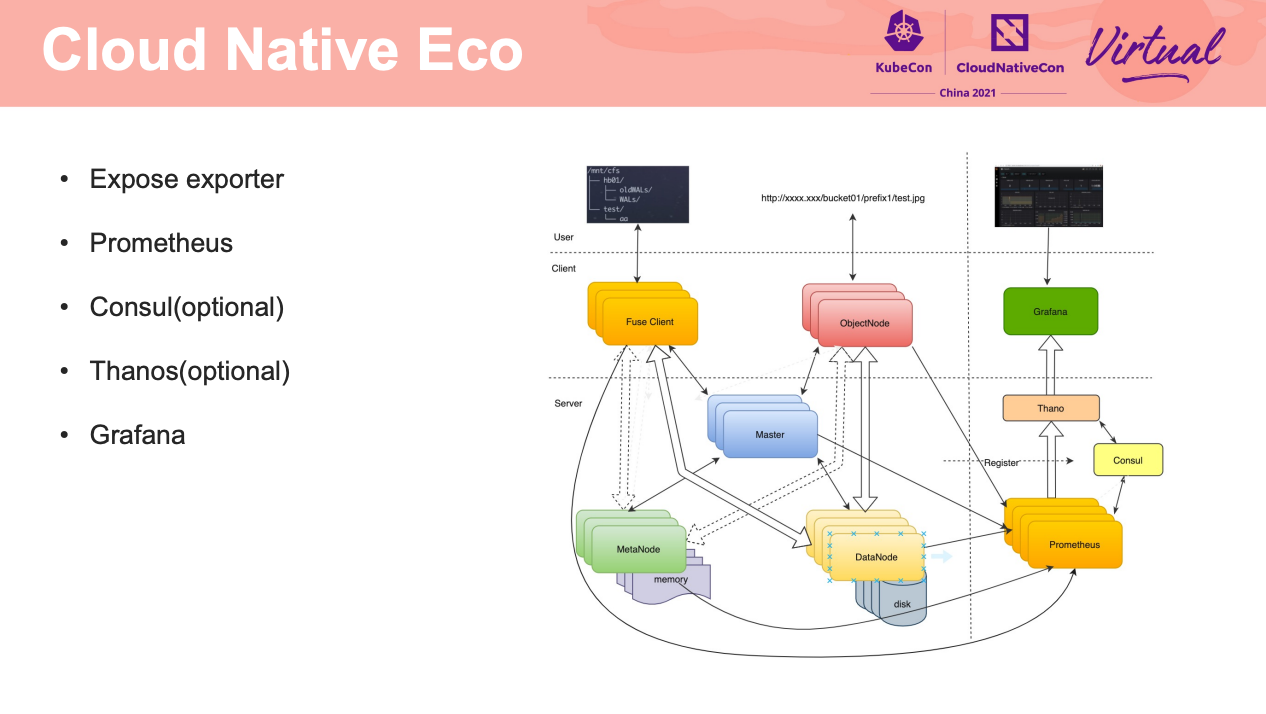


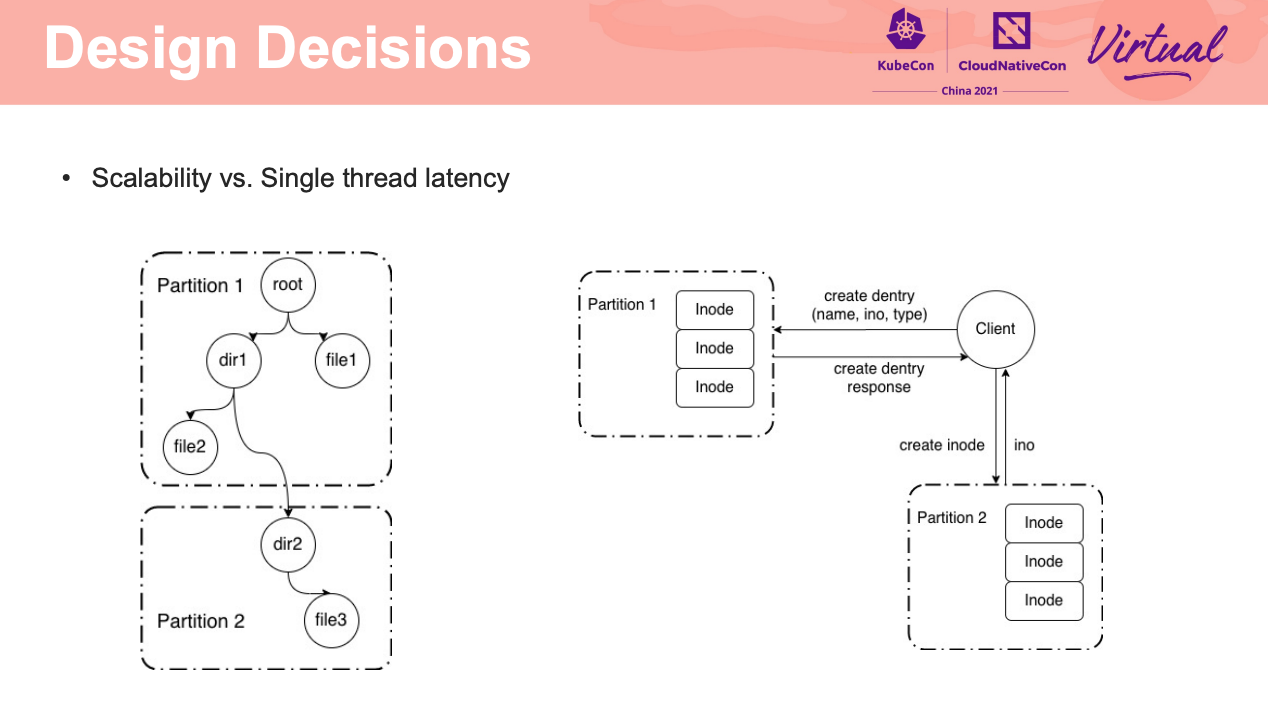
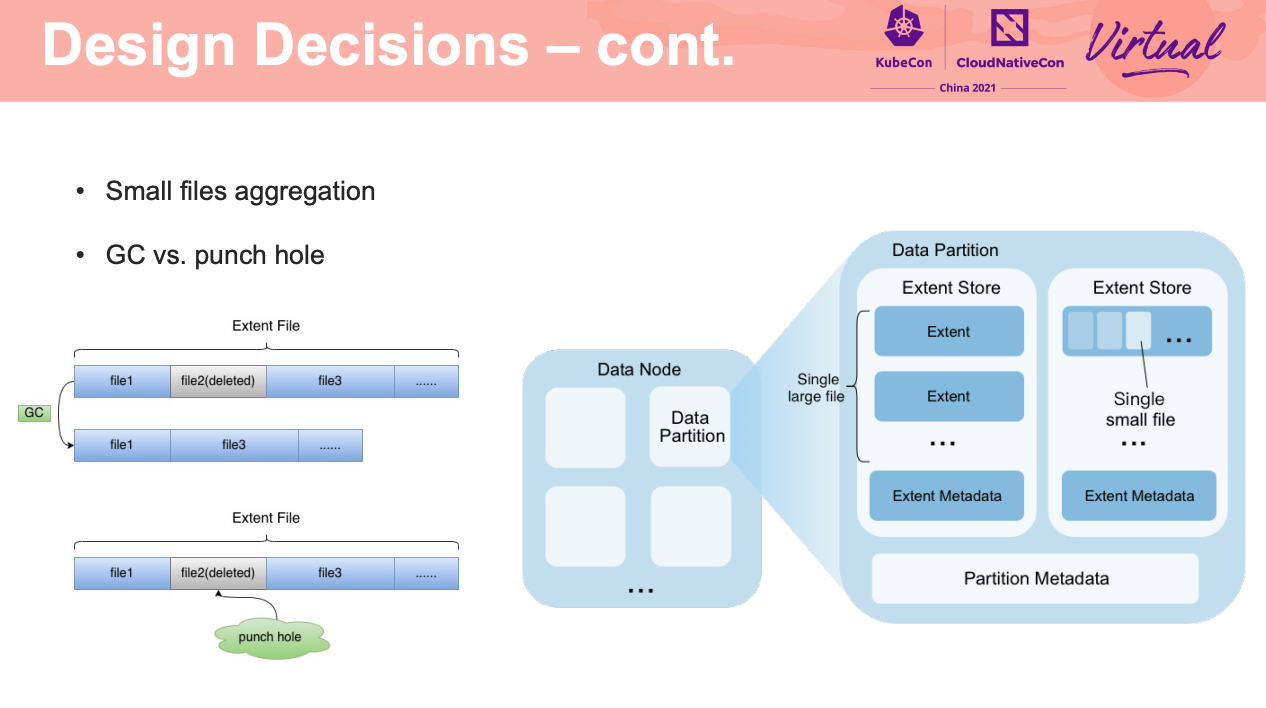

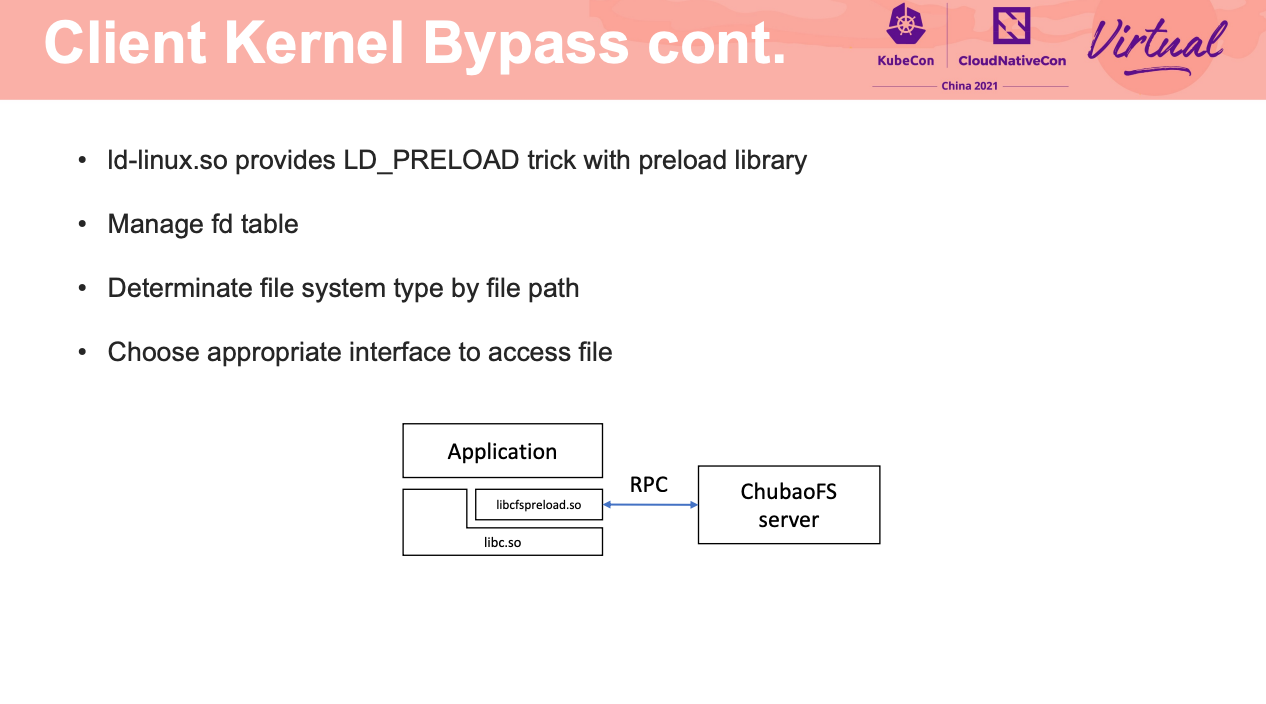
如何让 FUSE 在容器环境下跑的又稳又好,应该是 FS 都是亟需解决的吧。
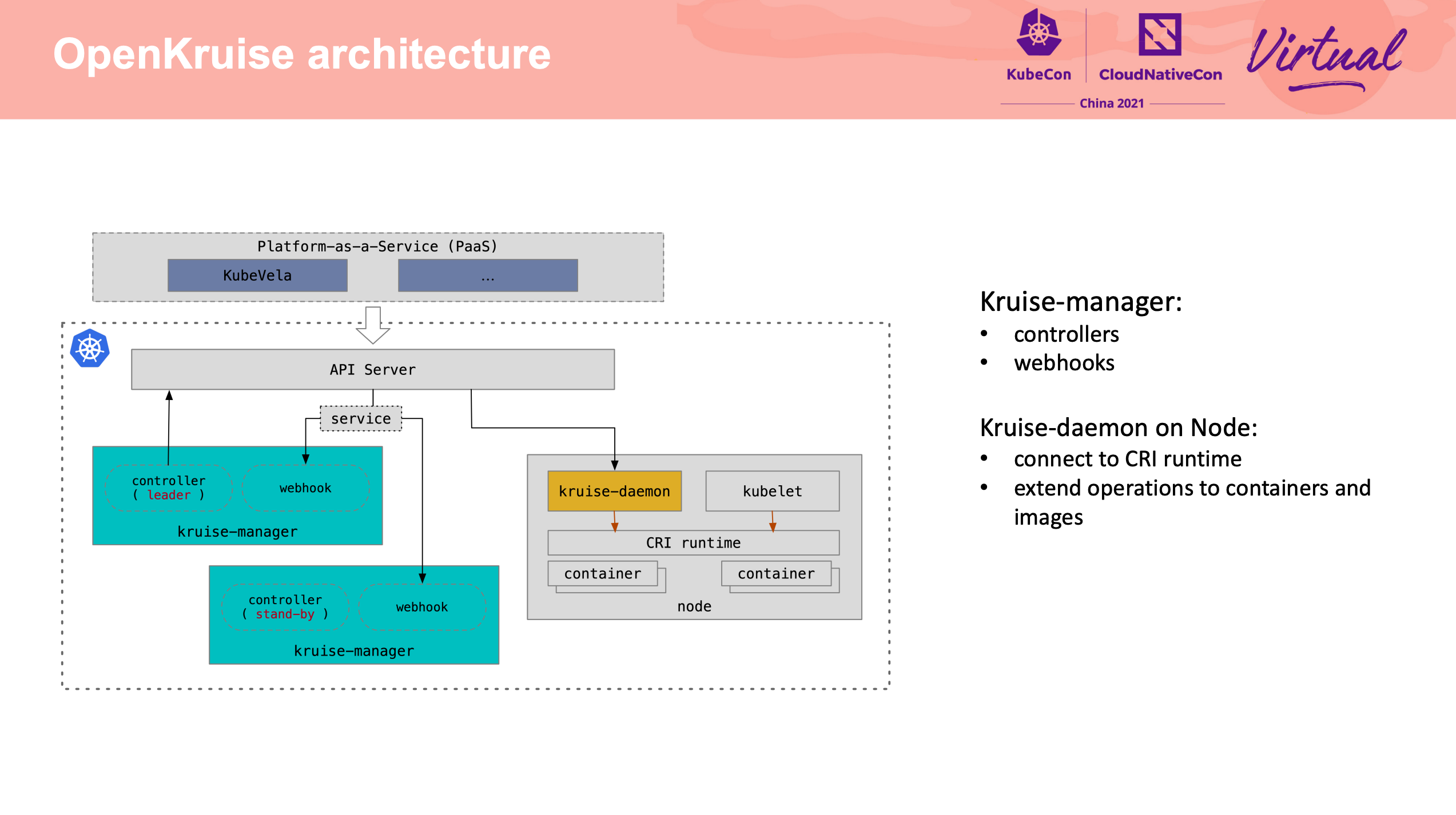
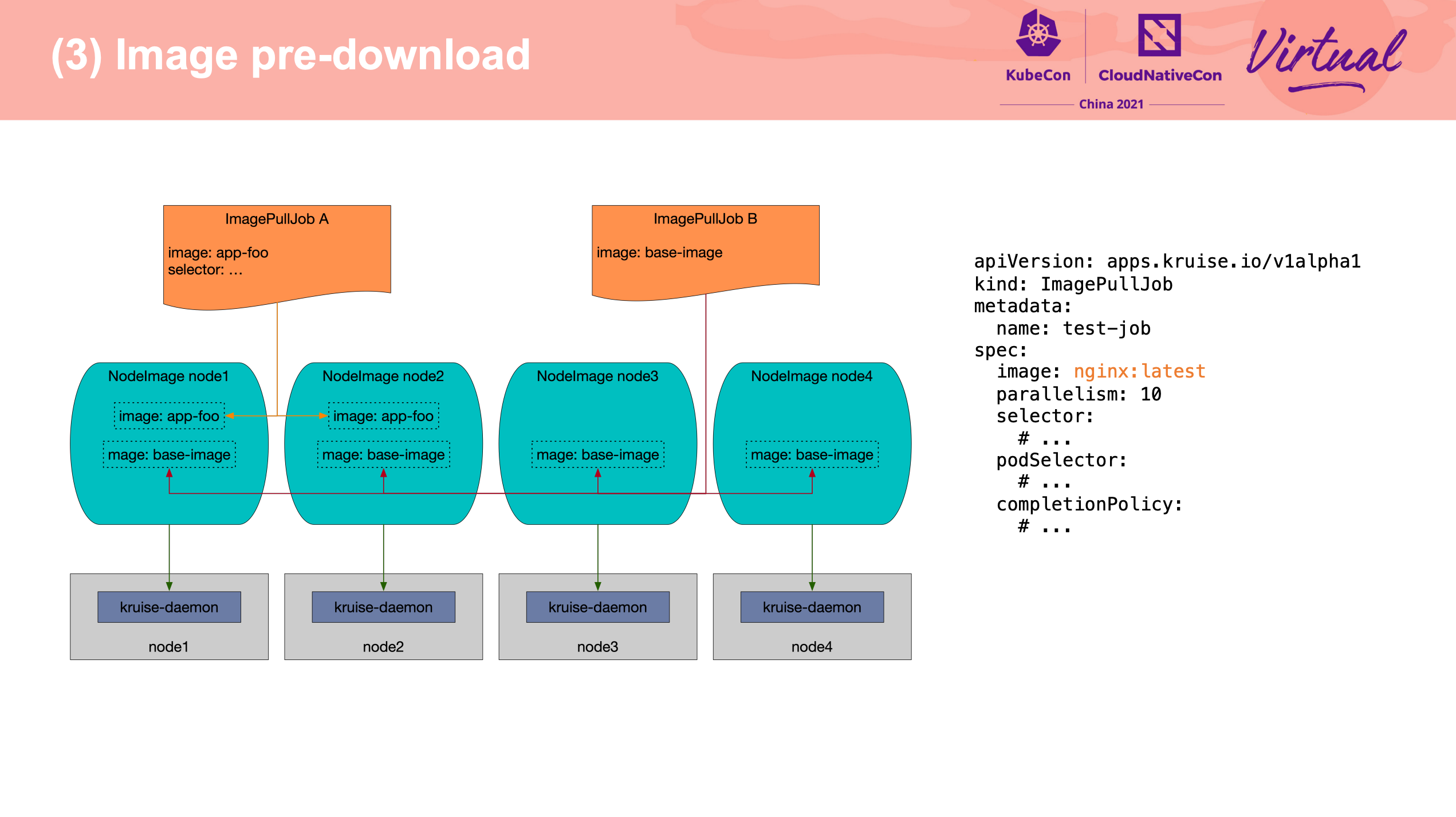
Extend the operations for container runtime in OpenKruise
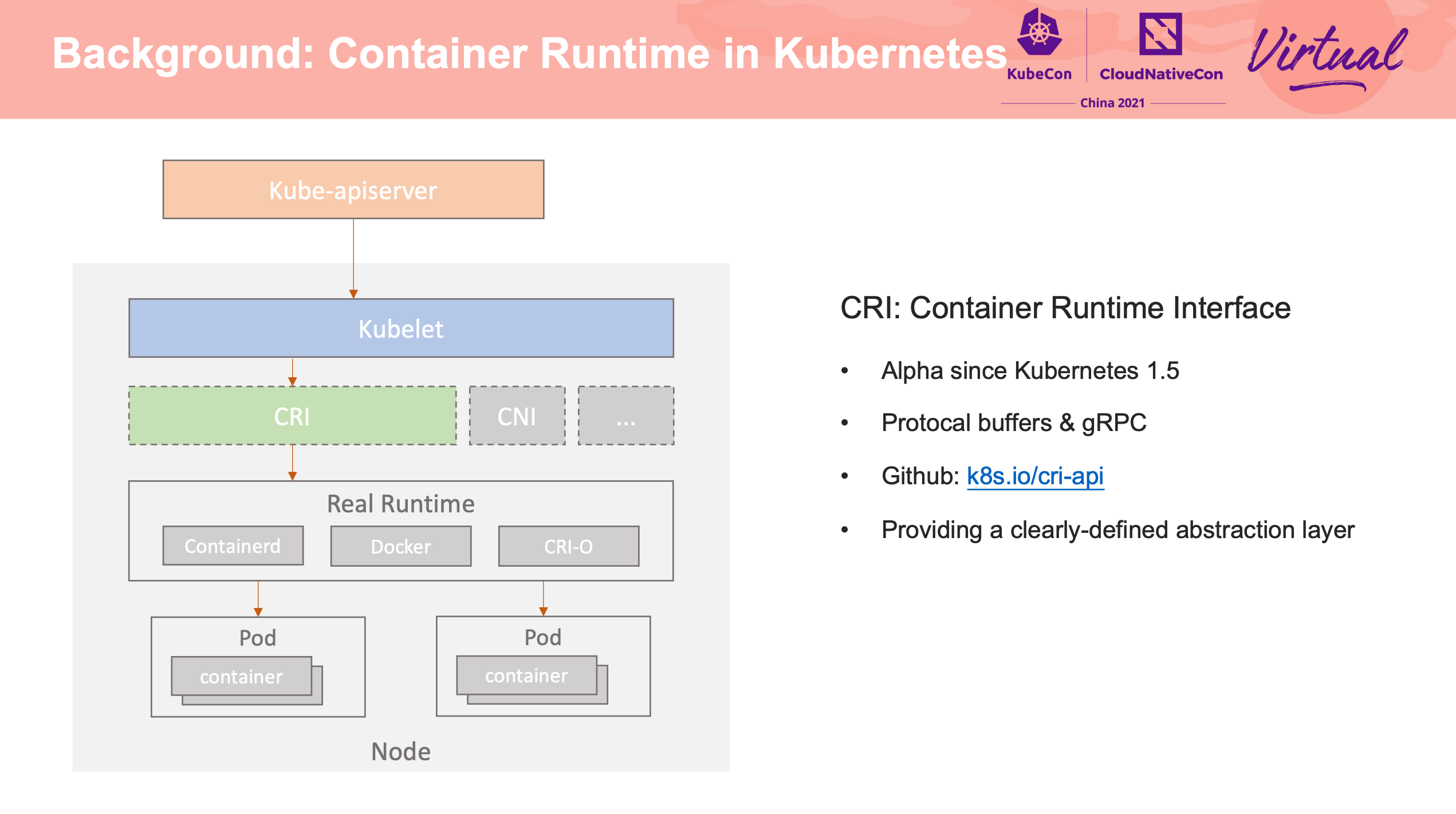
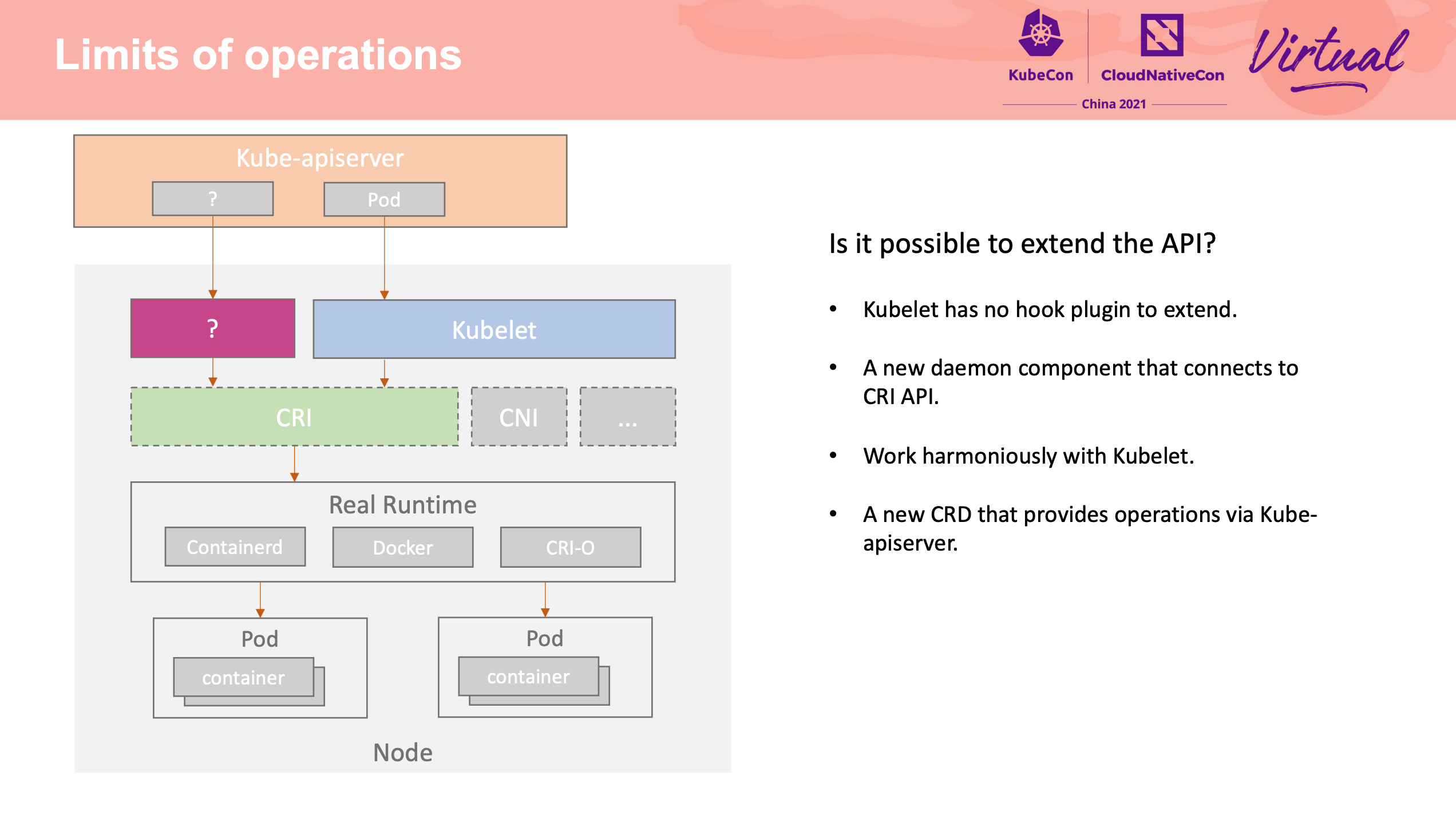
尽在 Kruise-daemon。
不过感觉 Kubelet 真的需要插件机制。

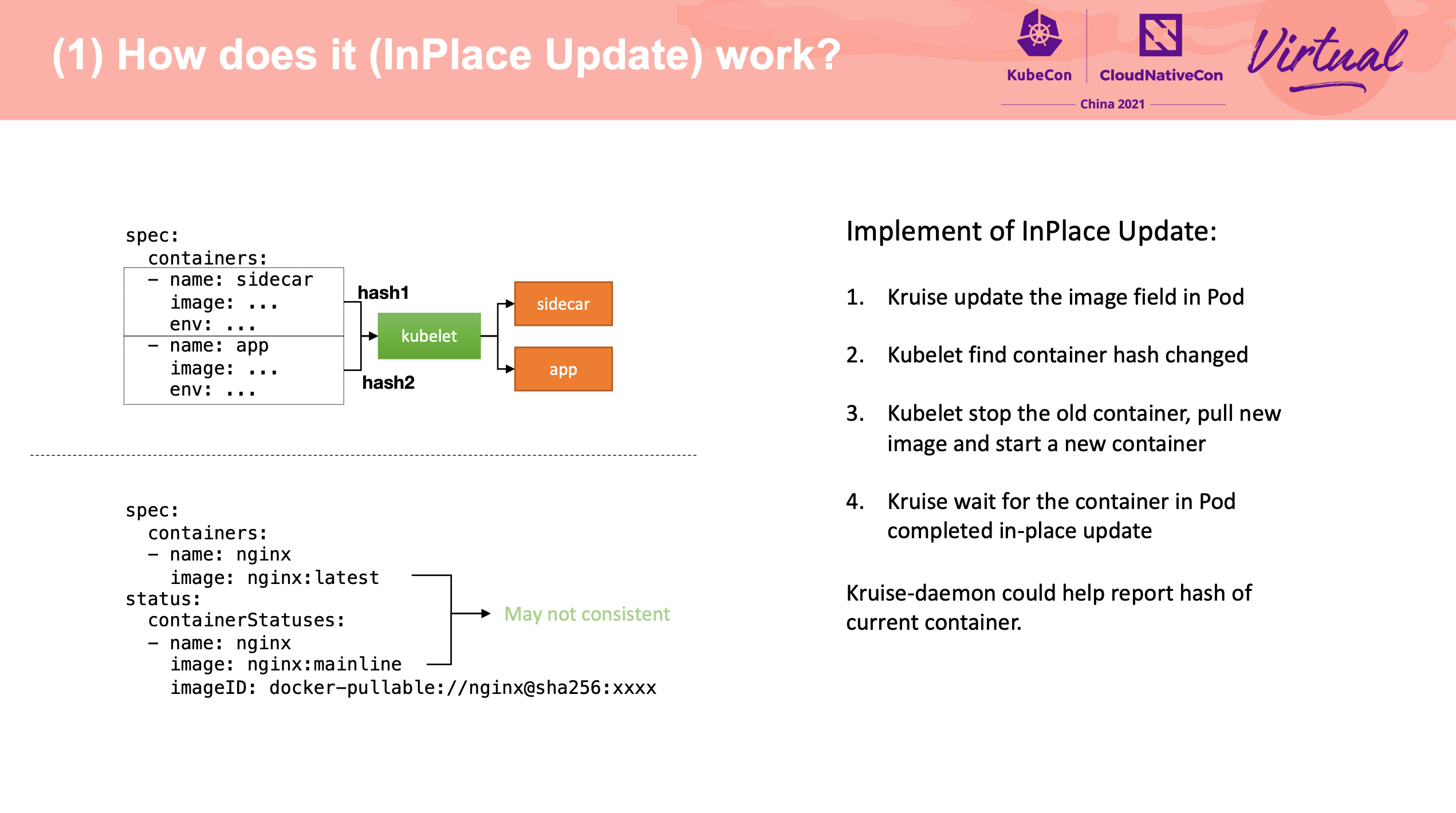
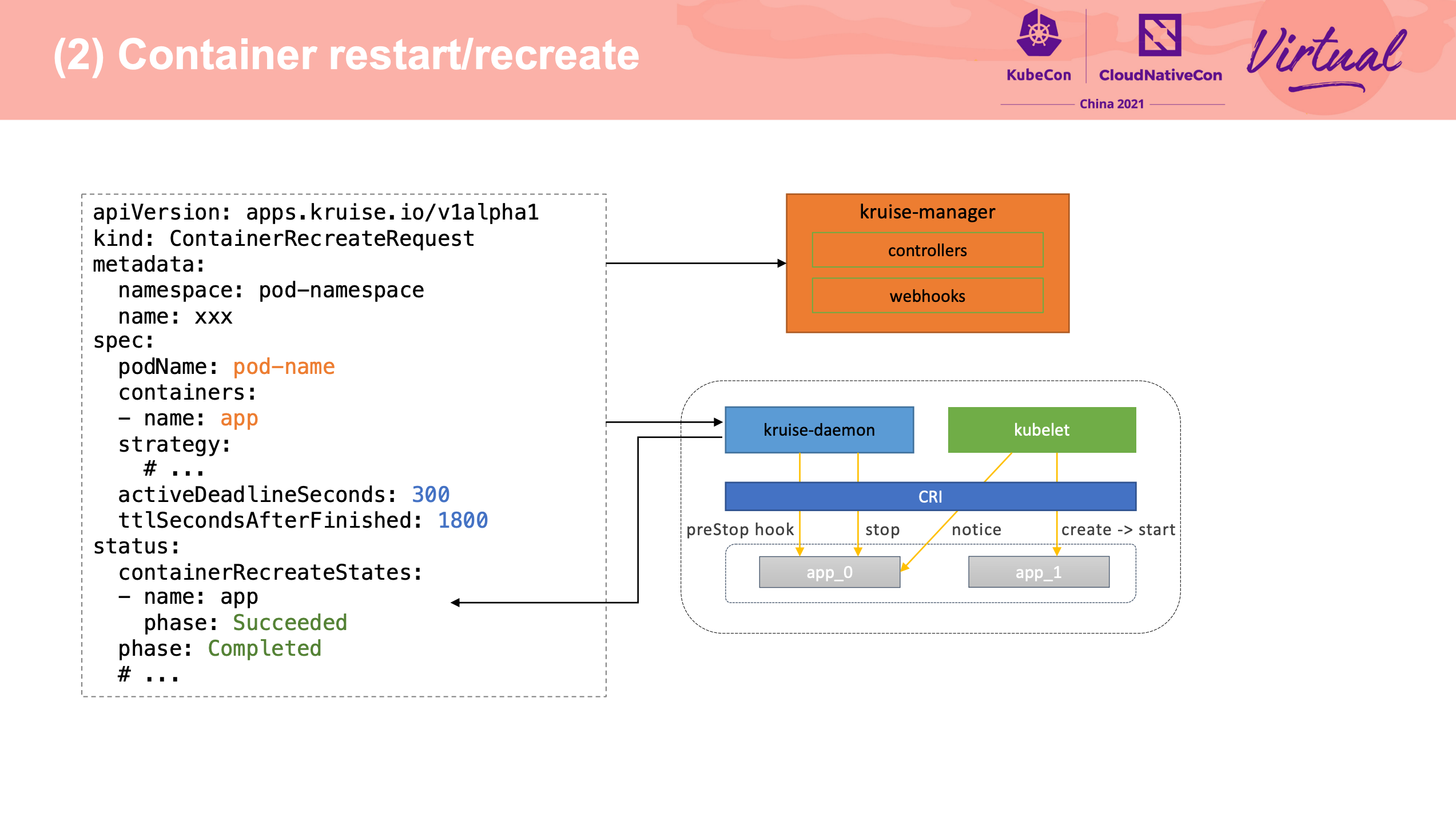
原地升级也是老牌需求了。
可以配合官方文档一起看: https://openkruise.io/zh/docs/core-concepts/inplace-update/
Protect your database workloads in K8s
Velero 相关的 Session。

应用的数据一致性,还是需要依赖应用自身啊。
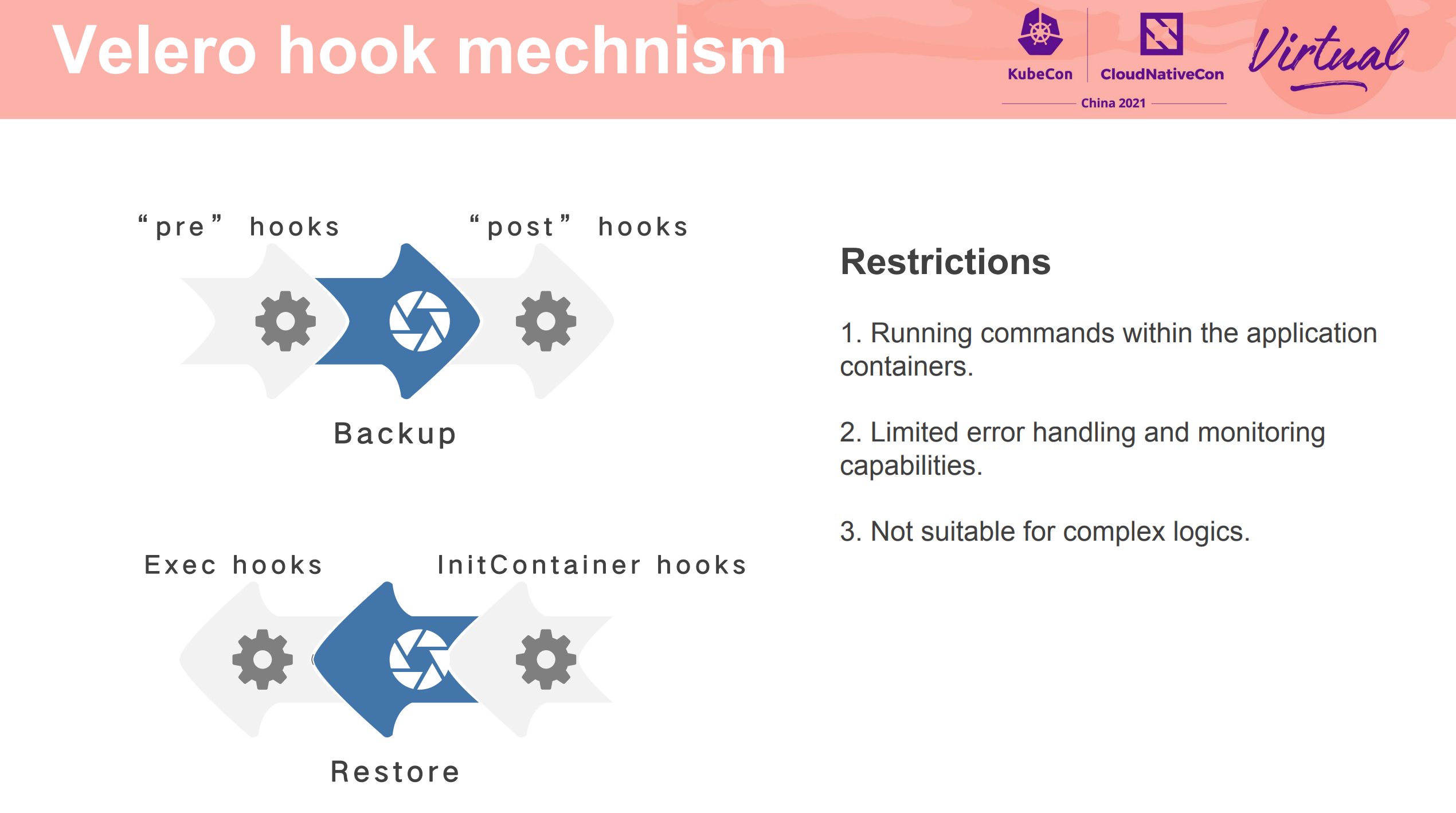
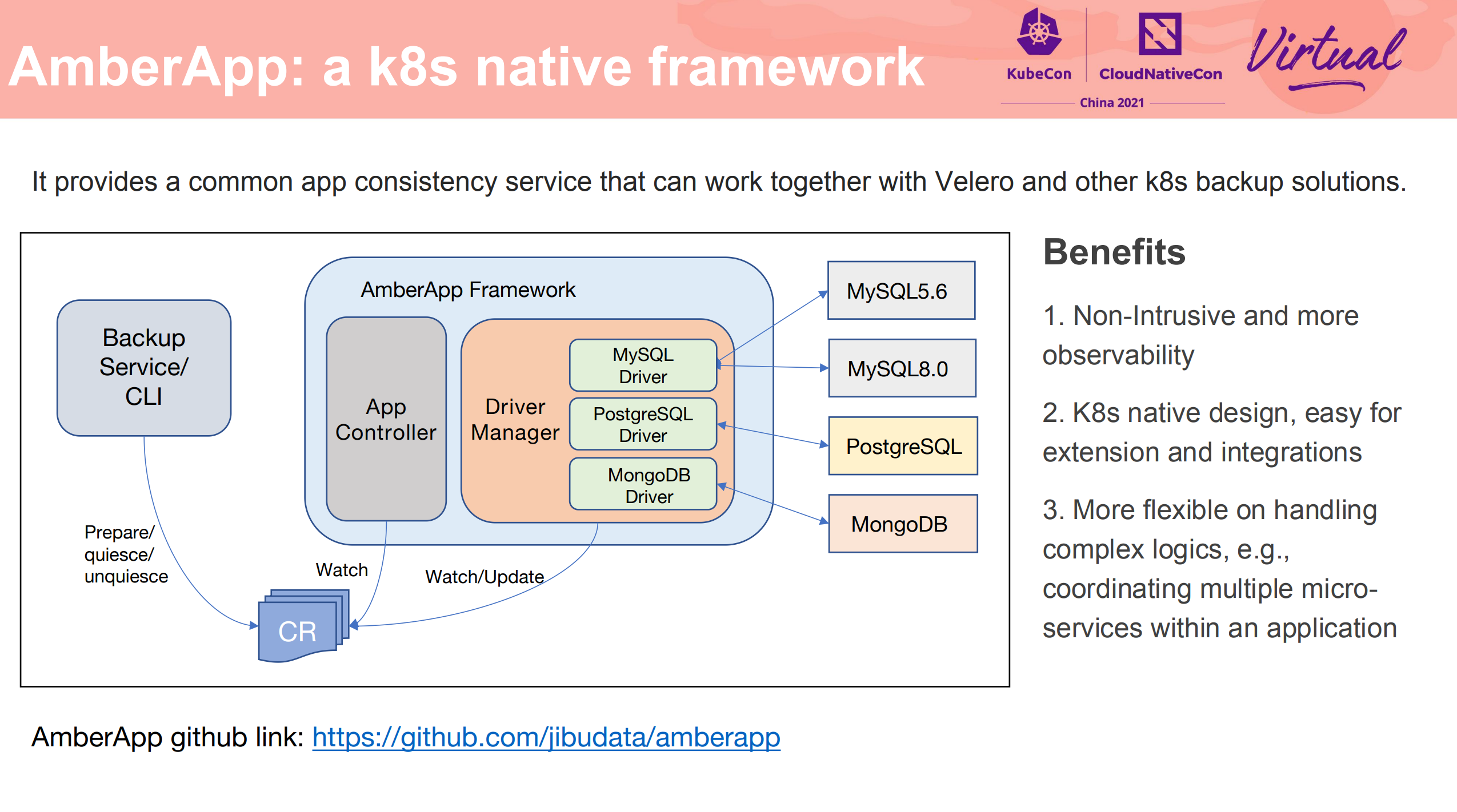
Amberapp 主要是为了解决 Velero hook 的局限性。
项目已经开源: https://github.com/jibudata/amberapp
现阶段支持:
- PostgreSQL
- MongoDB
- MySQL
ML training acceleration with heterogeneous resources in ByteDance

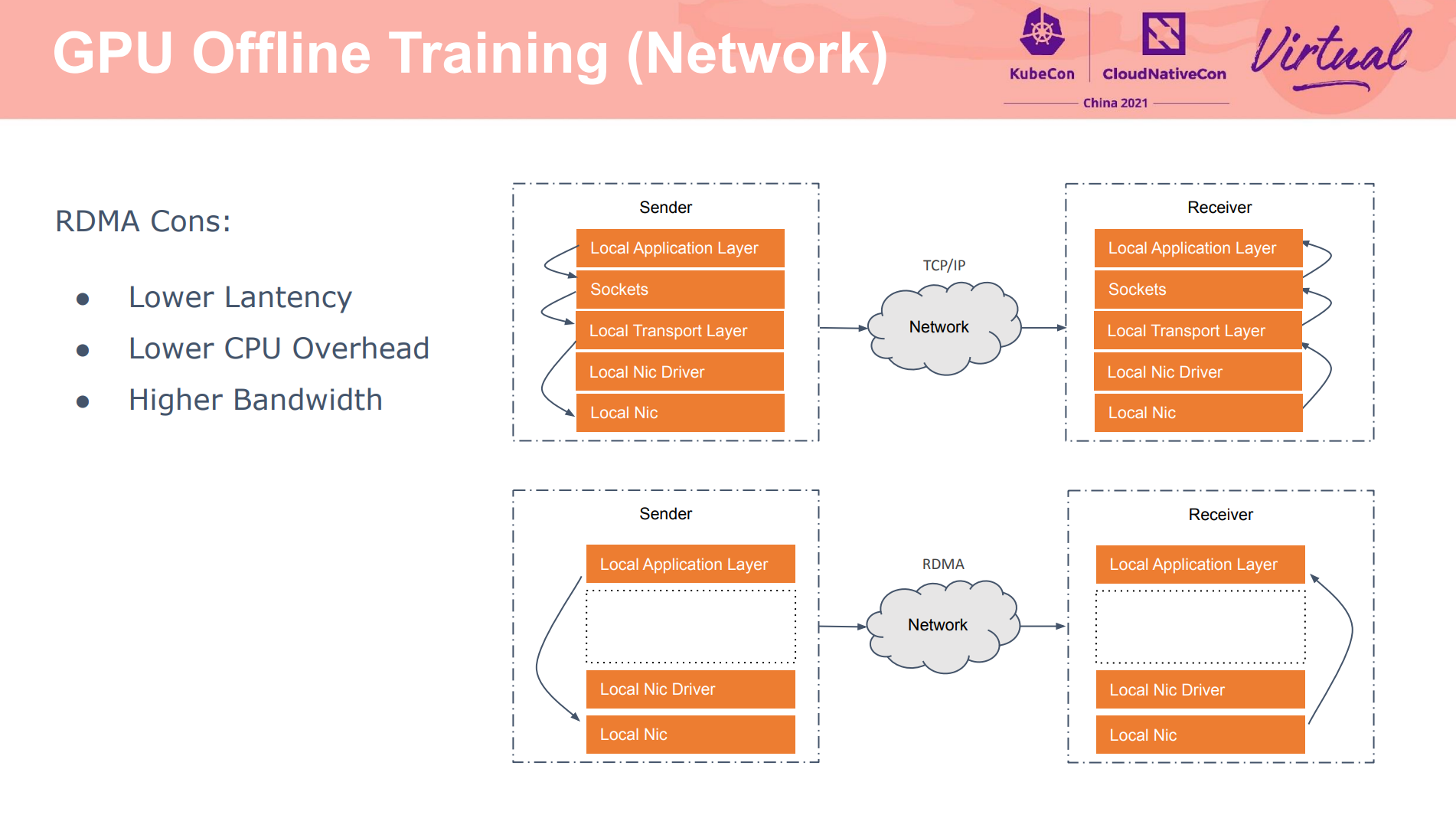


如何实现分配 0.1 卡,具体如何做隔离的没有展开讲(除 MPS 外)。
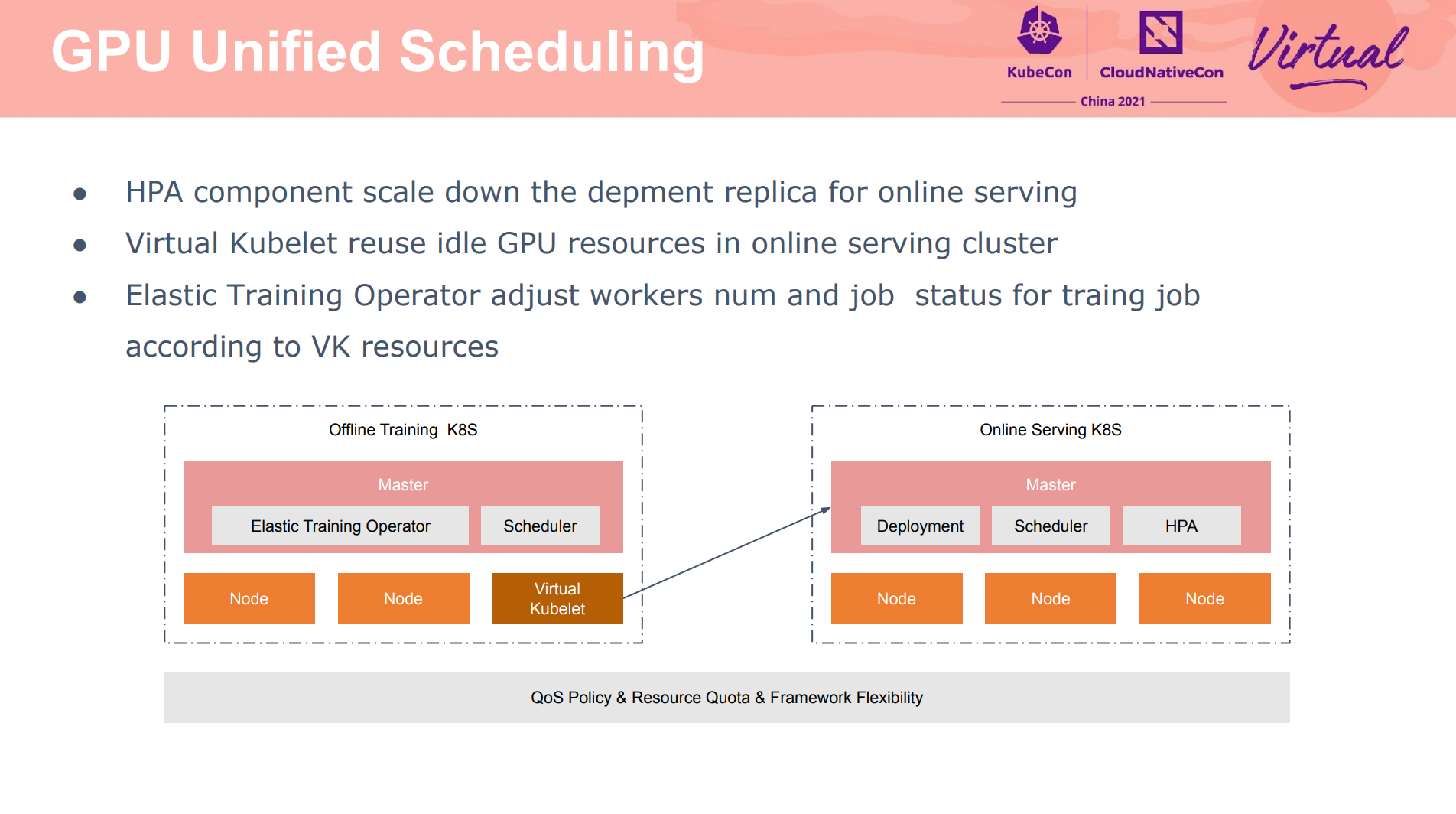
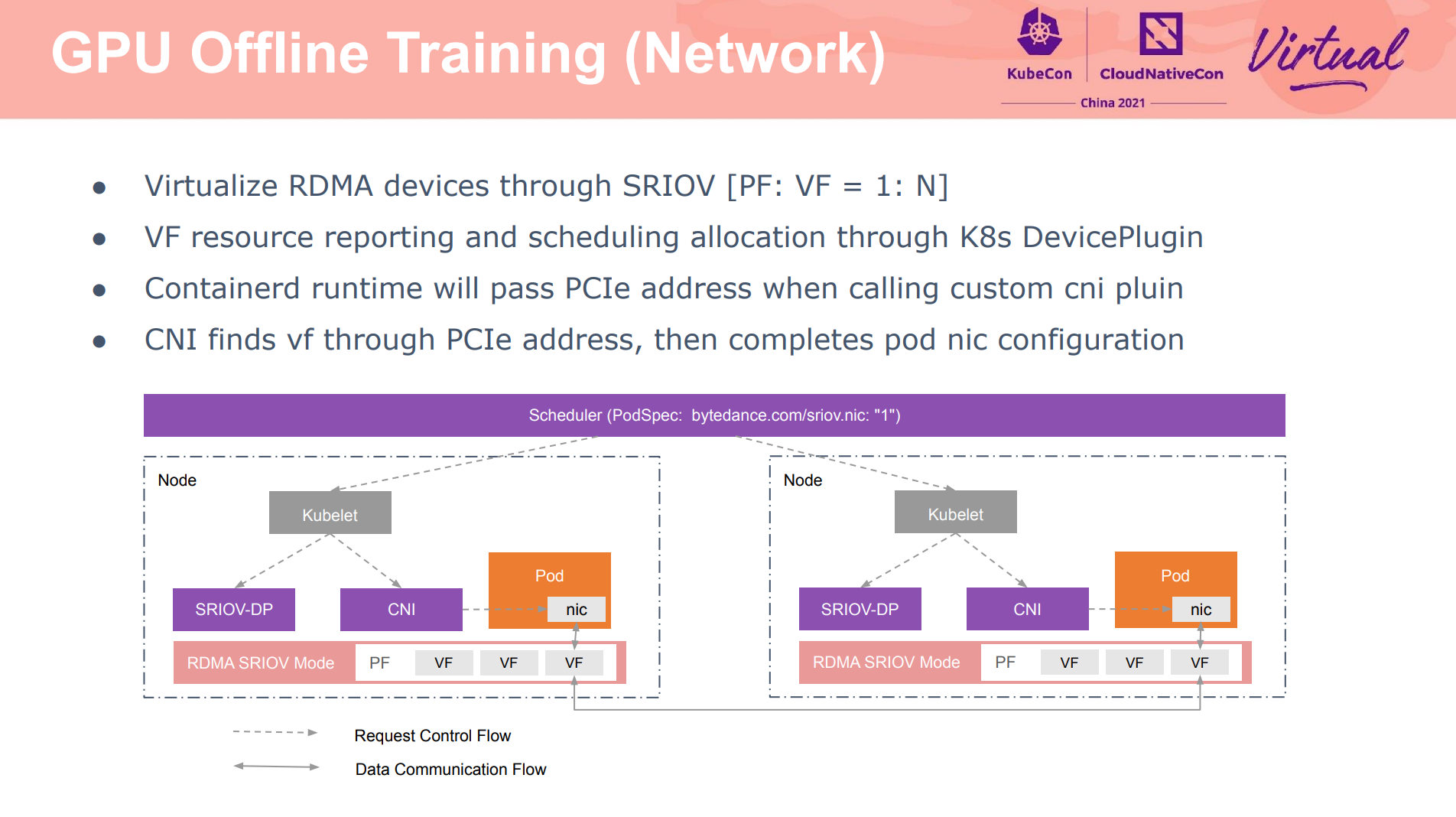
主要依赖 VK 实现。

异构硬件的资源隔离与亲和性,包括异构的 GPU 网卡直通,应该是件有趣的事情。
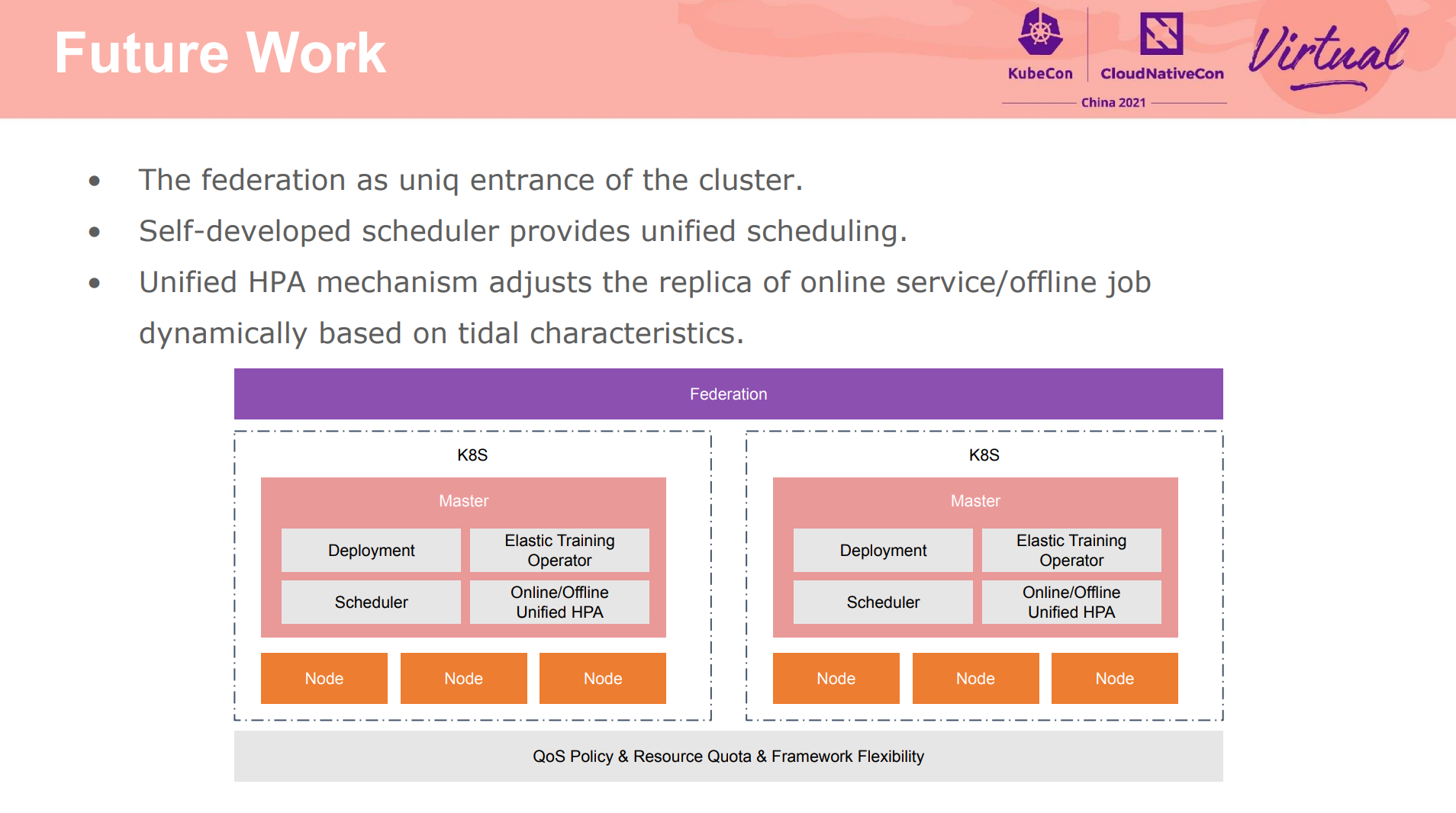
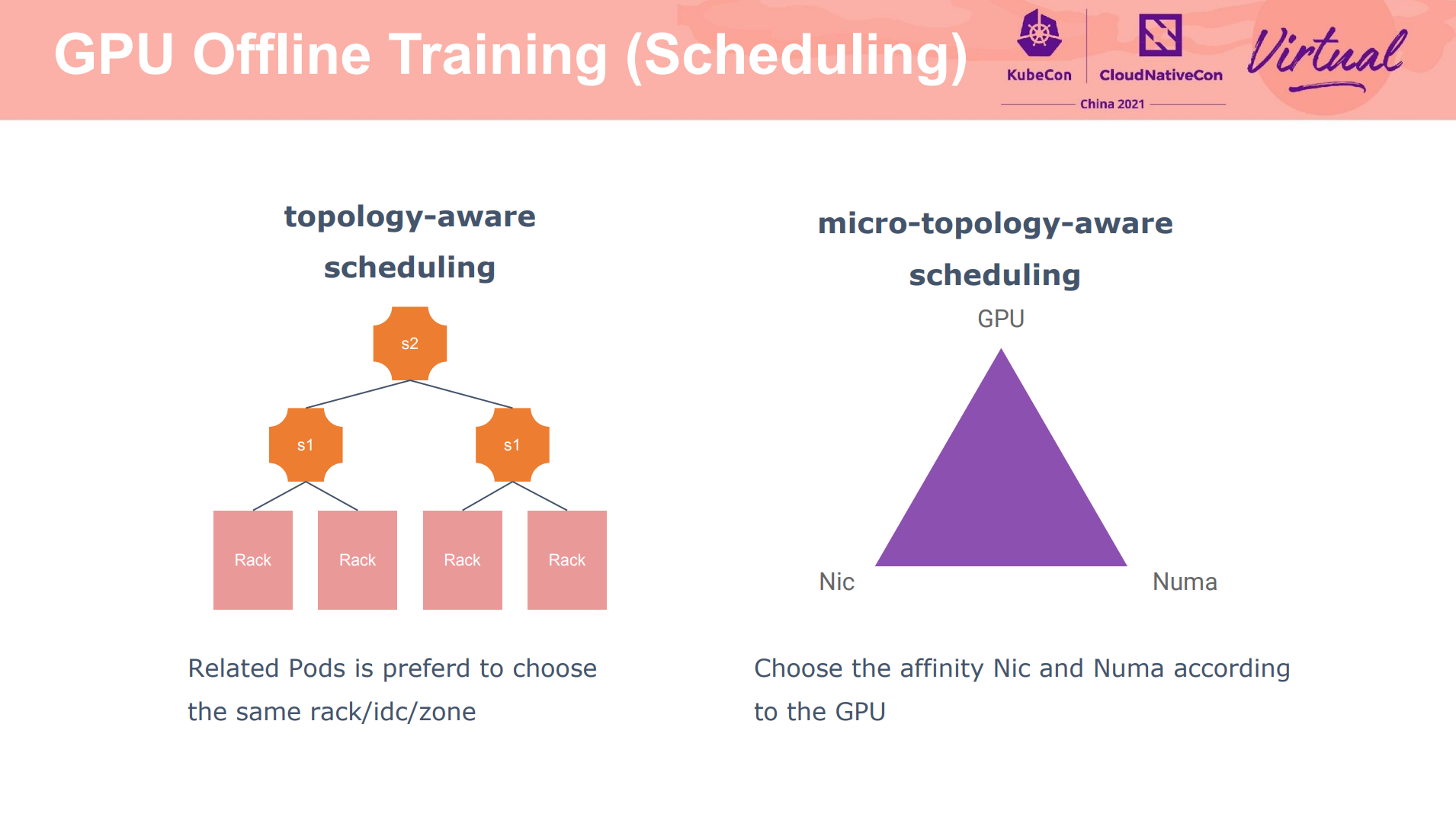
更丰富的调度策略。
想要性能好,还是得靠钱堆,感觉没什么黑科技呀。 A100、V100、RDMA、智能网卡都需要钱,小公司根本玩不起。
Overview of CNI 1.0.0 and preview of CNI 2.0
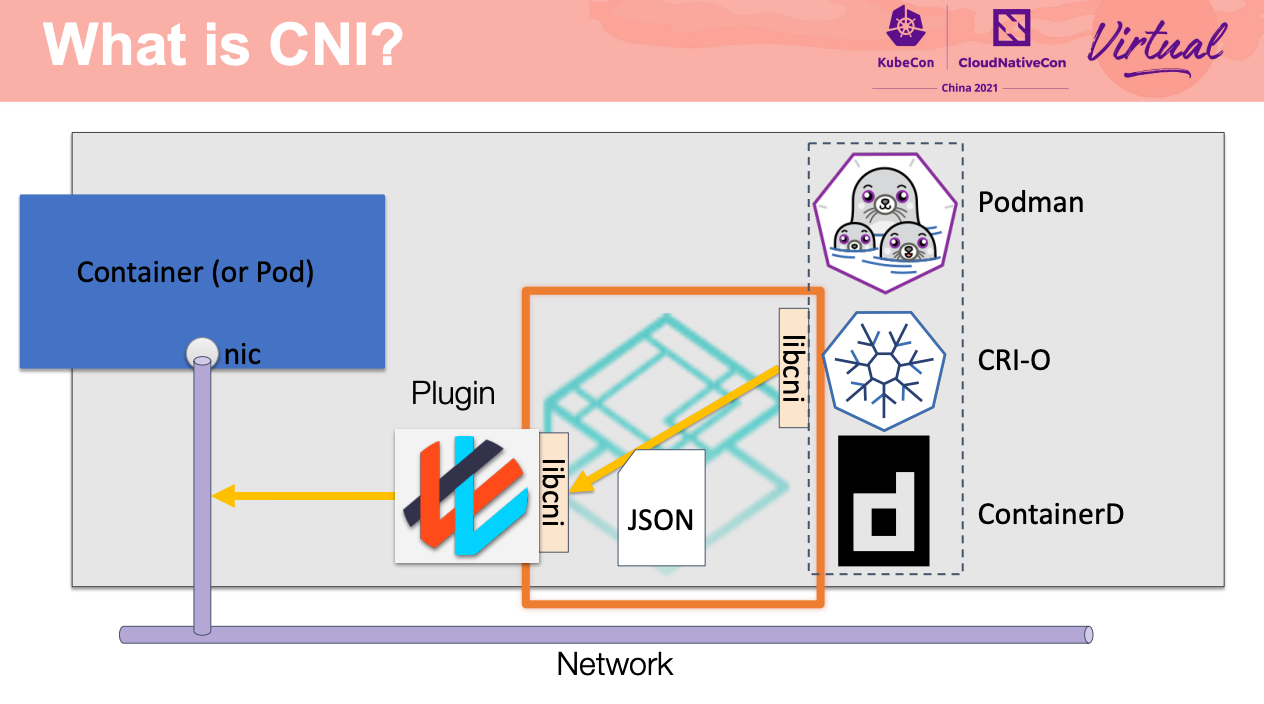

如果能在 2.0 改成 gRPC 会灵活很多。
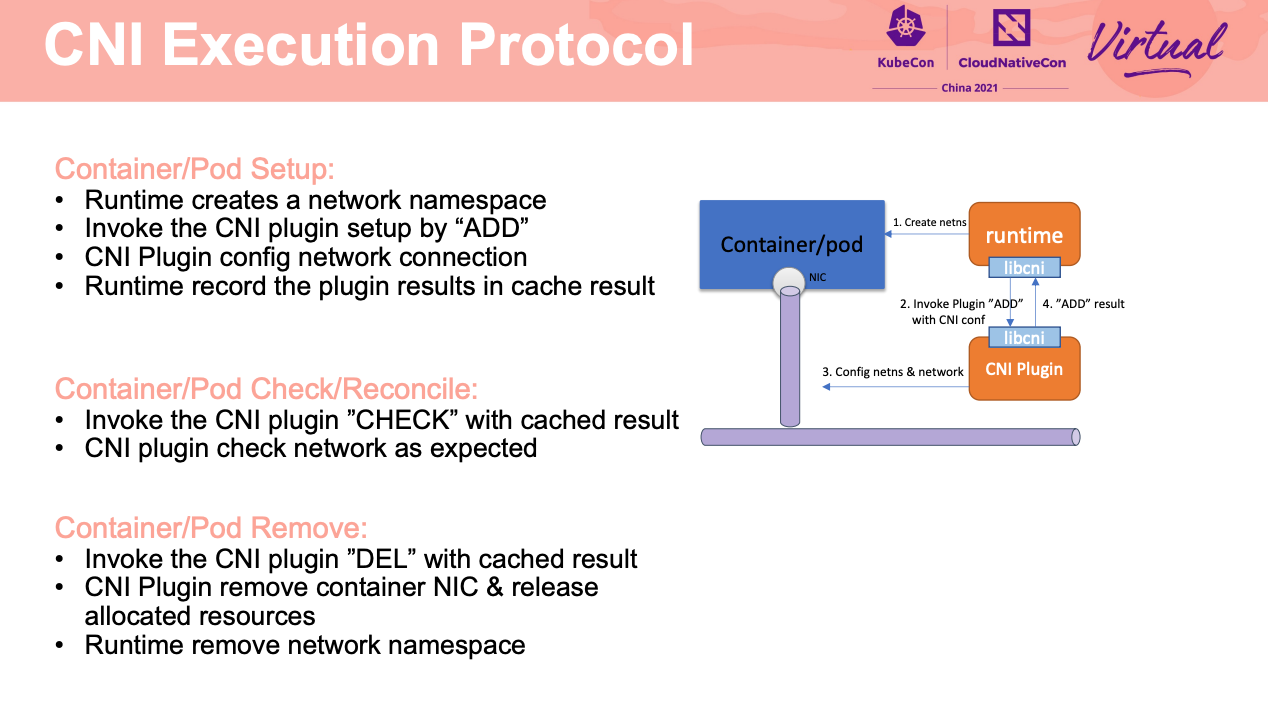






如果能解决中心化 IPAM、通用化多网卡配置就非常棒了。

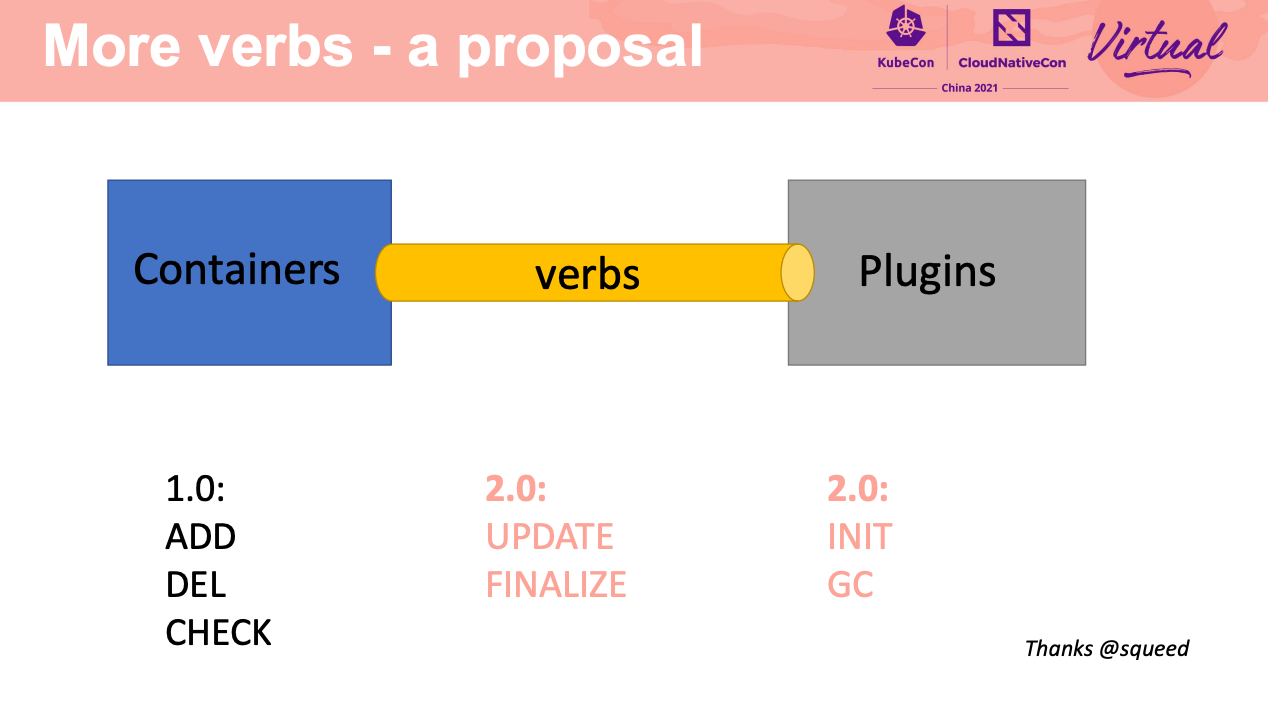
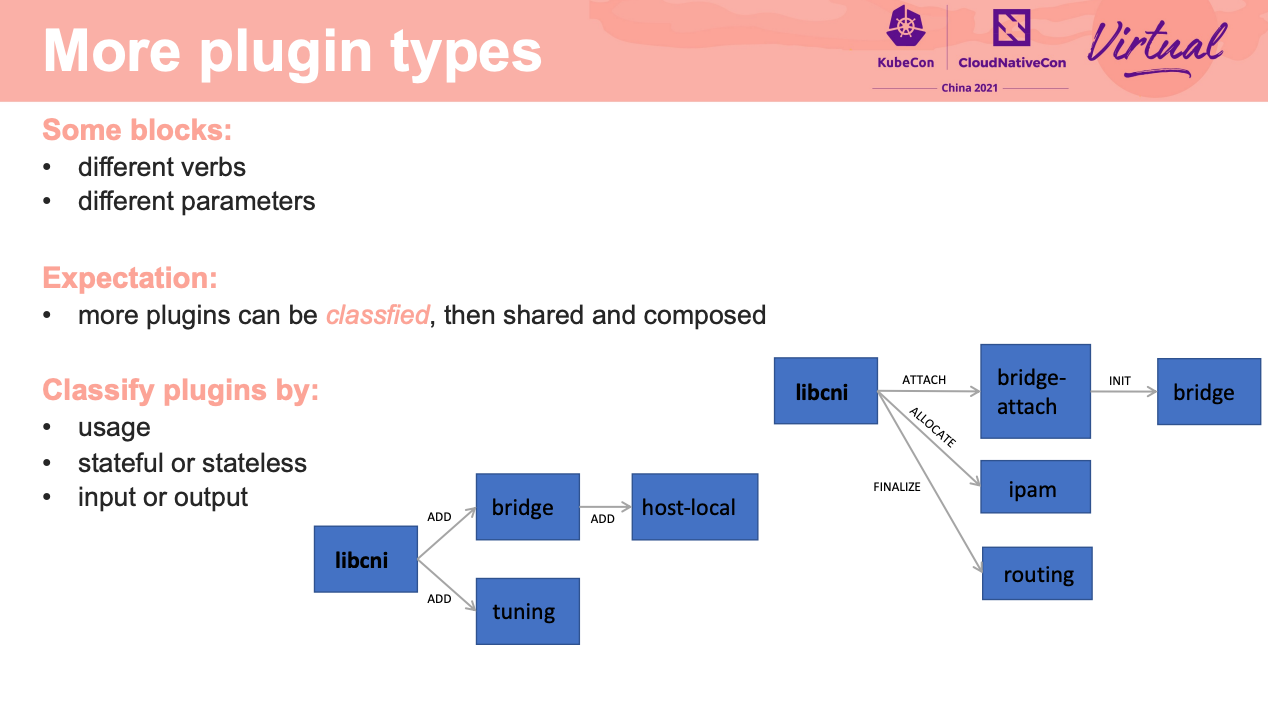
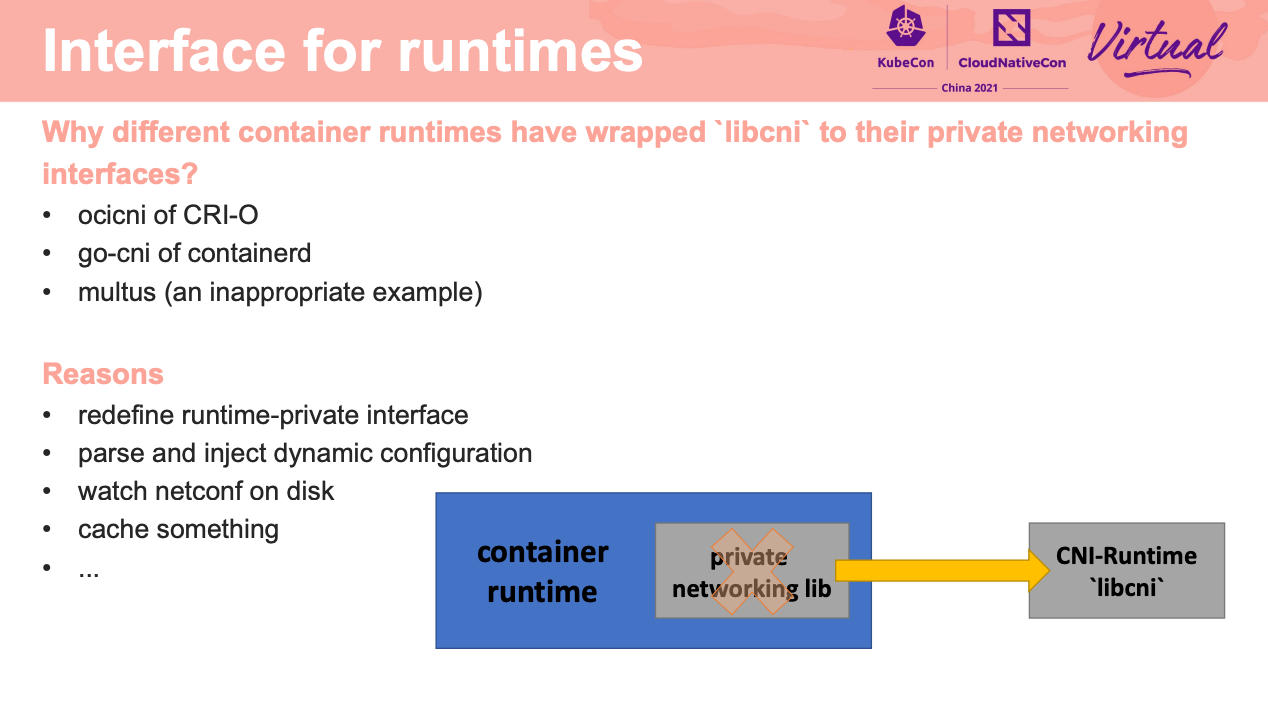
又回到了 API First。
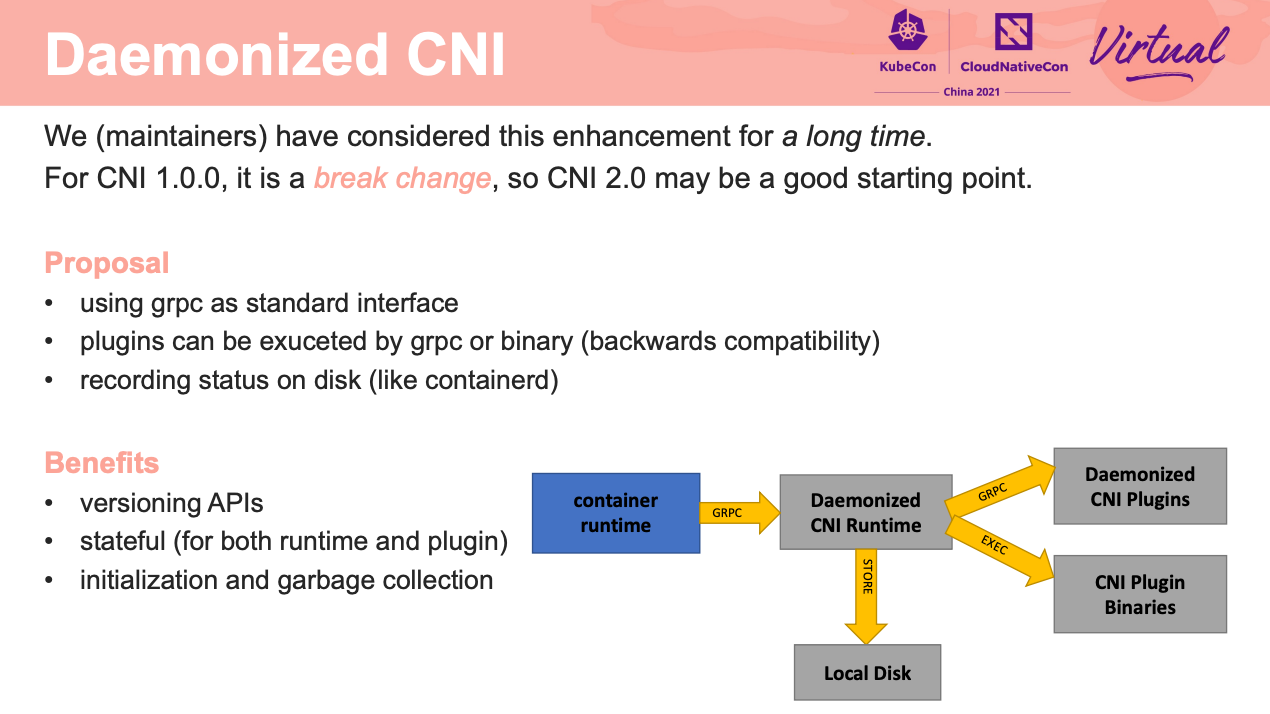
1.0 -> 2.0 能不能平滑升级是个问题啊。


- 如何做到动态升级,而应用层无感知?
- 多租户如何做隔离?
Kubernetes SIG Storage Introduction and Update
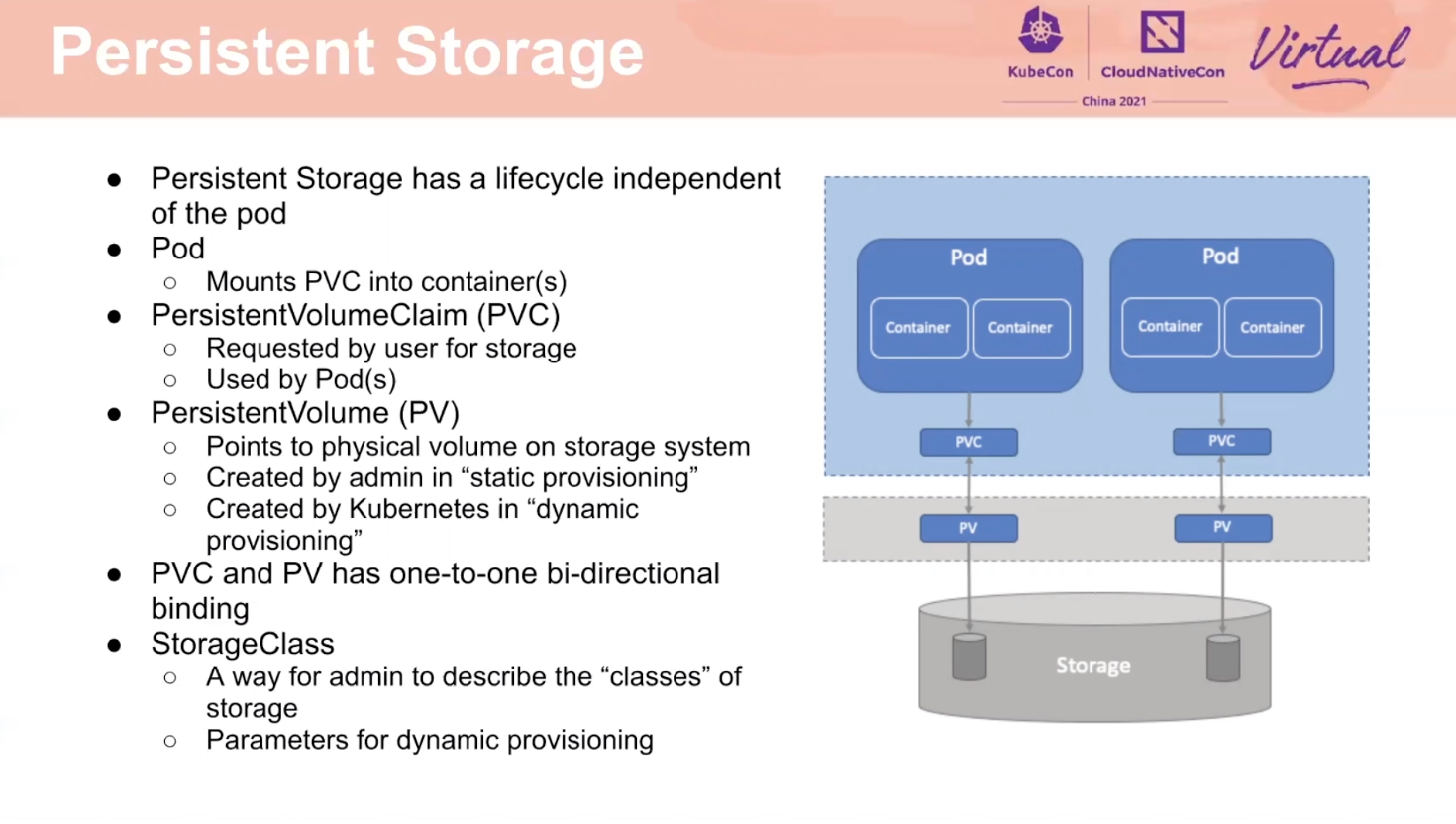



和 CNI 遇到了同样的问题,就是如何兼容厂商的多样性。
Heterogeneous multi-cluster full mesh communication practice
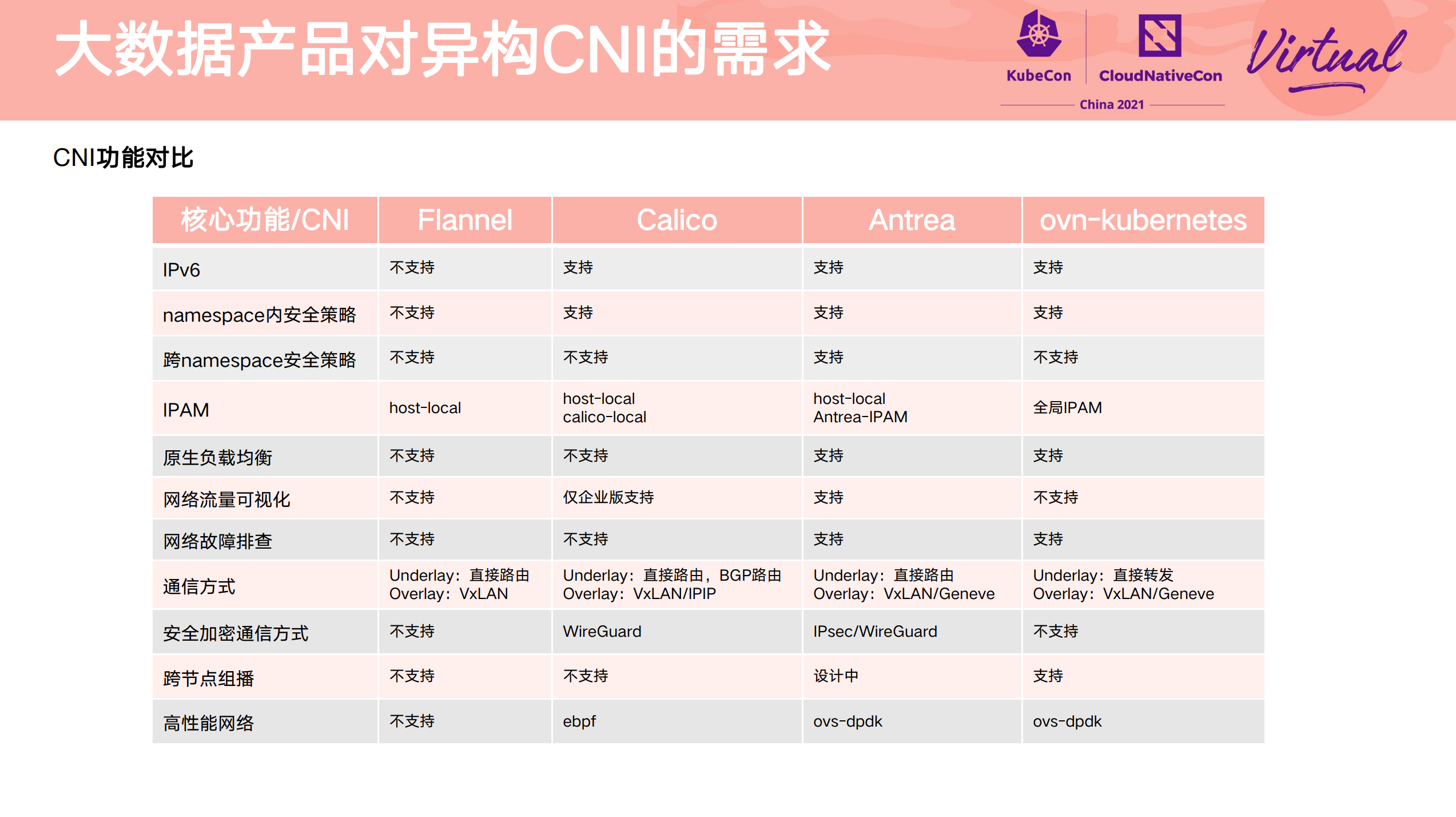
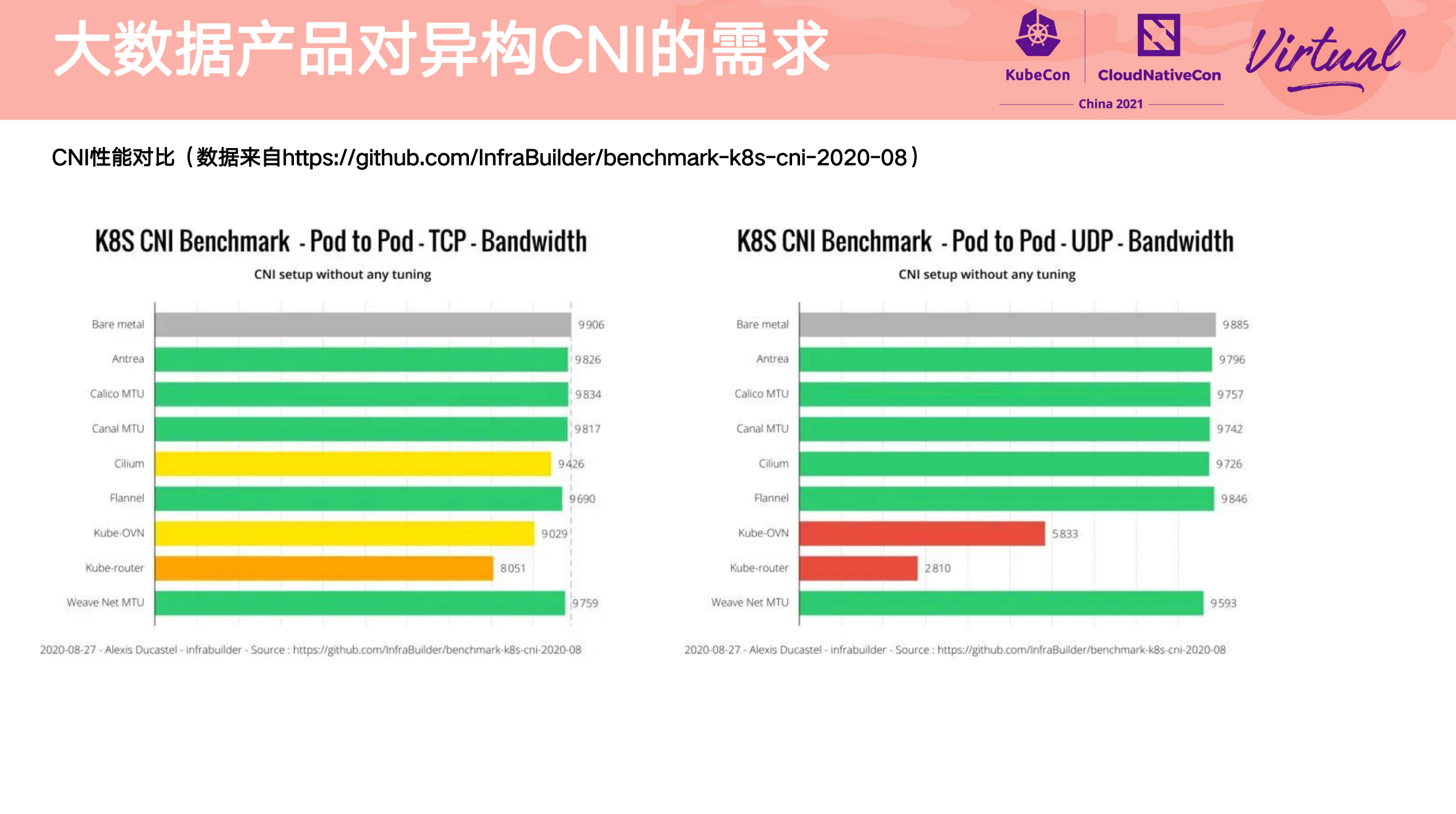
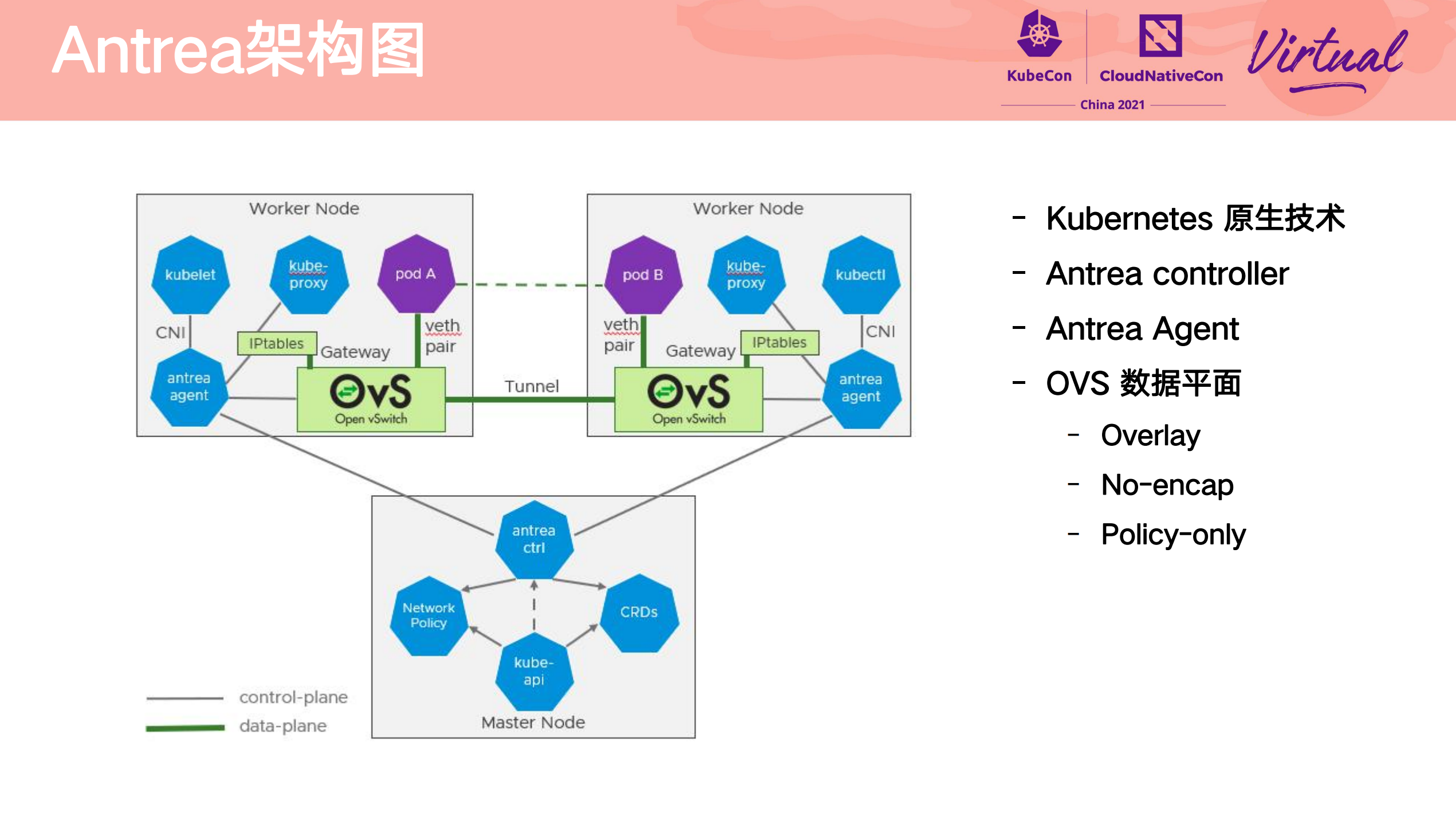
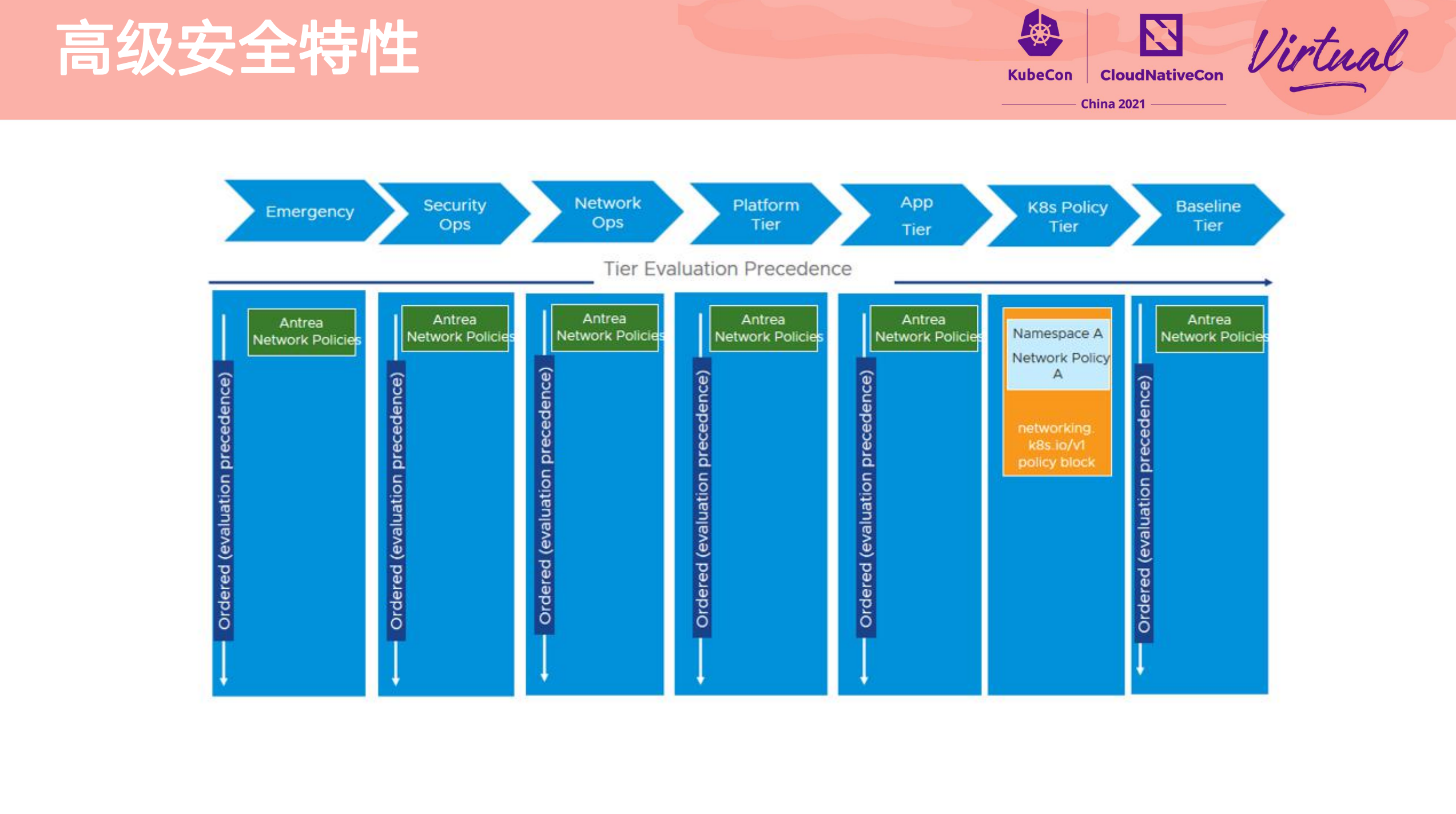
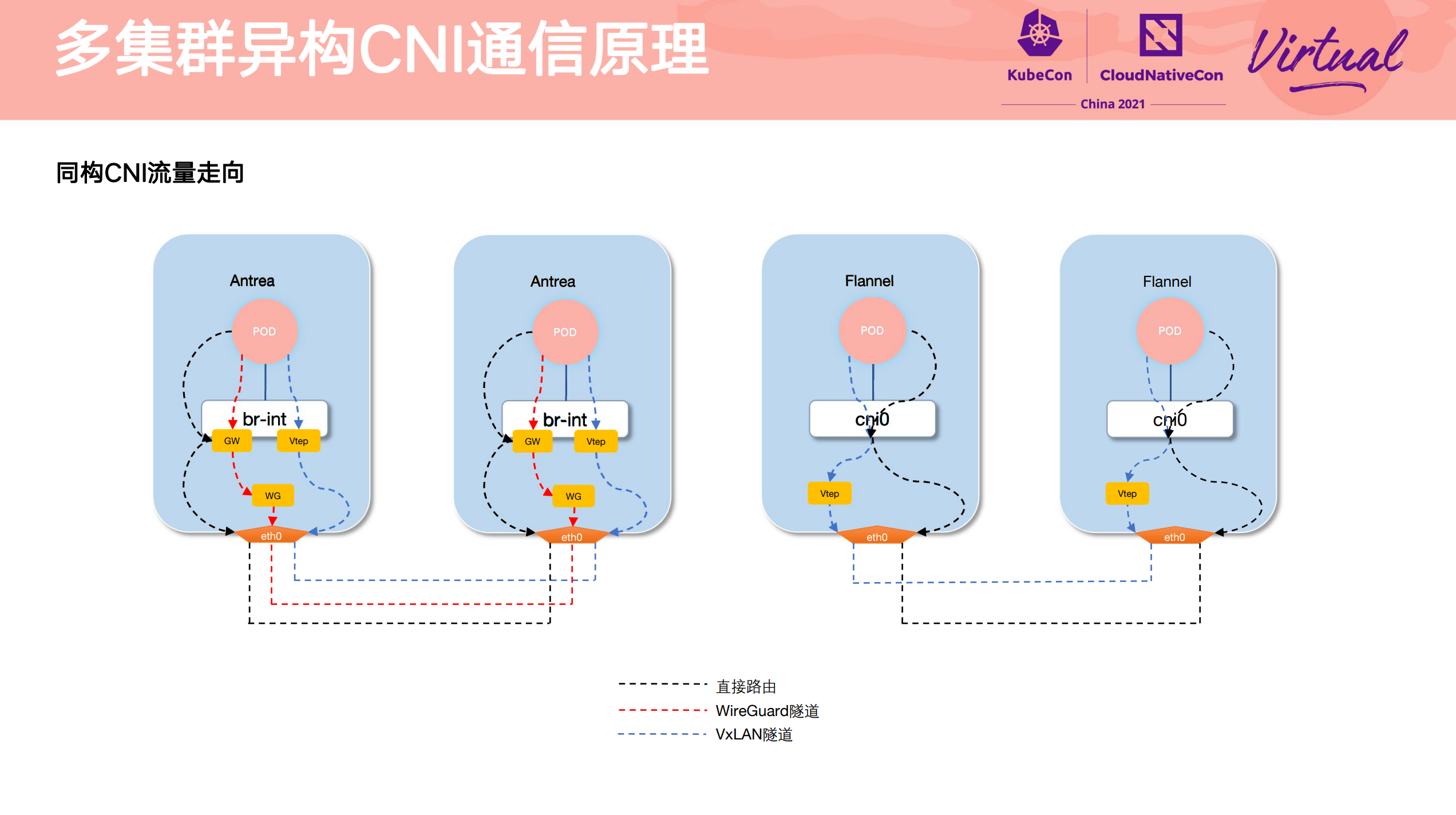
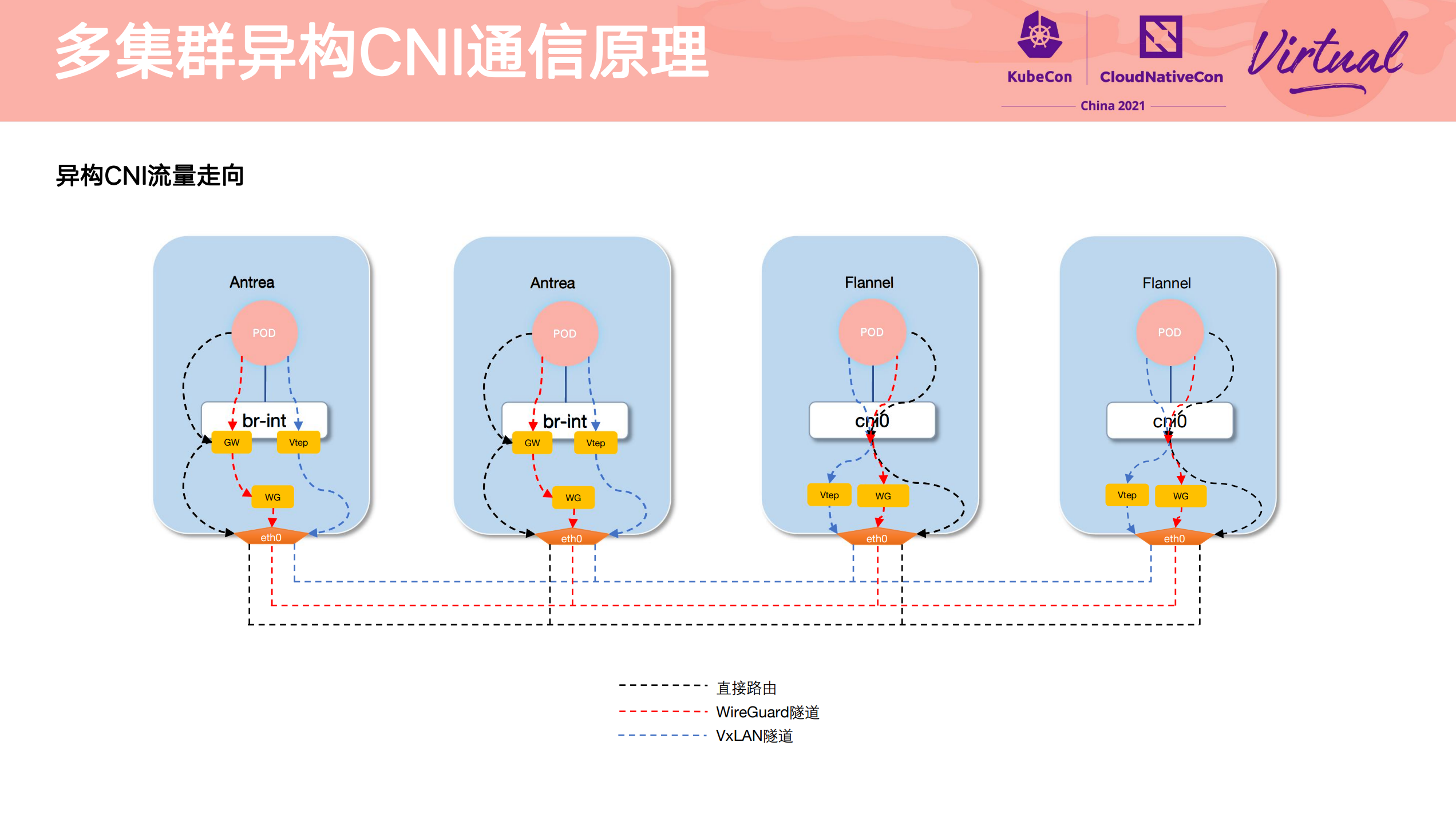
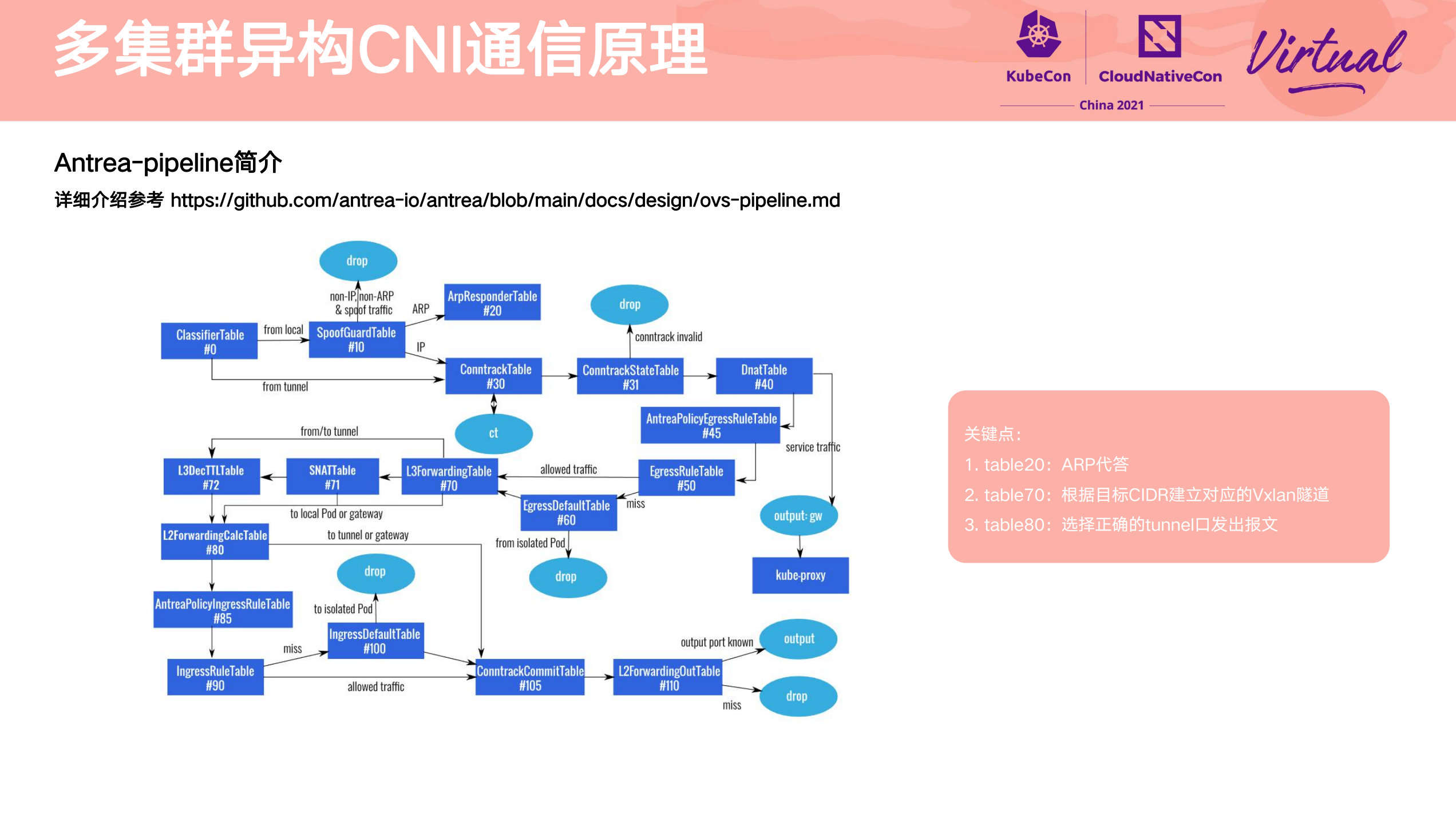
其他参考资料件:
- https://github.com/antrea-io/antrea/blob/main/docs/design/ovs-pipeline.md
- Antrea 架构详解 https://mp.weixin.qq.com/s/5KI3AXP5AWFE3lCJ7n-U5A
小总结
所有视频均可以在 CNCF 的油管 channel 上观看。
https://www.youtube.com/playlist?list=PLj6h78yzYM2PjmJ9A98QCXnMsmONhU--t