这是一篇长文。 真的很长,文章包含大量超链接,图也很多。
下文包含个人理解与主观情感,并未包含所有 Session。 图片来自会议 PPT、付费书籍、网络媒体。
会议议程及 PPT 下载: https://kccncosschn21.sched.com/
第一个主题演讲还提了一下 Dan Kohn。
突然有些唏嘘,如果没有 Dan Kohn,应该不会有 KubeCon China 吧。
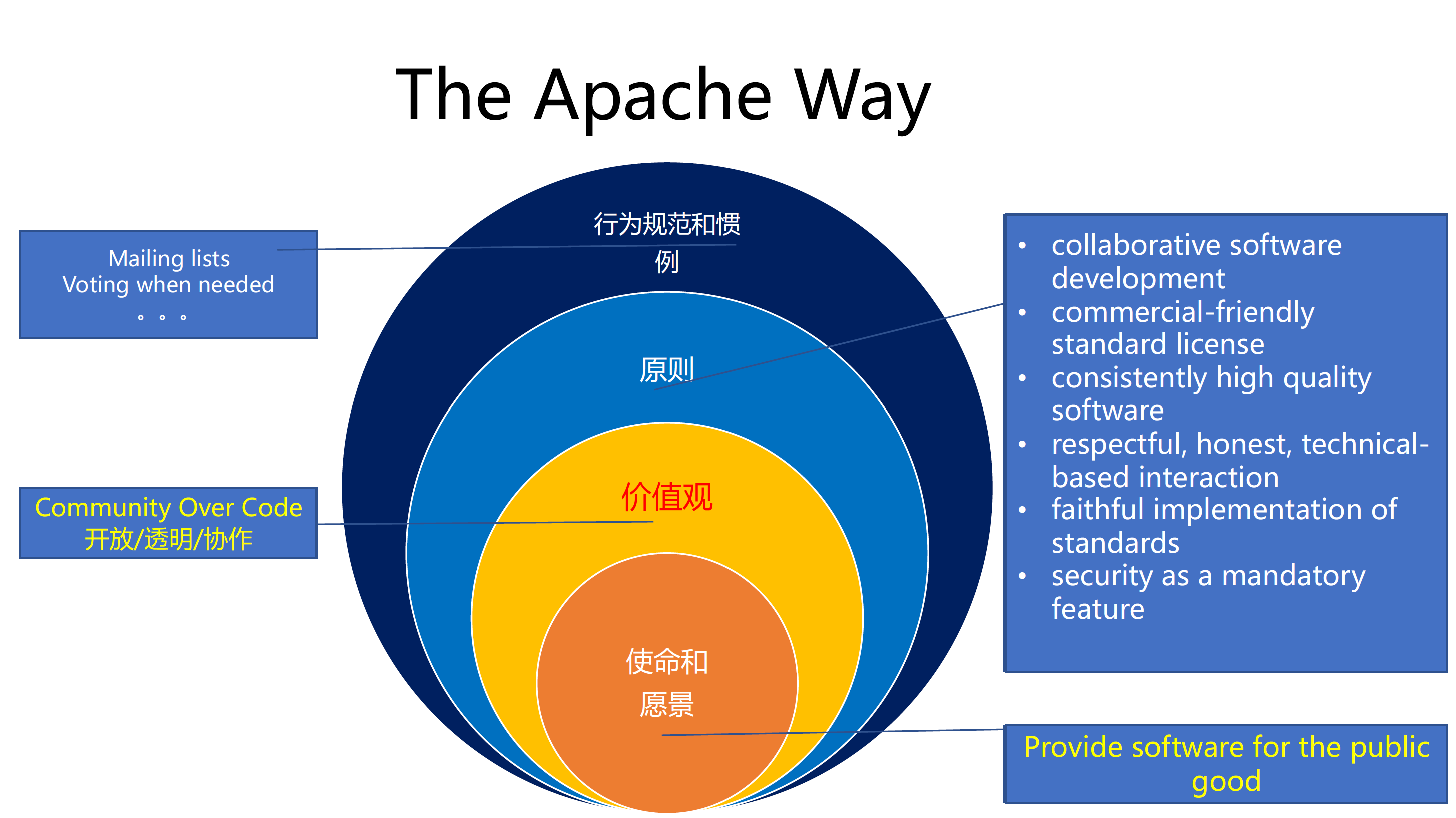
Build an Open Source Distributed Cloud Native World
华为云提到的分布式云原生概念。
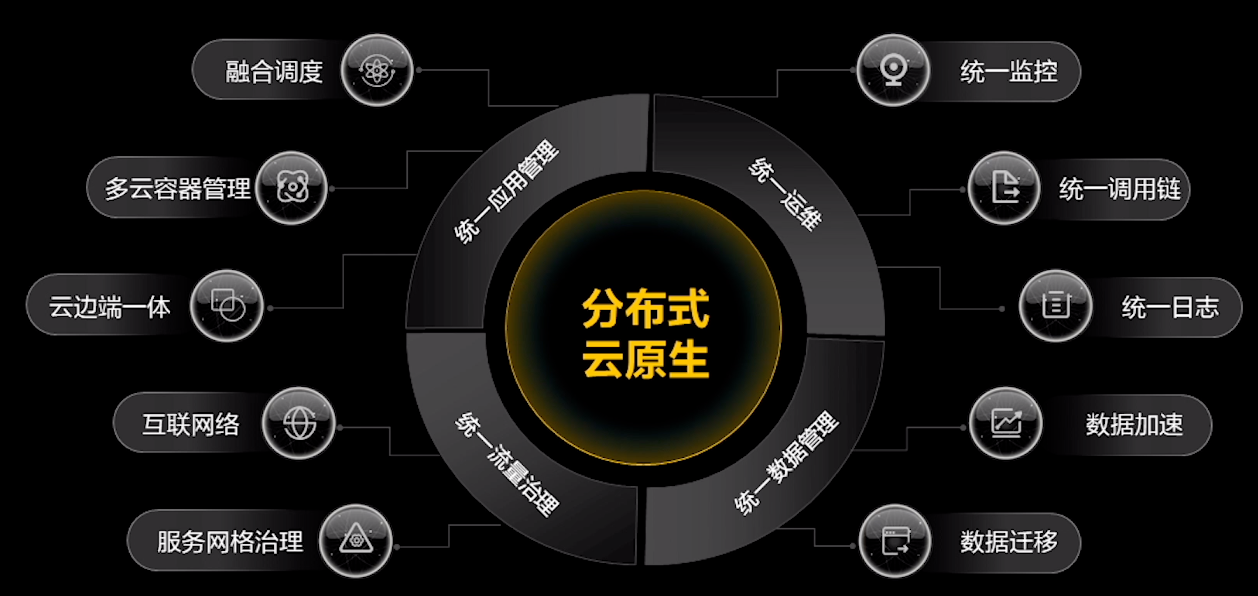
主要是围绕 KubeEdge、Volcano、Karmada 做相关讲解和介绍。
How You Can Create a CNCF Project
张磊的 Session 非常有意思。

选择把项目交给 CNCF 的原因:
- 中立、可信赖
- CNCF 中的项目具有同样的价值观,大家的想法类似,更容易合作、互操作、互相借力
- 世界级的推广策略
- 完善的开源治理方法
- 通过兴趣小组,可以获得相关的建议
CPU Burst Getting Rid of Unnecessary Throttling, Achieving High CPU Utilization and Application Performance at the Same Time
该 Session 重点全在 PPT 上,直接看 PPT 即可。
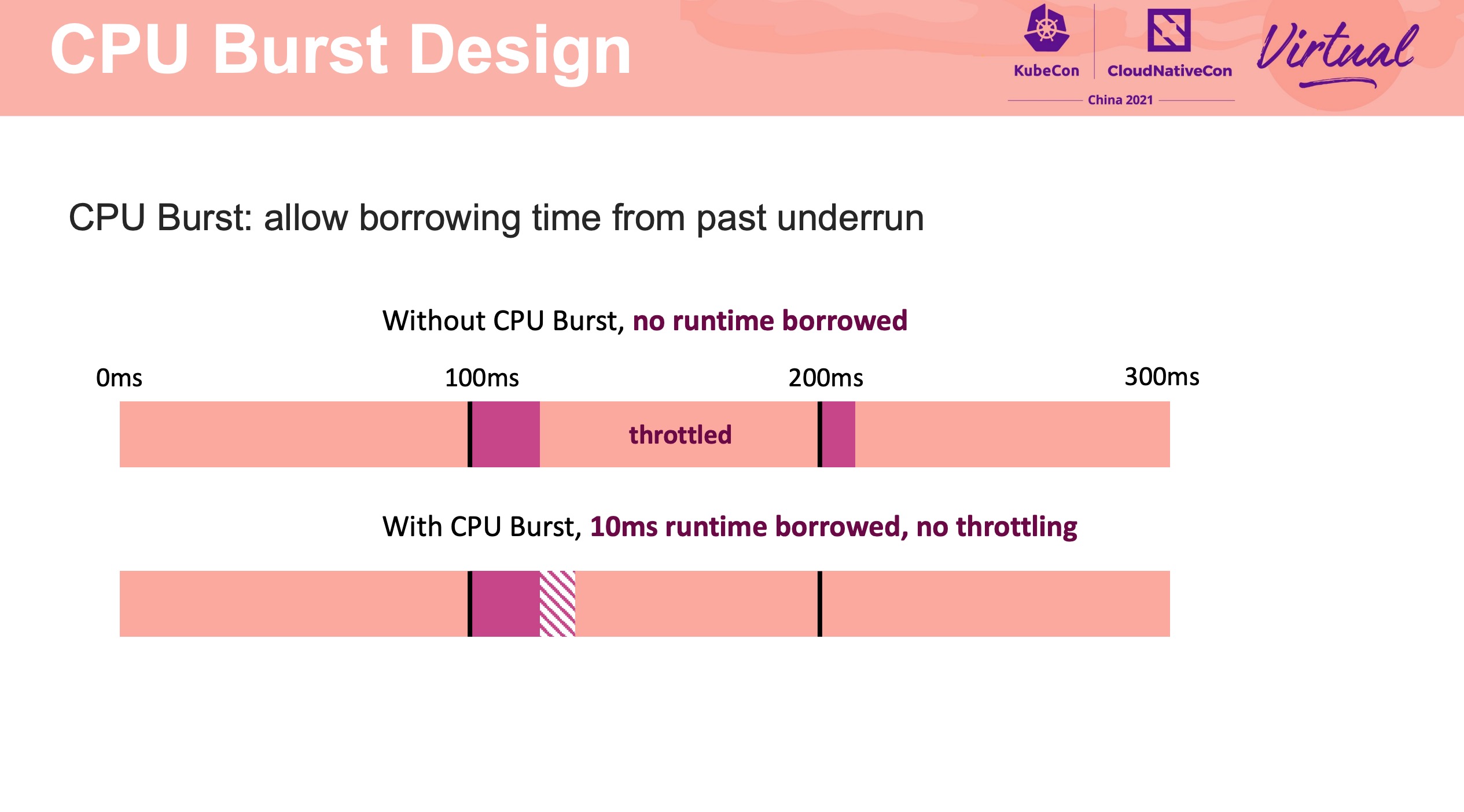
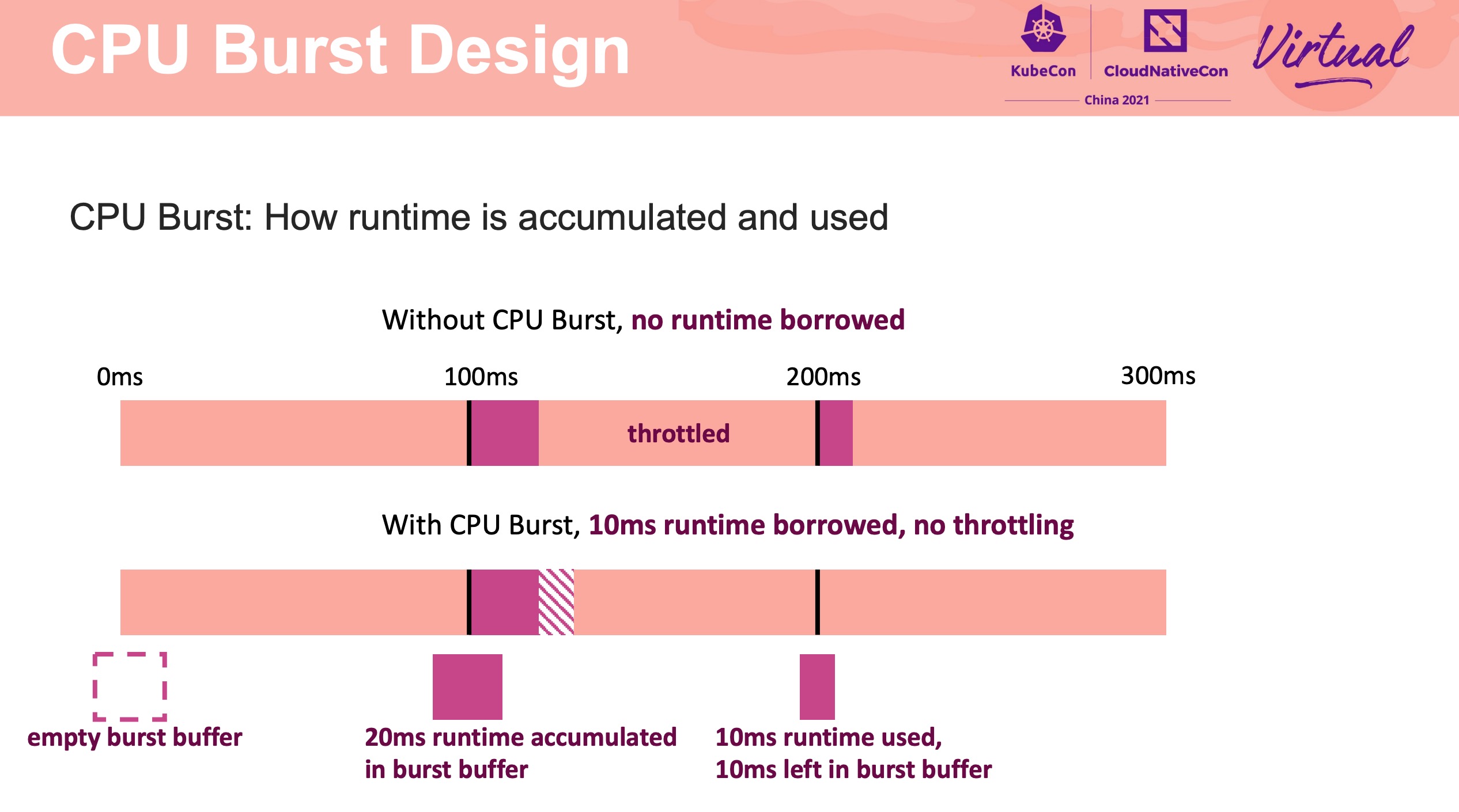
该功能已合入 Linux Kernel 5.14。
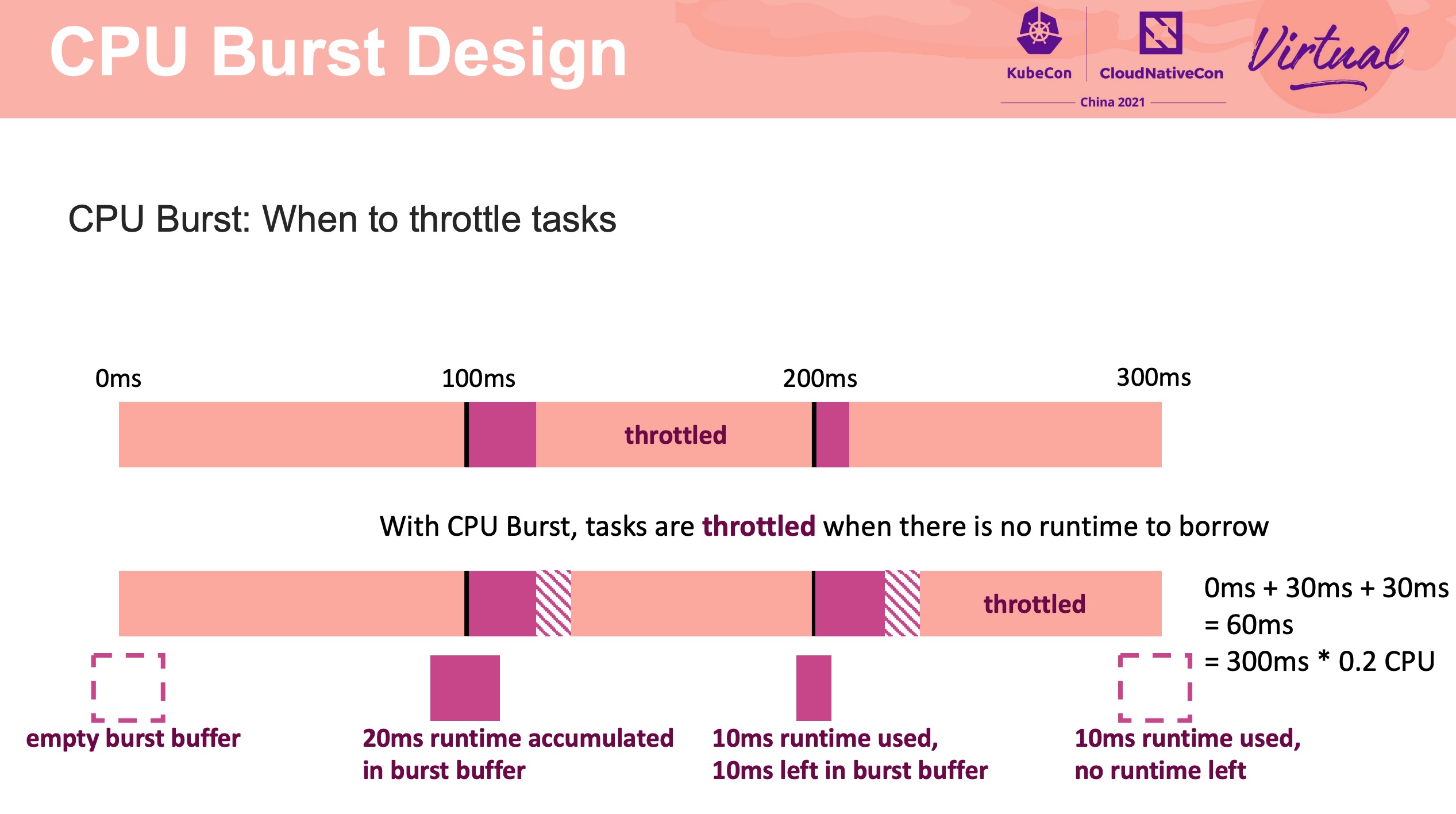
CPU Burst 的特性可允许平均 CPU 利用率低于 CPU 限制情况下可能的突发使用。
应用 CPU Burst 后,用户可以同时获得高 CPU 利用率和高应用程序性能。
CPU Burst 在之前有过介绍(也是该 Speaker 的文章):
- 让容器跑得更快:CPU Burst 技术实践 https://www.infoq.cn/article/y2semvajjgxj9mbg9p00
一张图解释什么是 CPU Burst。
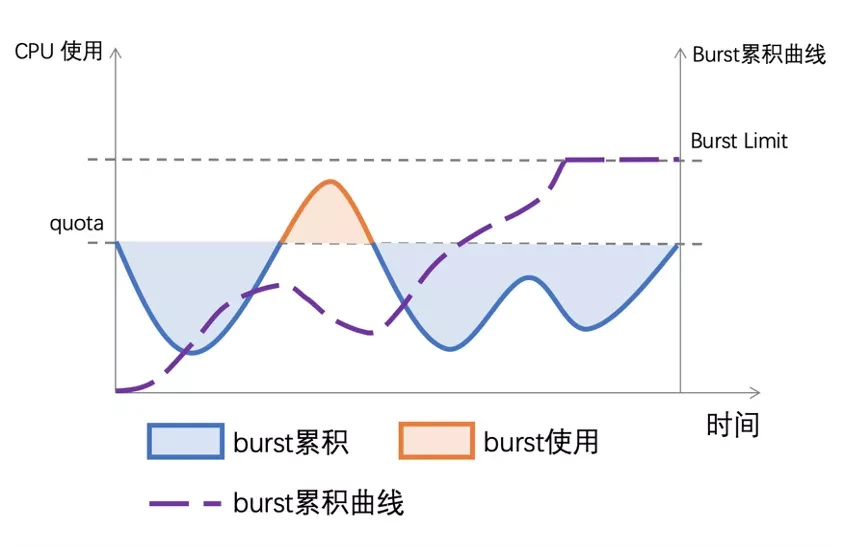
图片来自上述 InfoQ 链接。











How CPU Burst affects other pods
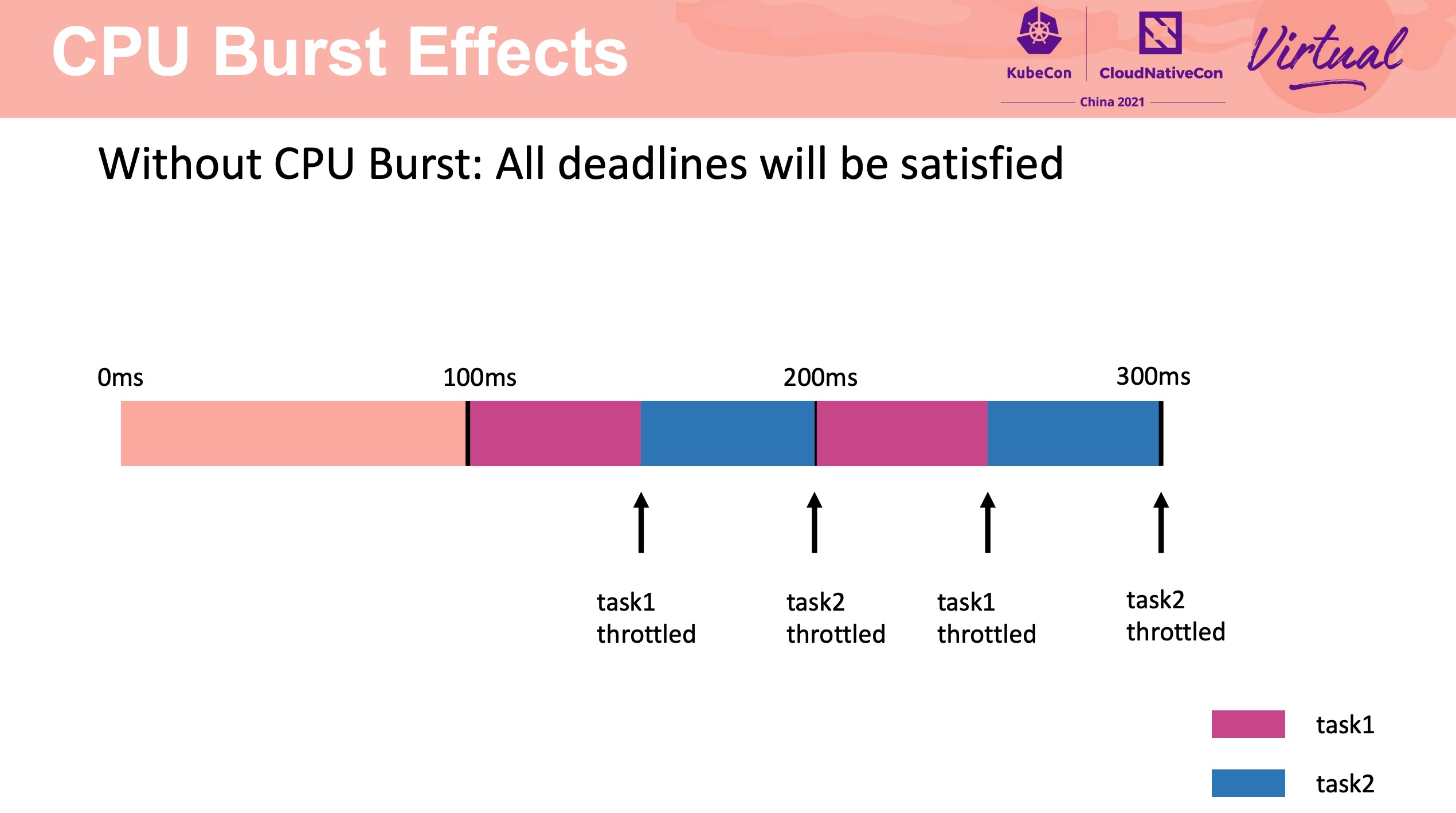
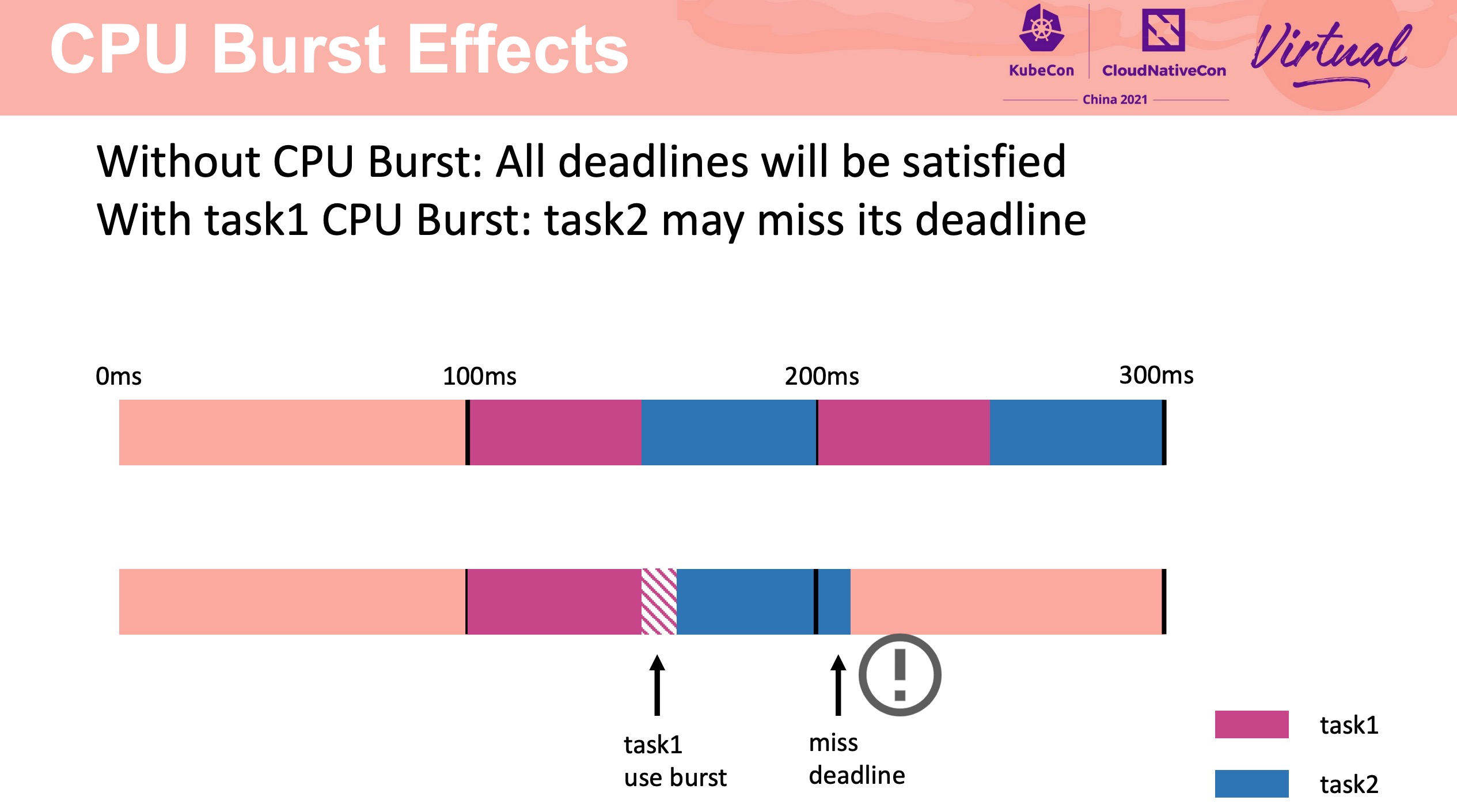
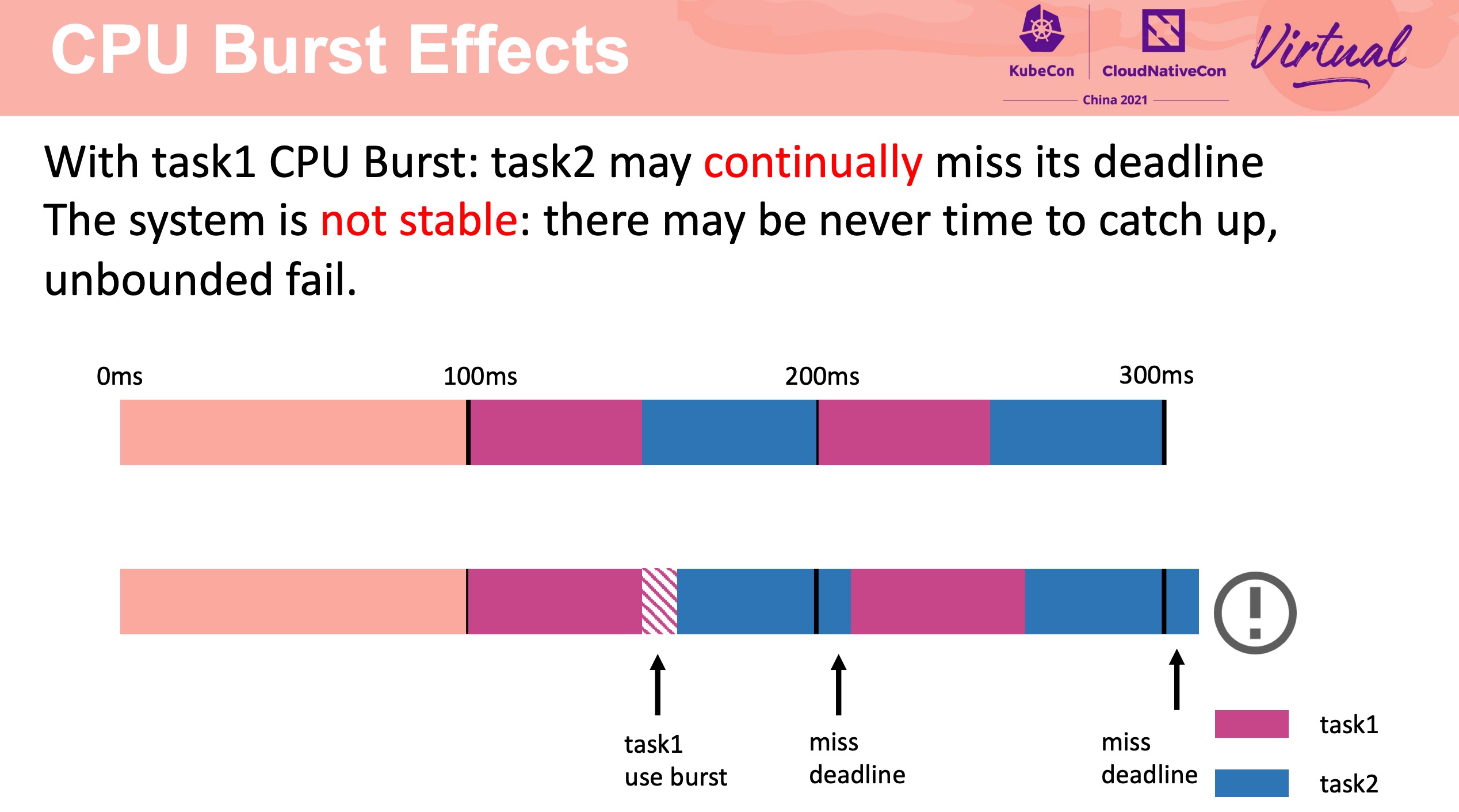
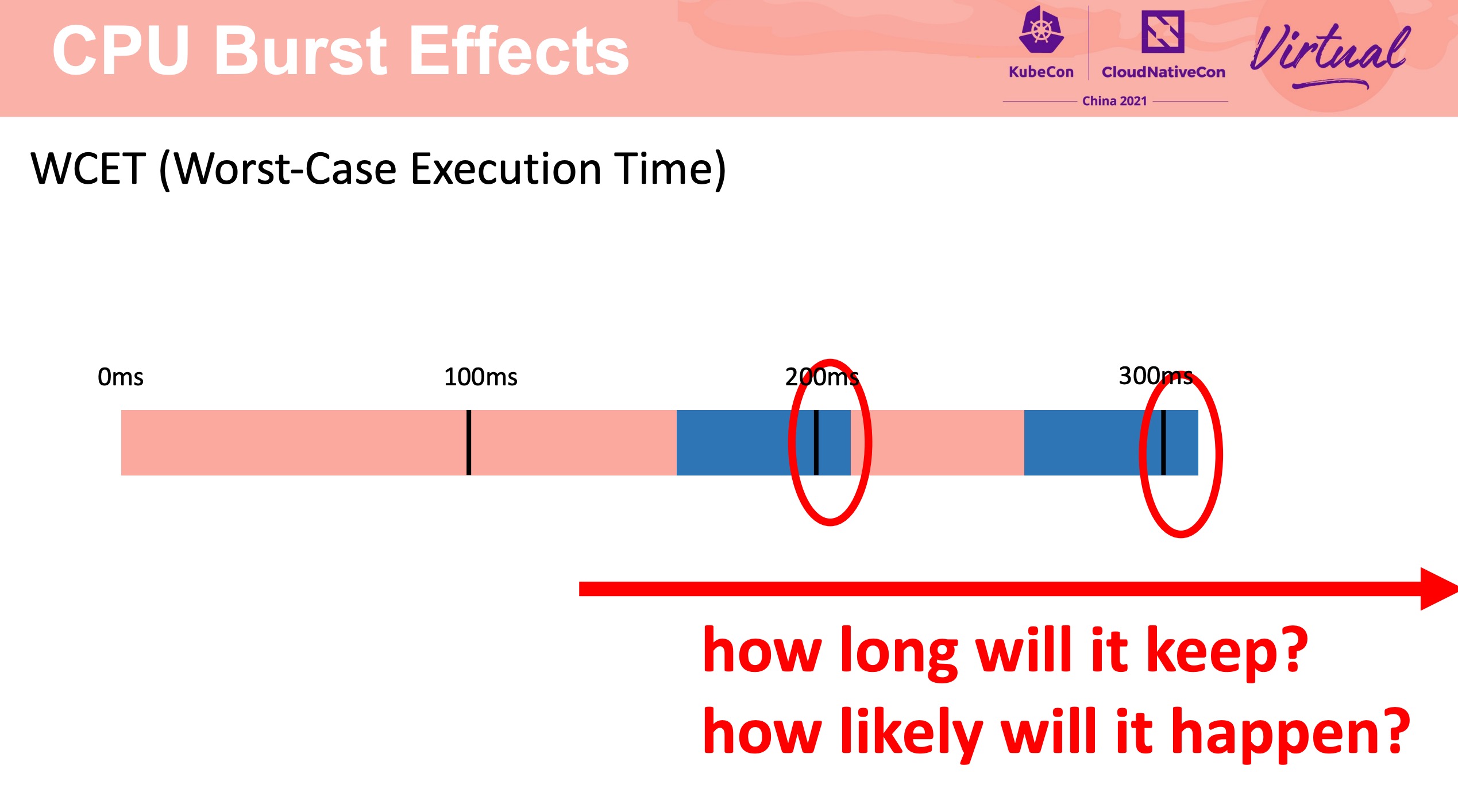

CPU Burst 不是银弹。
需要合理配置 CPU Burst buffer。
Beyond CUDA GPU Accelerated Computing on Cross-Vendor Graphics Cards with Vulkan Kompute
直接看下面链接的文章就好。
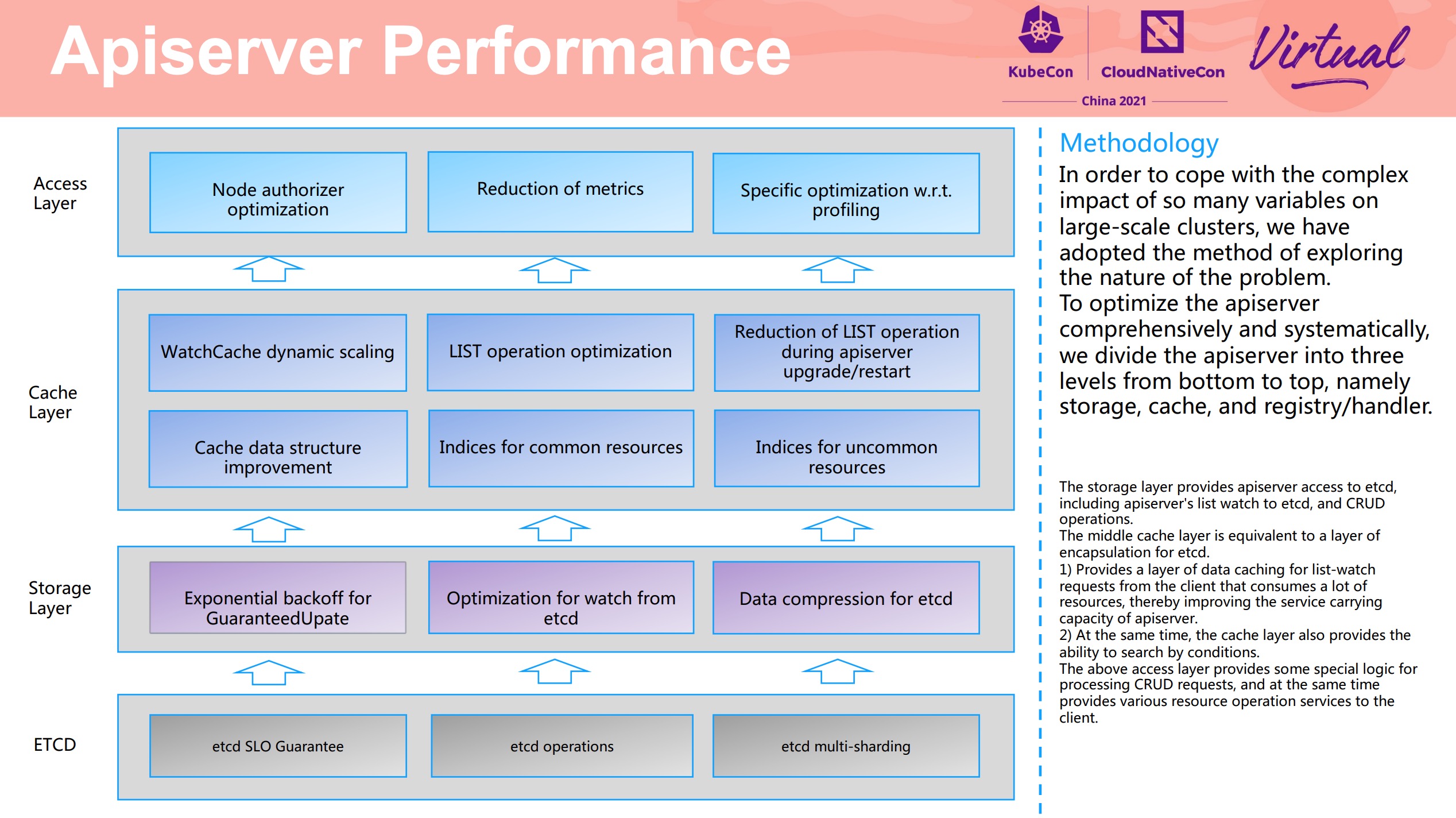
Apiserver Builder Extending Kubernetes via Aggregated Apiserver
Apiserver Aggregation 整体流程的介绍、与 CRD 的对比、如何不依赖 Etcd、以 OCM 举例等。
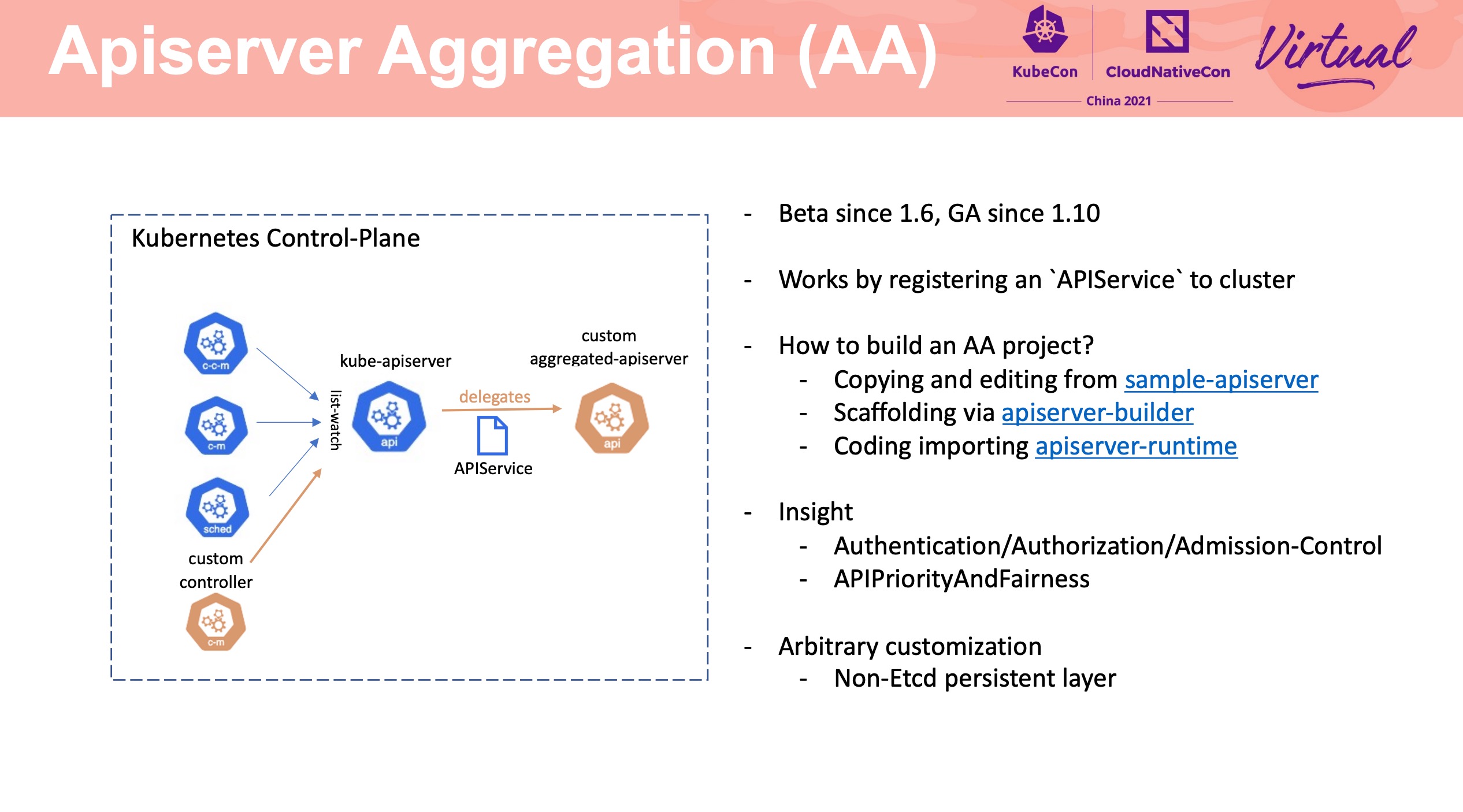
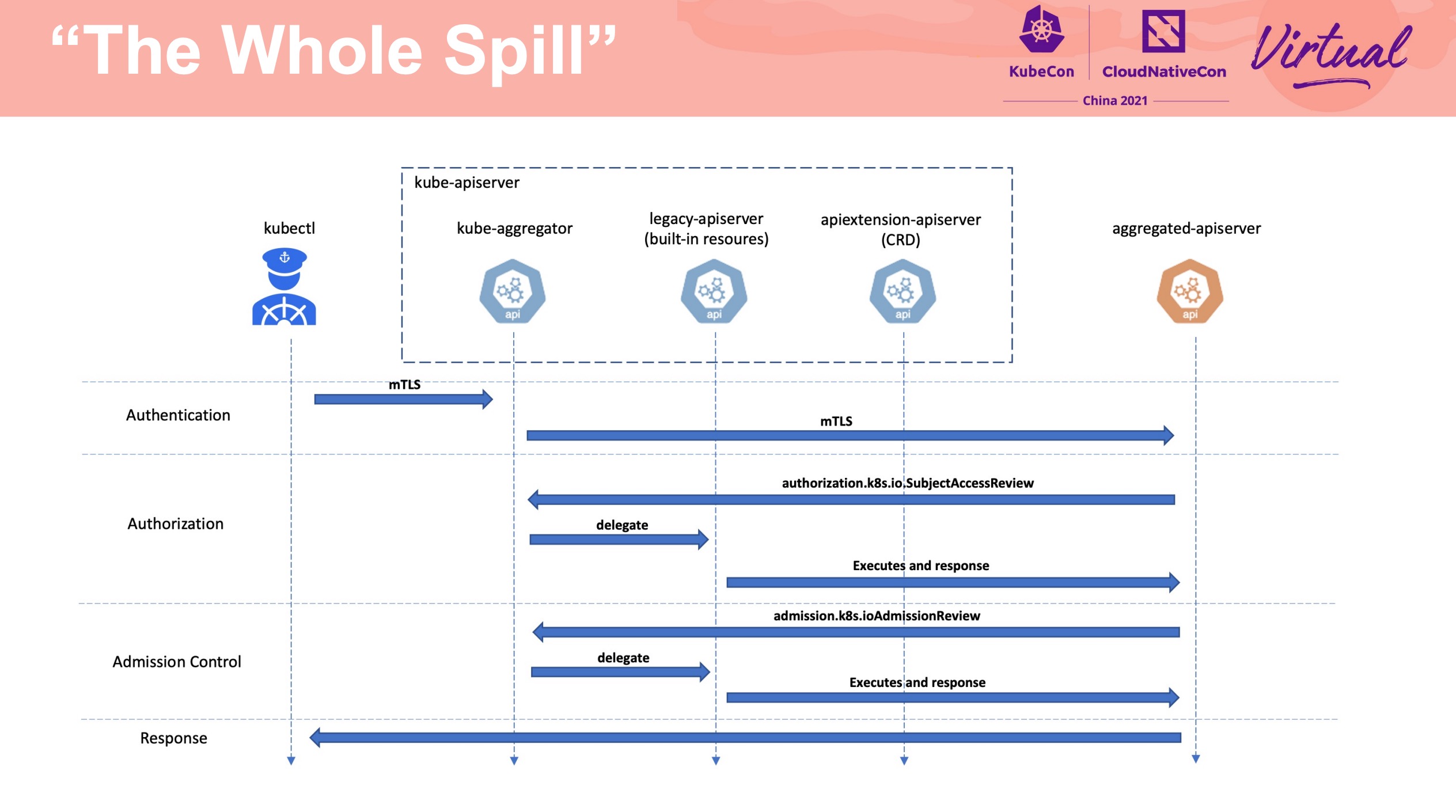

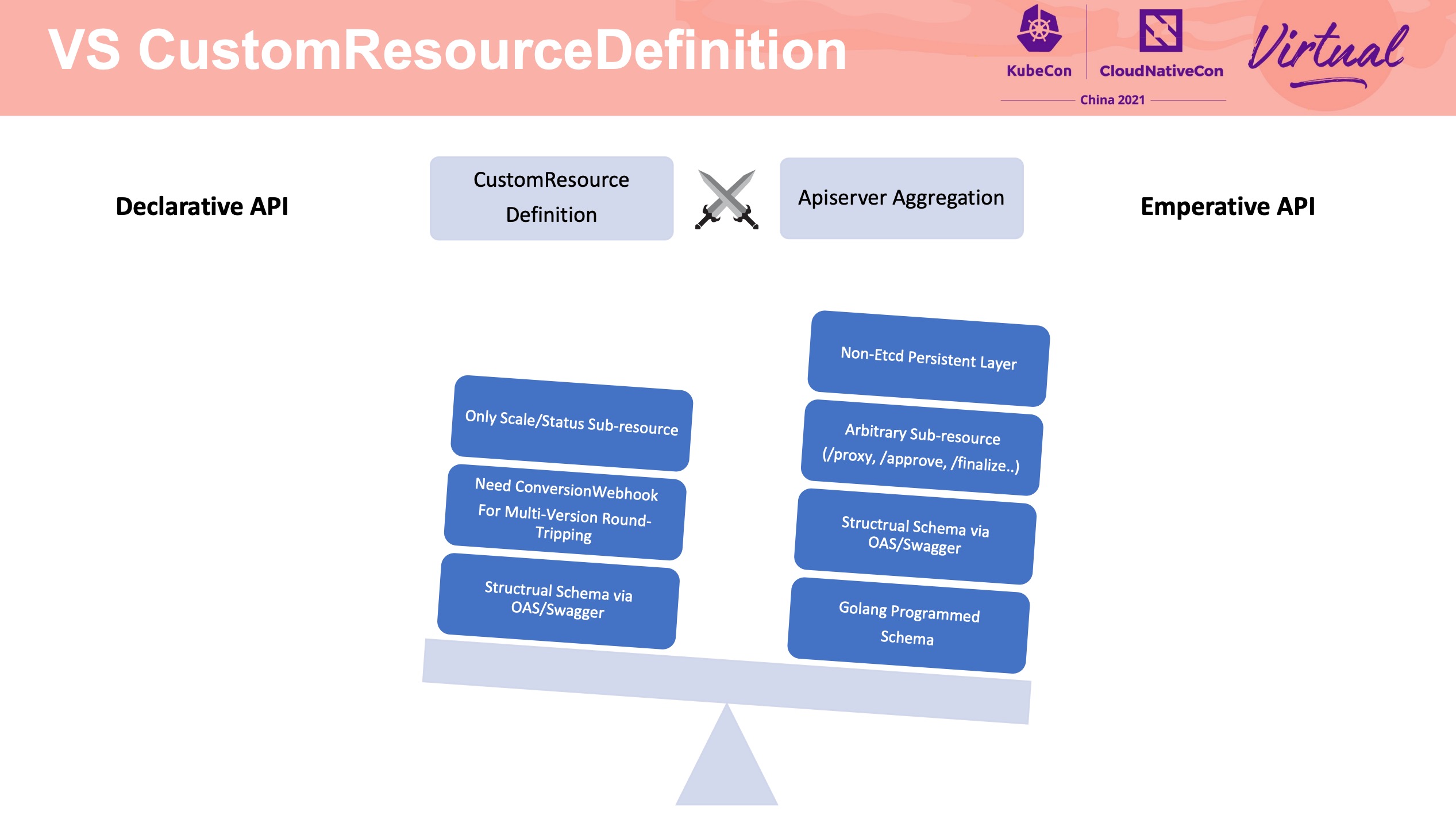



Apiserver Aggregation 的相关资料似乎并不多,但其实 CRD 数量多到一定程度或者在某些特定场景下,Apiserver Aggregation 还是非常好用的。 Programming Kubernetes 一书中也有一些介绍,可以作为入门资料。
Zero Trust Network Turnkey Solution to Support Zero Trust Service Mesh
在混合网络场景(办公网 + 私有云 + 多个公有云 + 外部用户)下会很有落地场景。
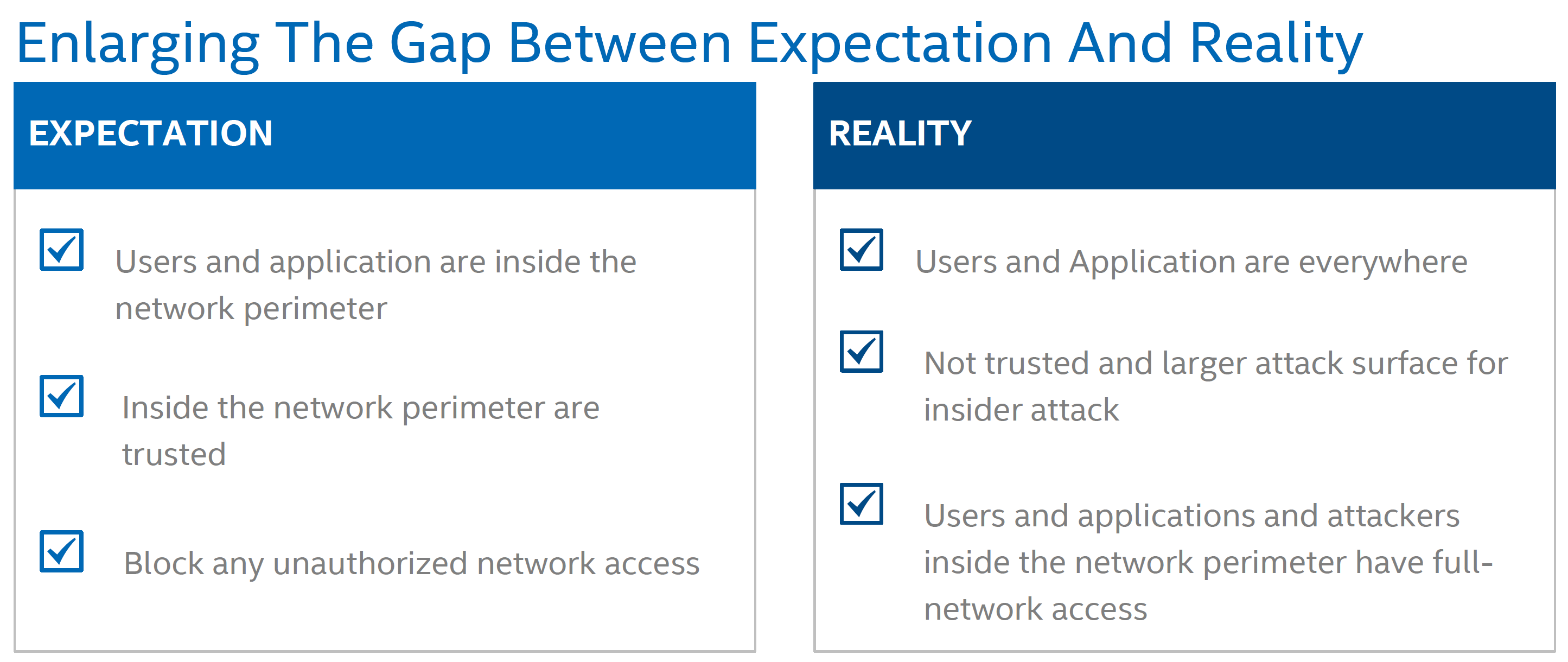


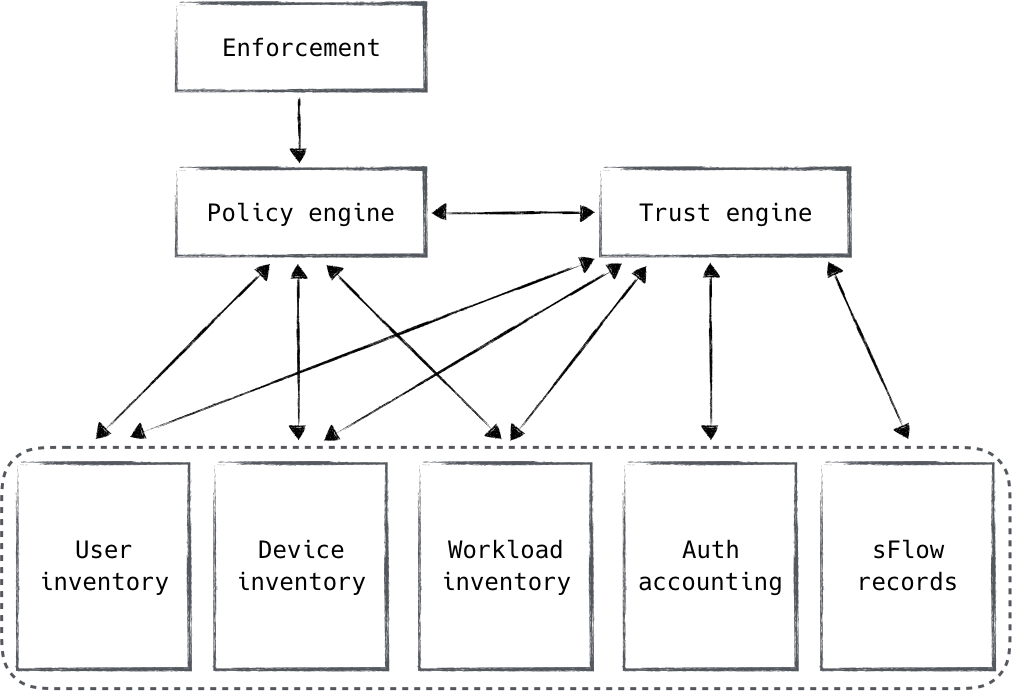
具体可参考 Zero Trust Networks 一书,有中文版。
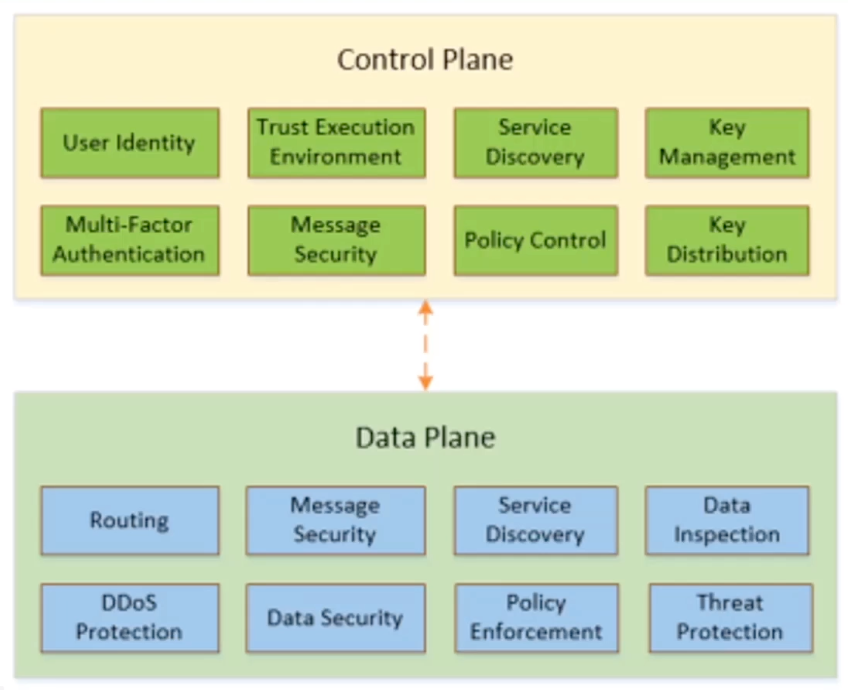
引用 Zero Trust Networks 书中的一张图可能更具有指导意义吧。
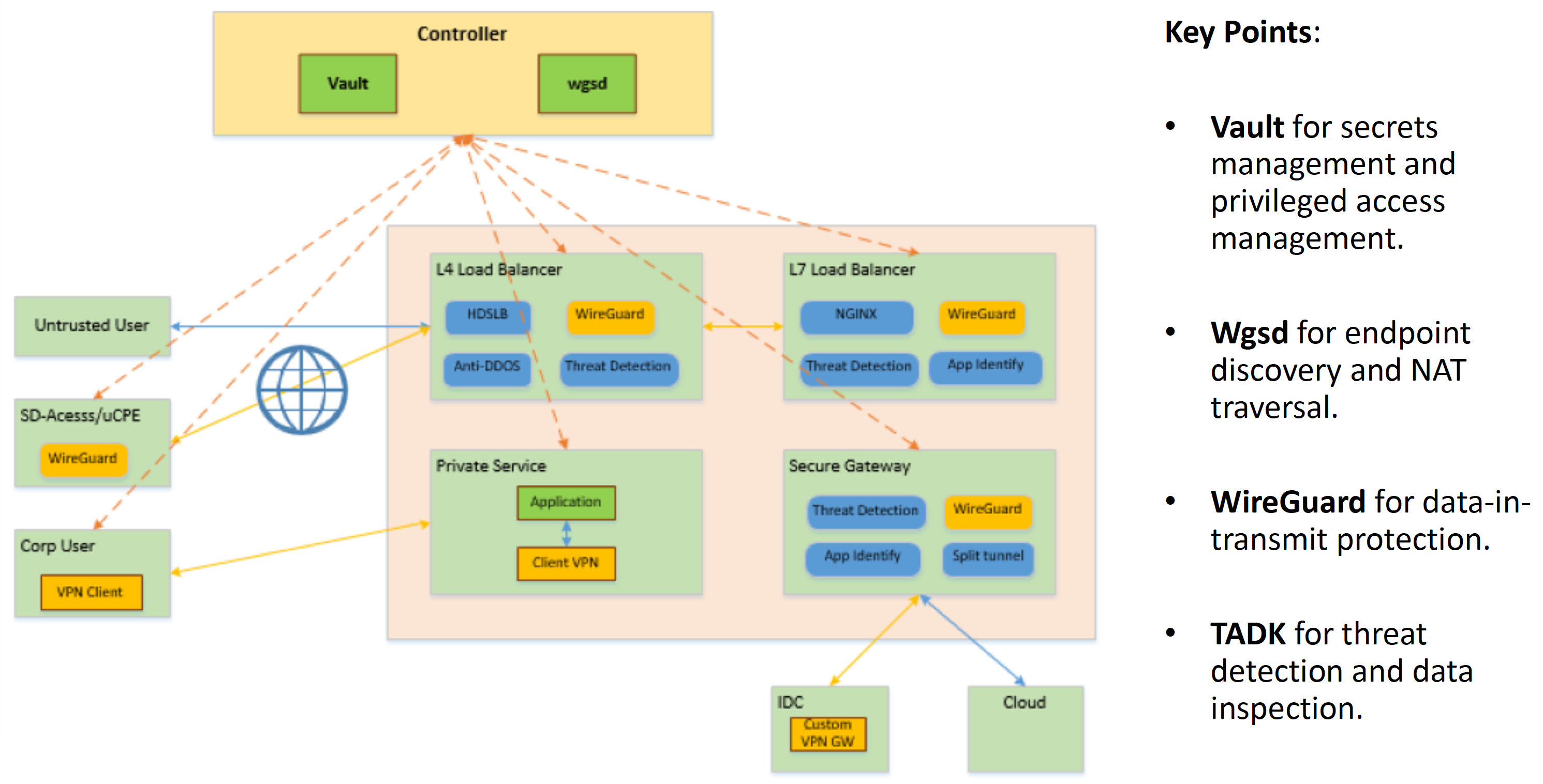
Secure Gateway 架构
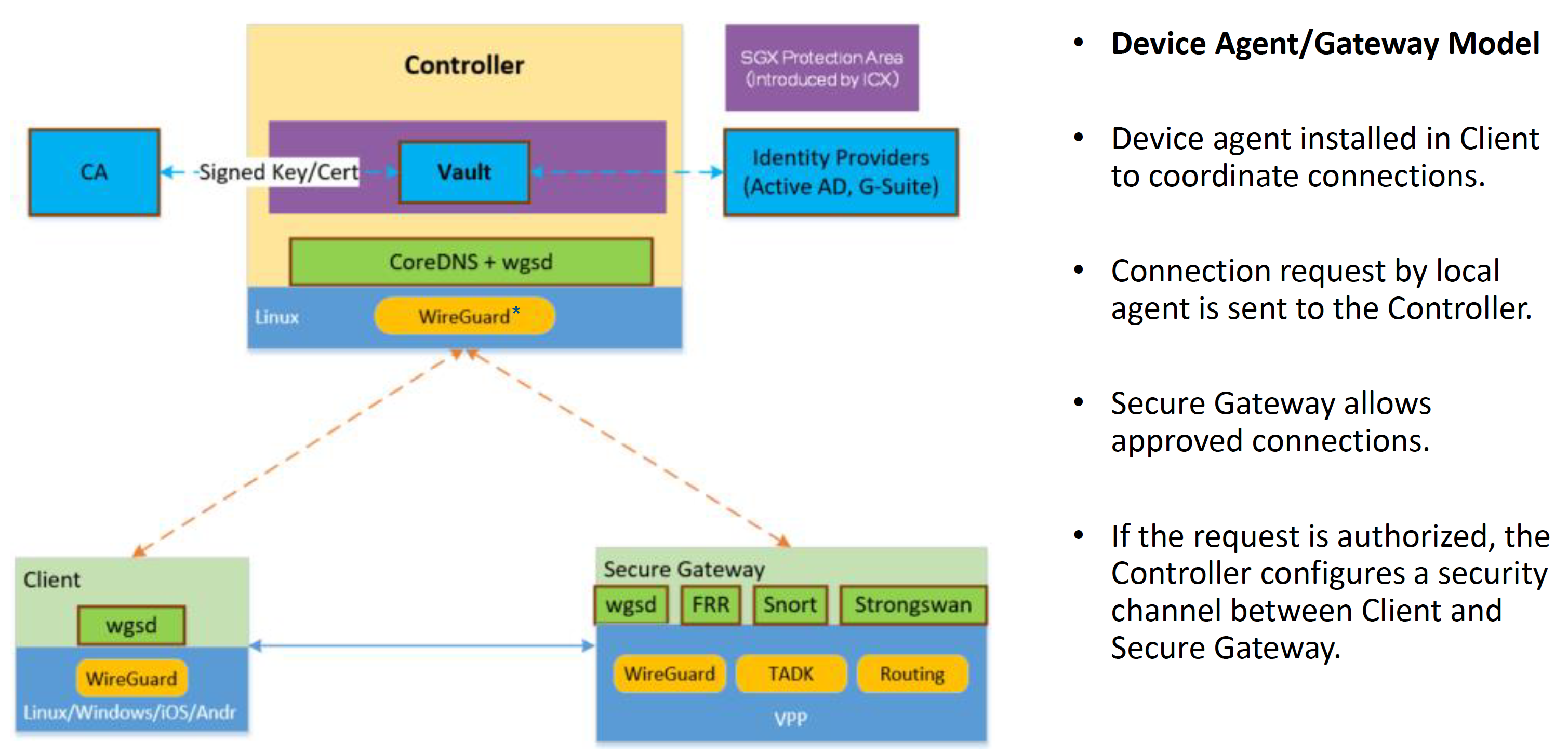
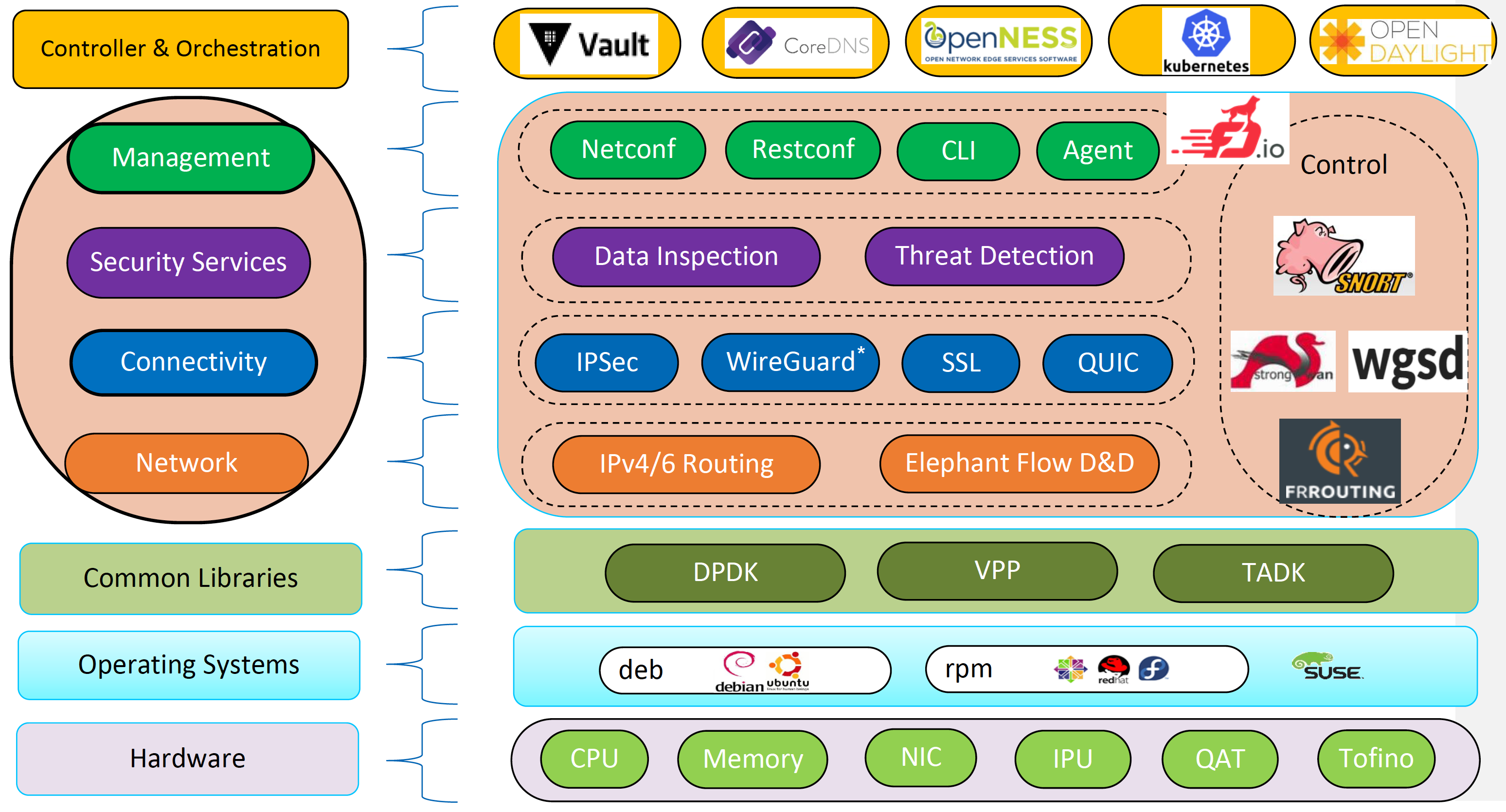
看起来整套架构也是软硬结合了,没有一个团队做支撑,想要快速落地类似架构可以说是没太大可能了。
Ingress Load Balancer 架构
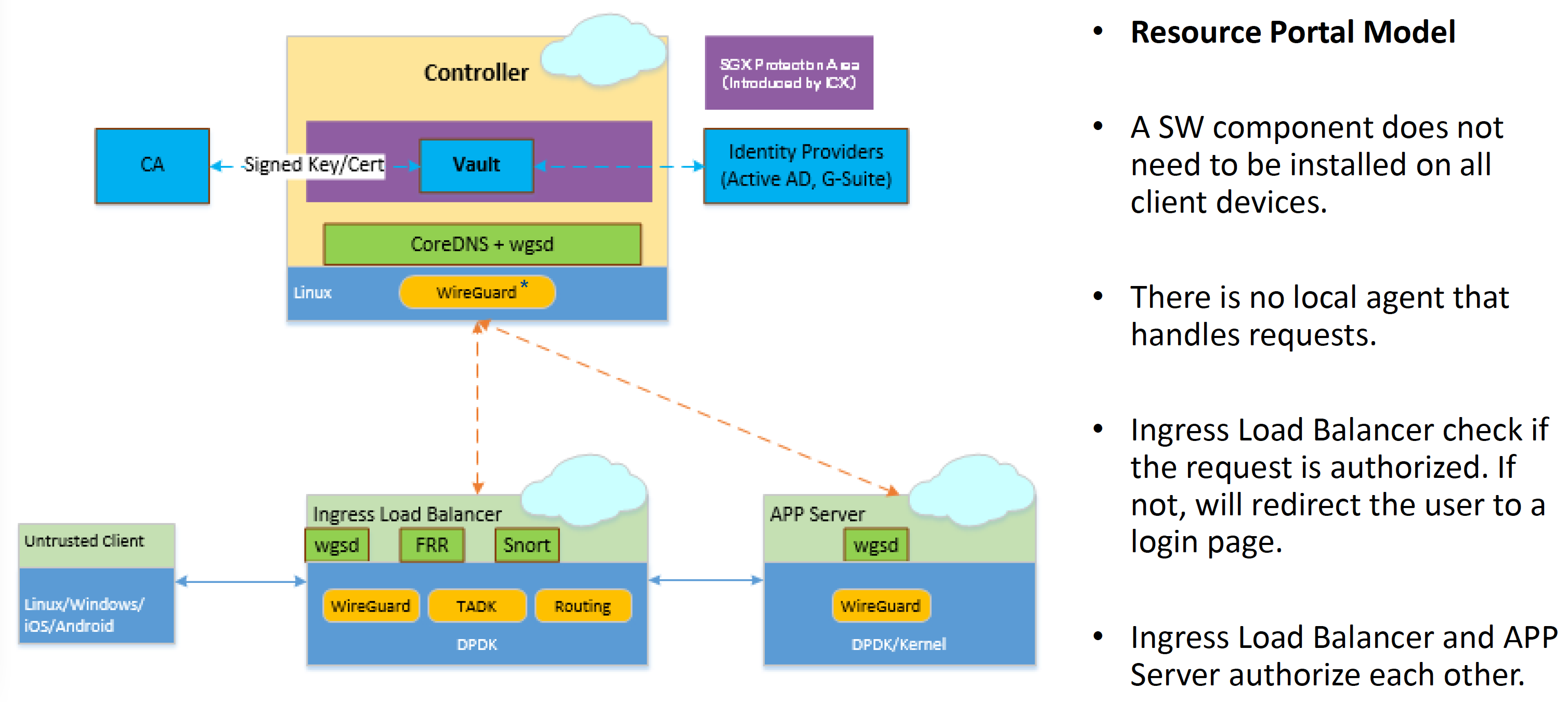
主流的几个 Ingress Controller 应该还都不支持 WireGuard。 也未见有相关的通用方案?

在 LB、Gateway 中集成 WireGuard 是否是最佳实践?
不过把 WireGuard 和 DPDK 做到一块倒是一个新思路,包括结合 QAT 卡、宽指令集等,充分利用硬件做 offload 了属于是。
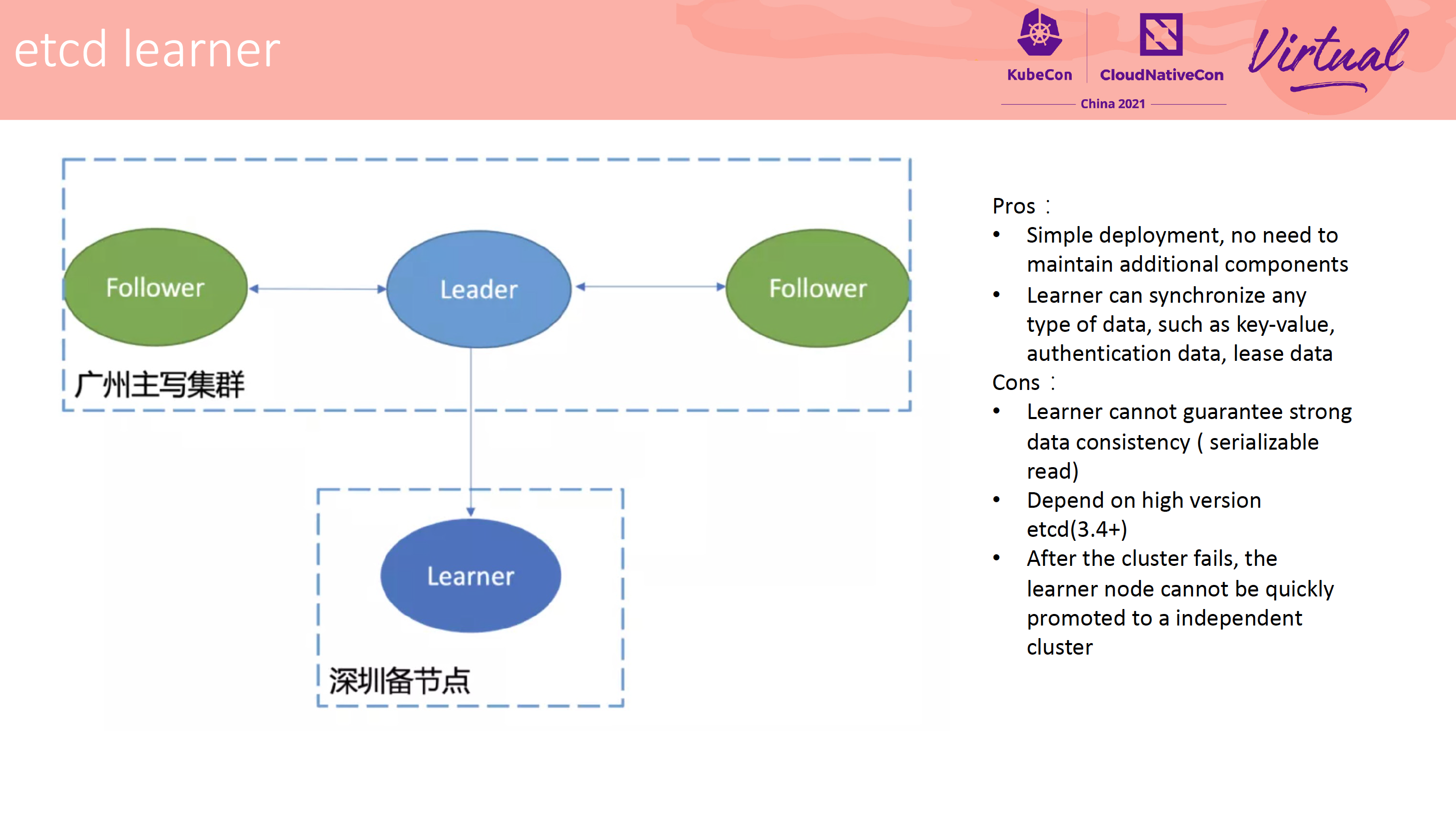
How to Efficiently Manage Tens of Thousands of etcd Clusters
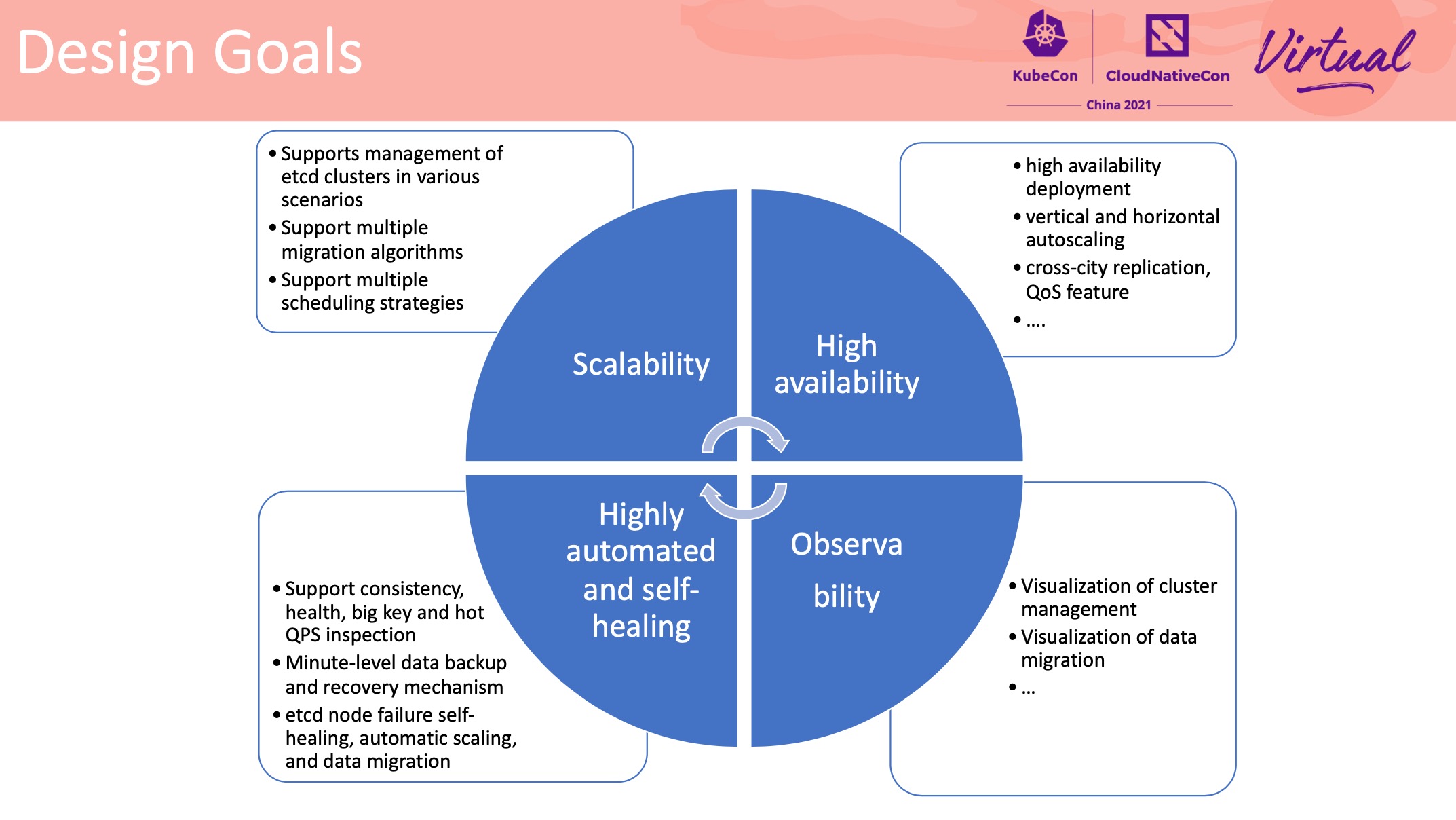
kstone
无巧不成书,腾讯 Etcd 管控工具也是基于 Apiserver Aggregation。
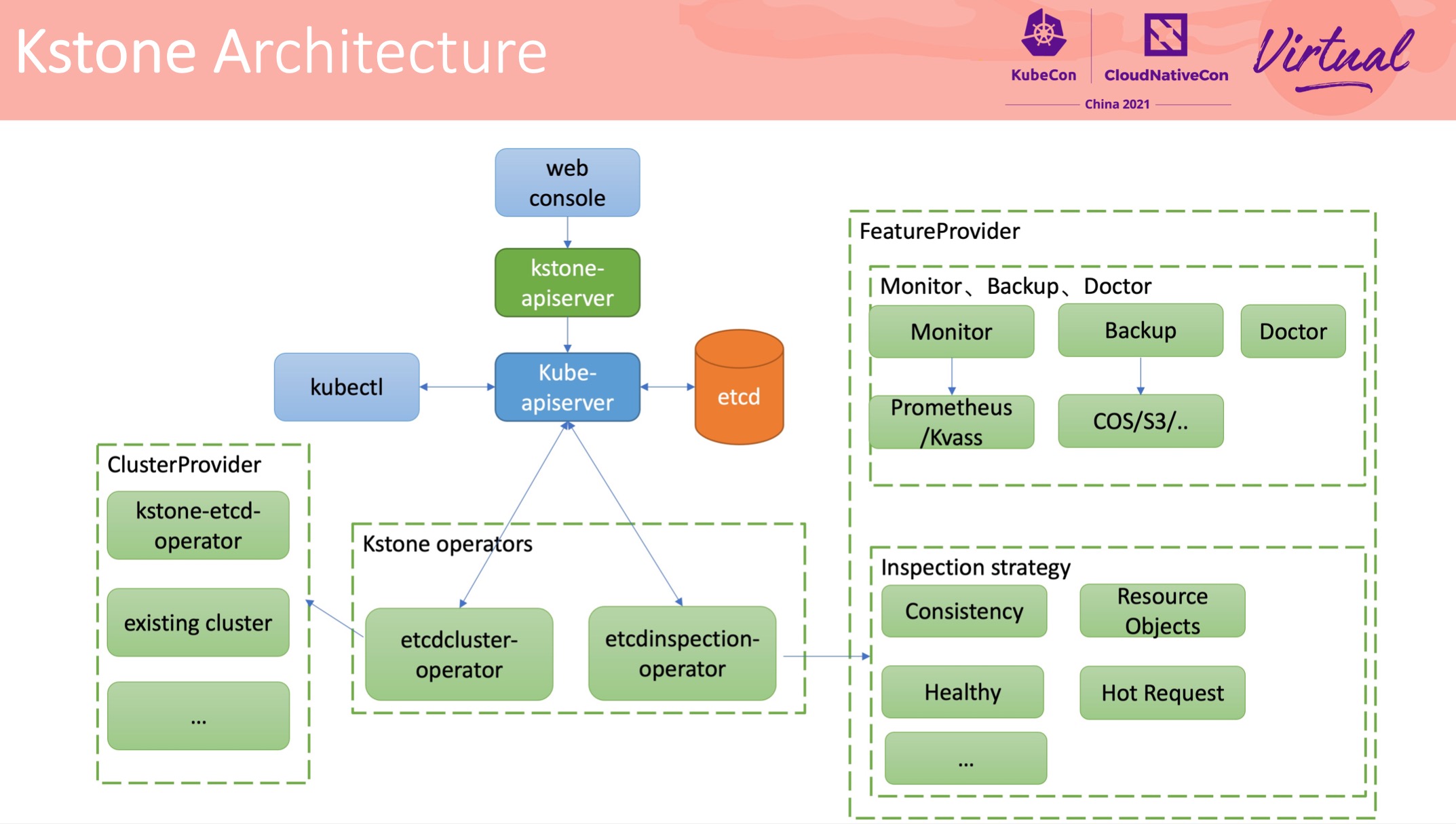

迁移过程中这种版本依赖路径还是很有意义的。
腾讯这个项目已经开源了: https://github.com/tkestack/kstone。
kstone-etcd-operator


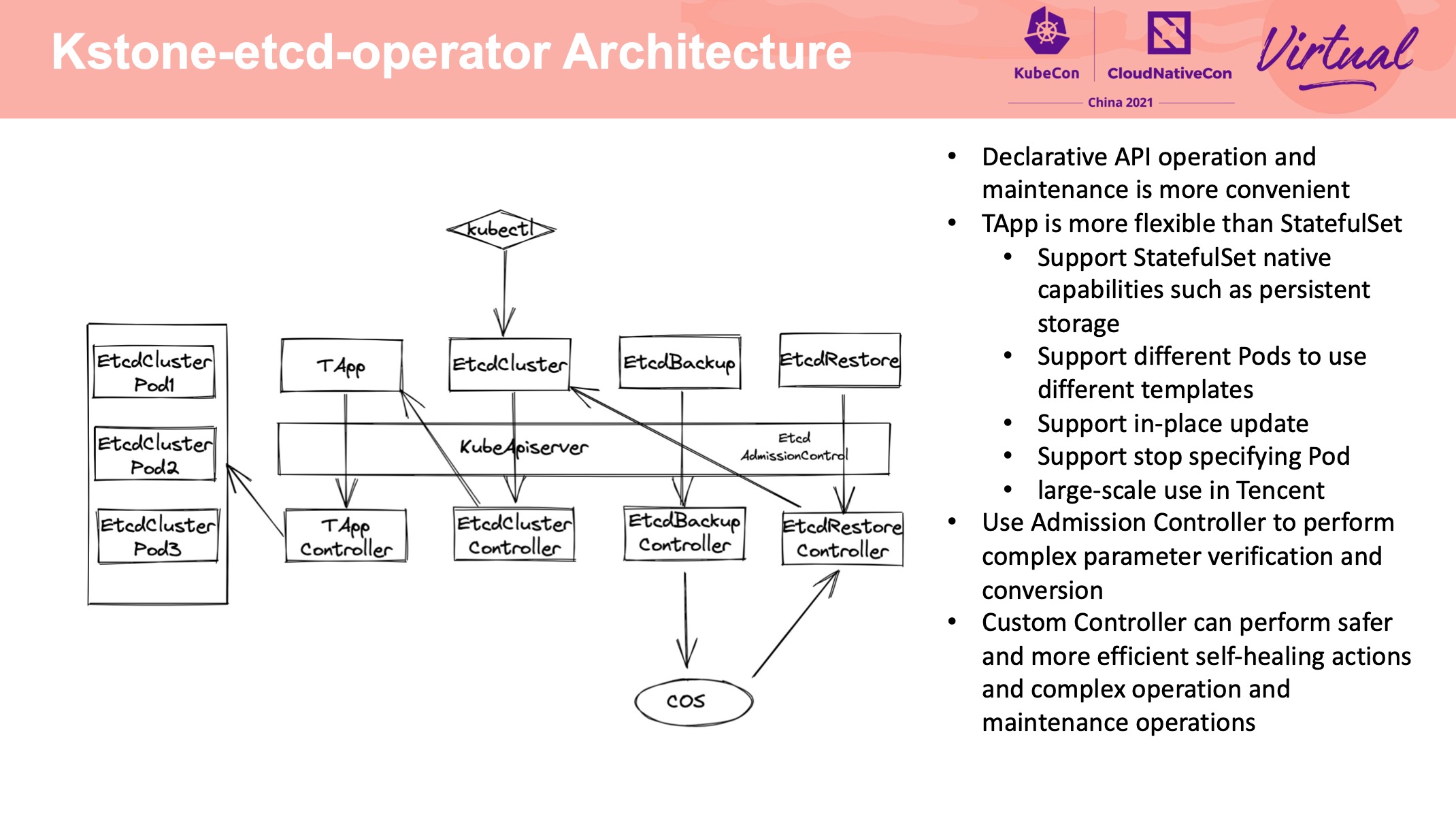
正经做 Operator 都是抛弃 StatefulSet,自己造轮子。

这个 Operator 用的是 TAPP: https://github.com/tkestack/tapp
没有使用裸 Pod 主要是基于存储易用性上的考量。 但我感觉没差多少。
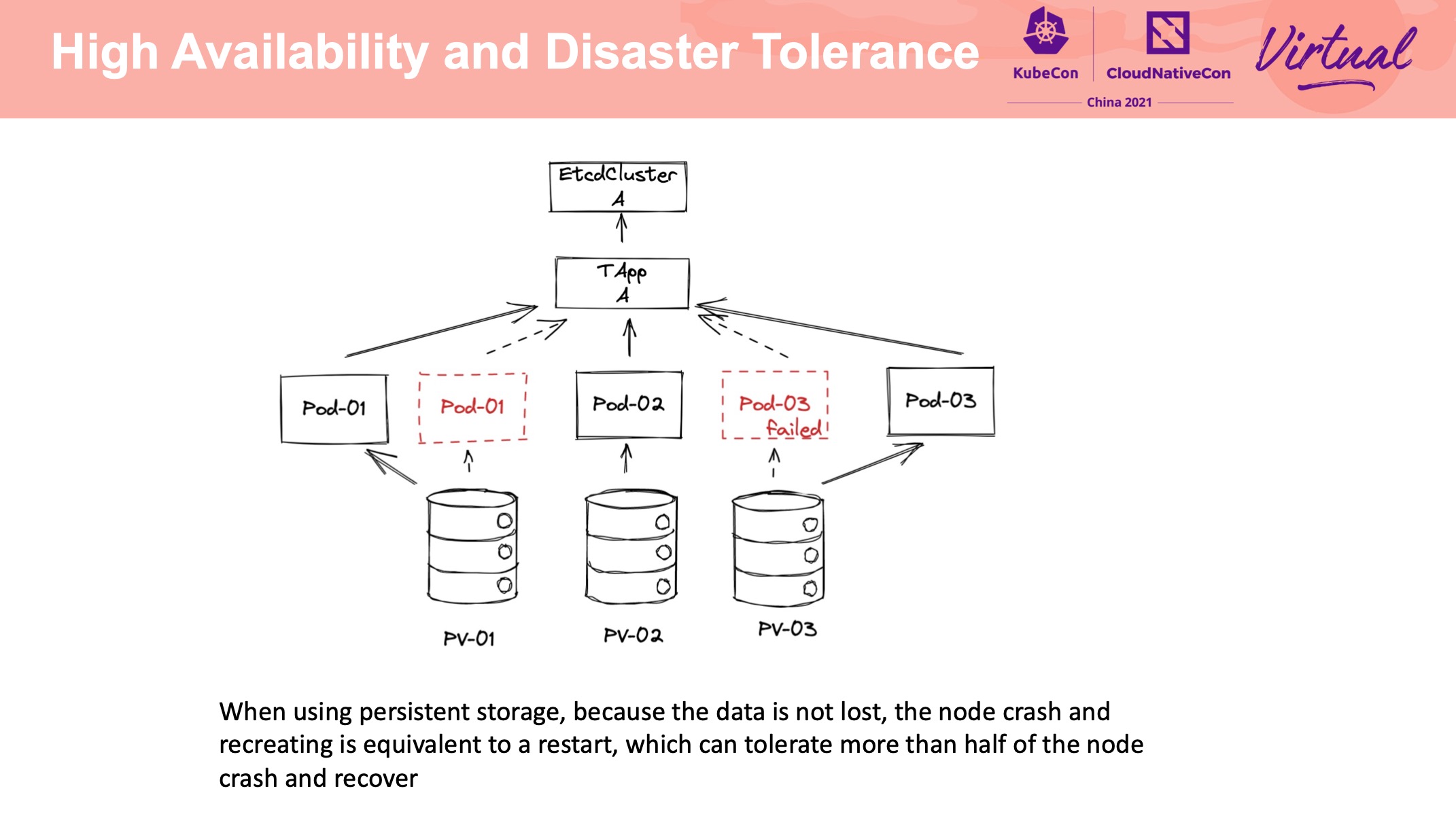
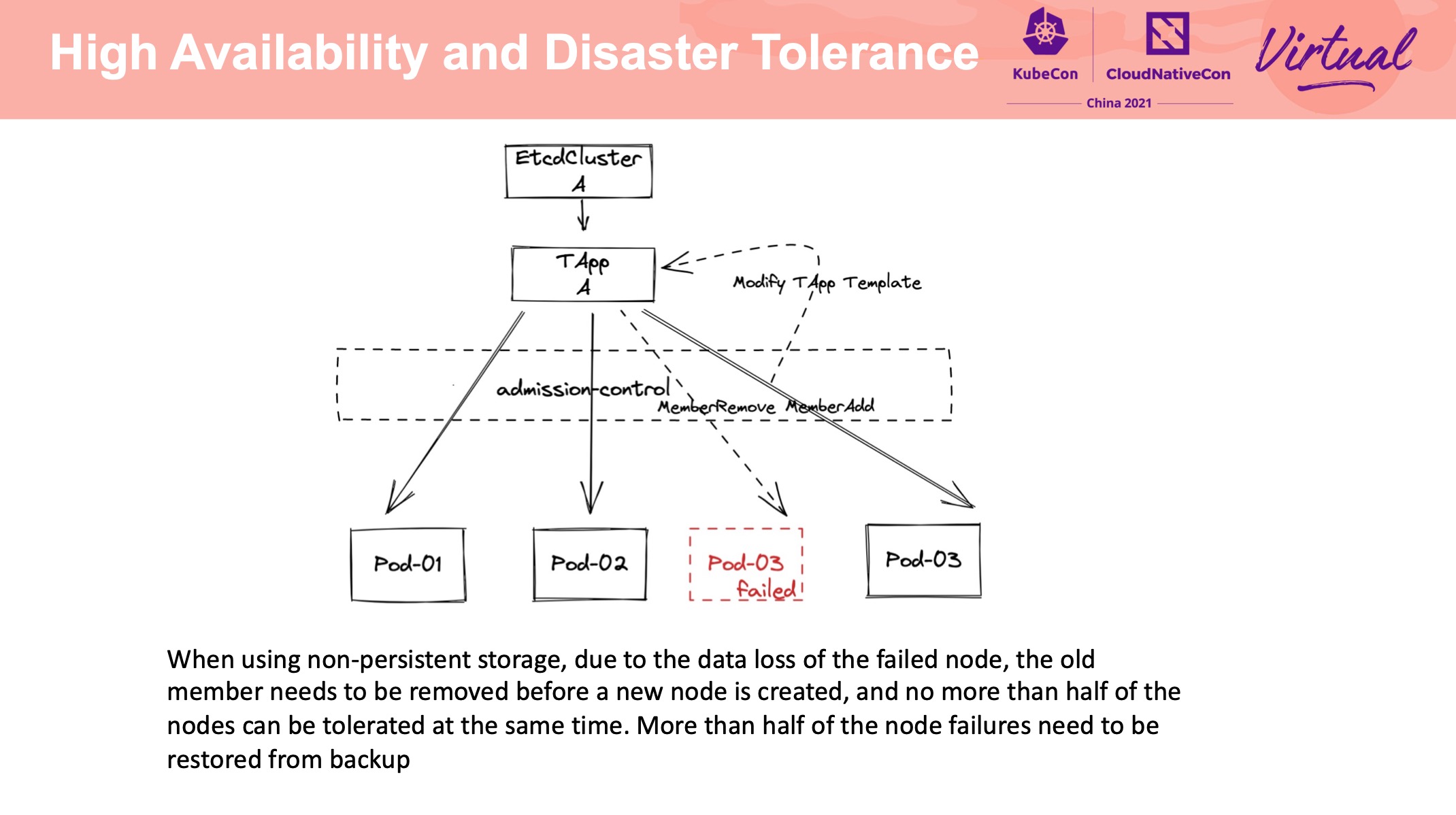
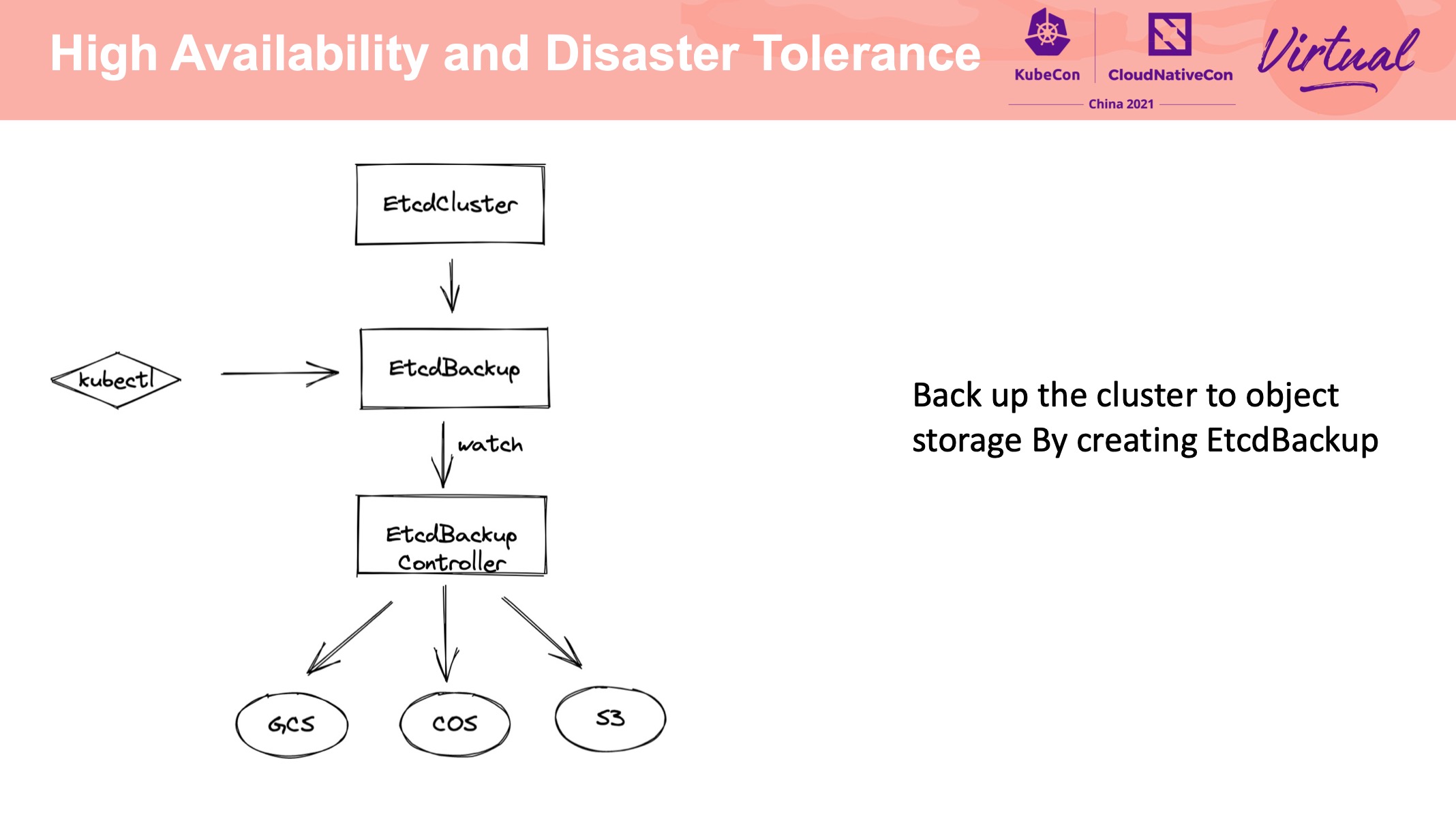
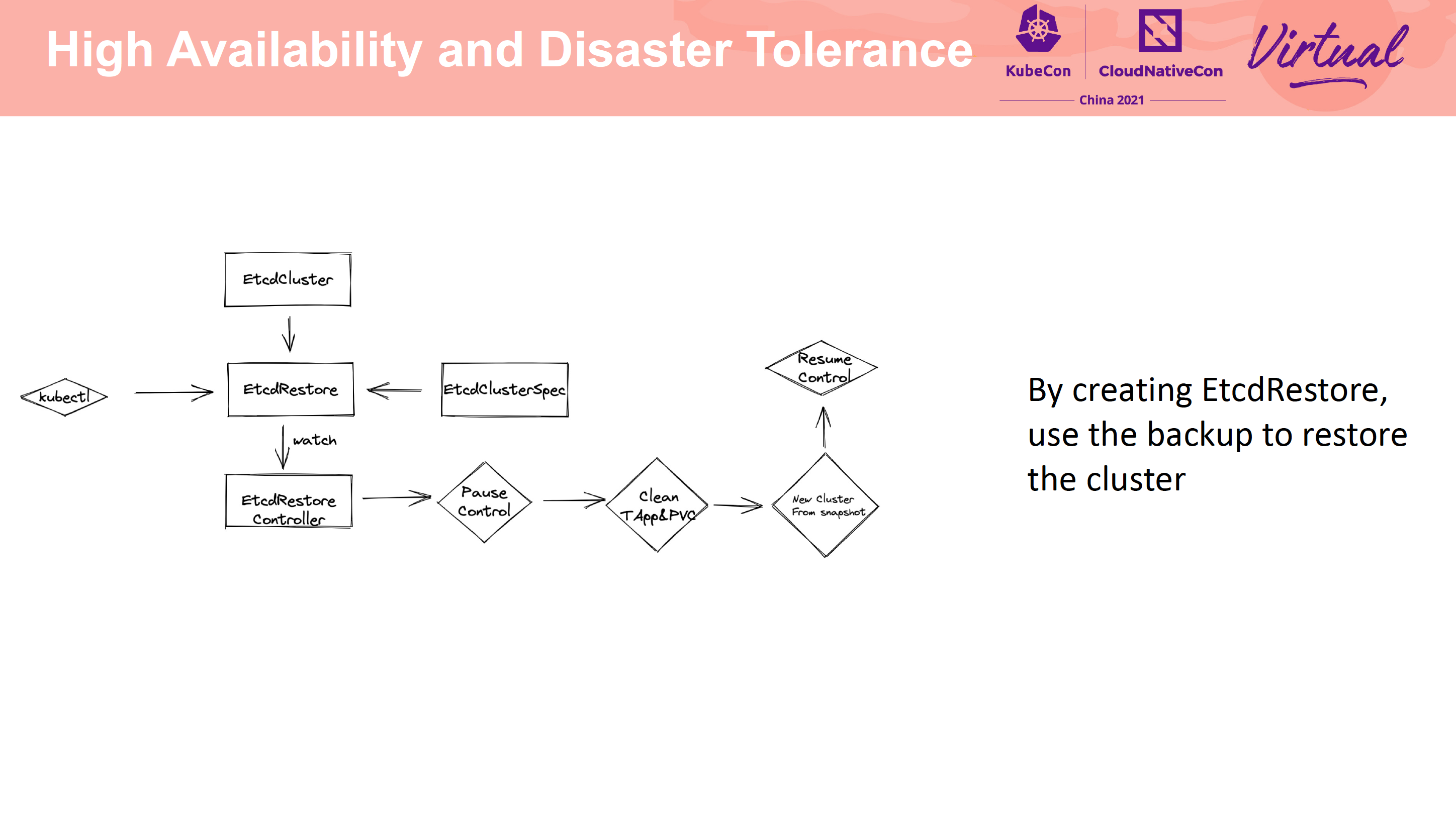
支持备份到不同类型的存储介质中还是比较有价值的。
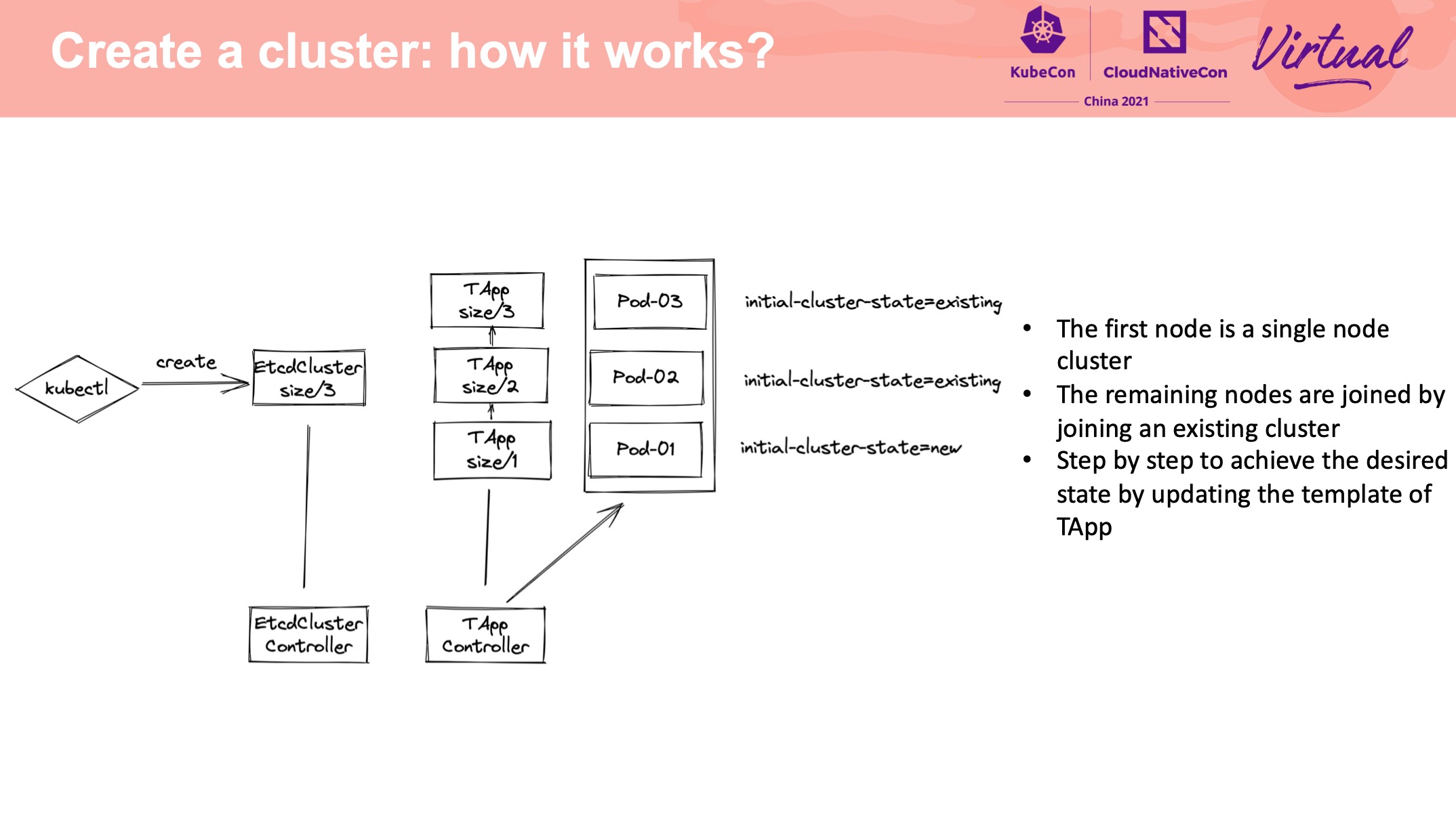
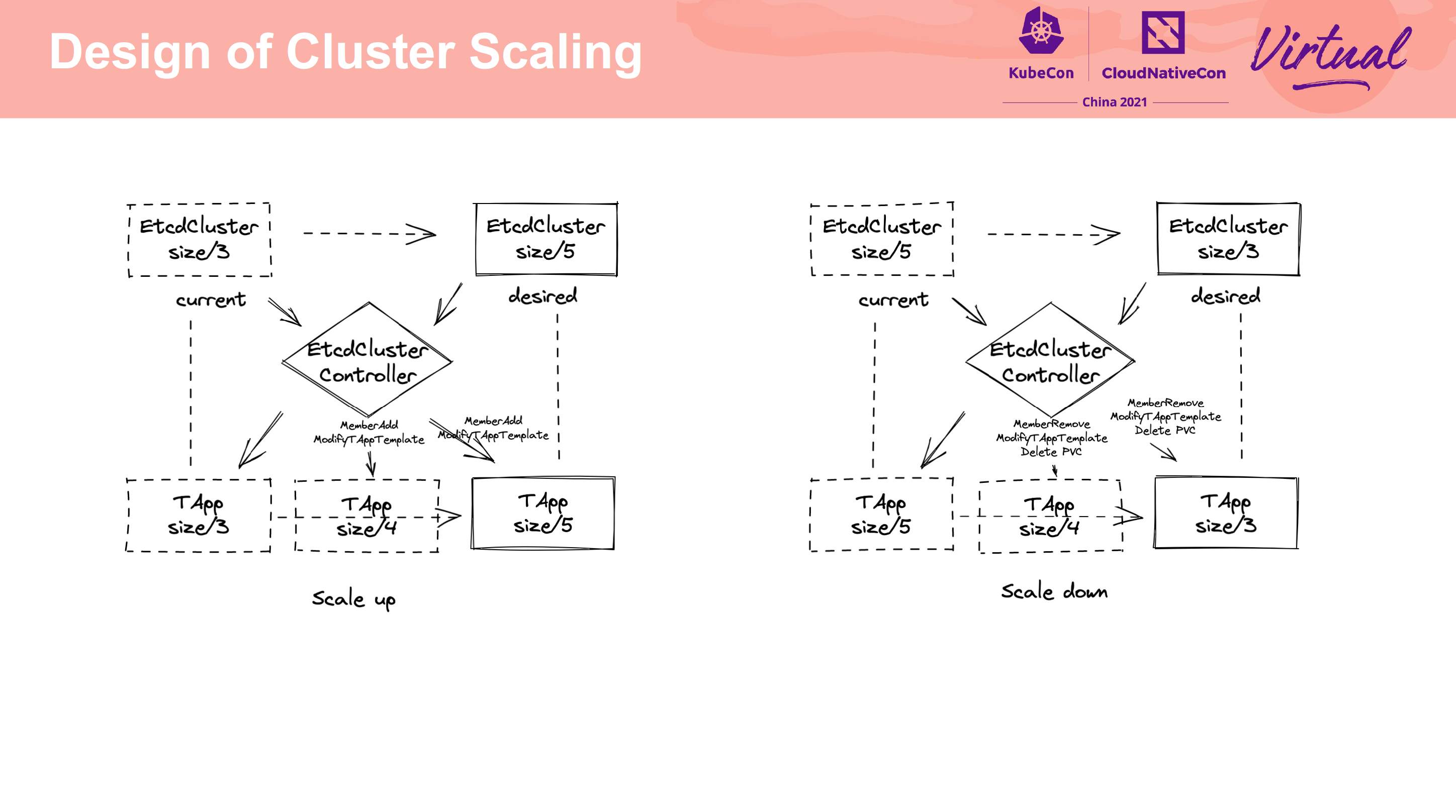
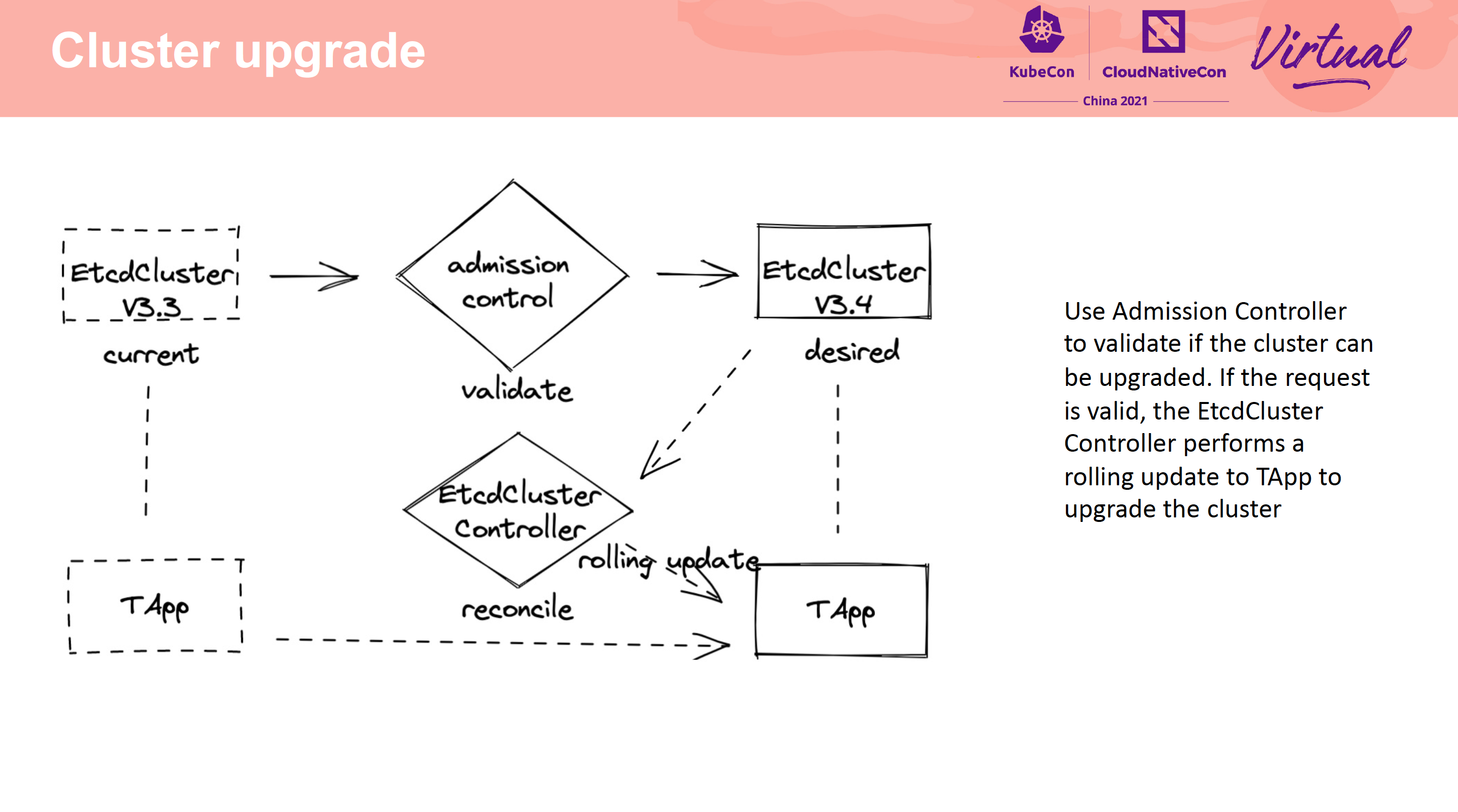
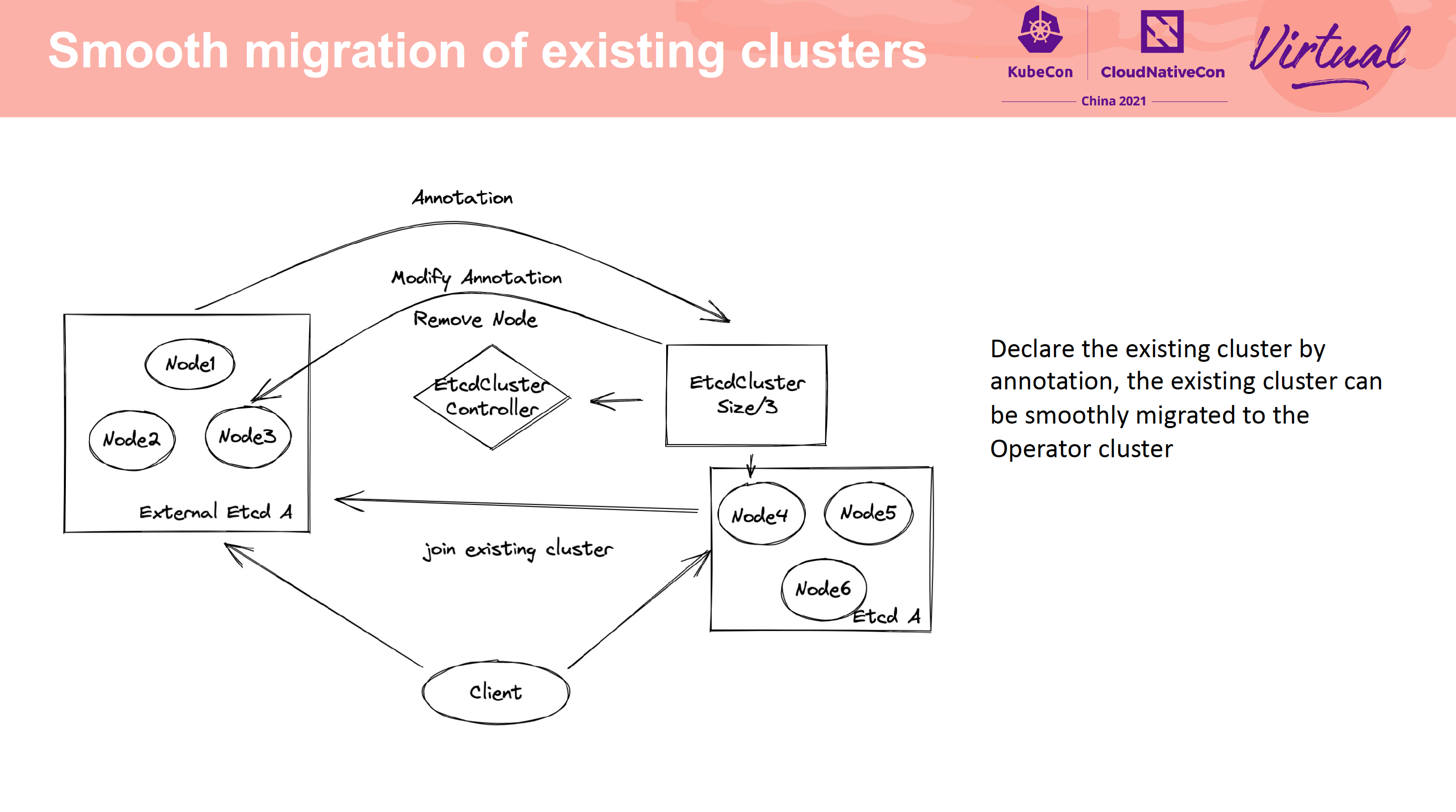
Cross-city hot backup and QoS feature practice
该部分非常落地。

方案 1 的问题主要是跨城读延迟较高。
方案 2 的问题主要是就近读有旧数据、无法快速 failover。
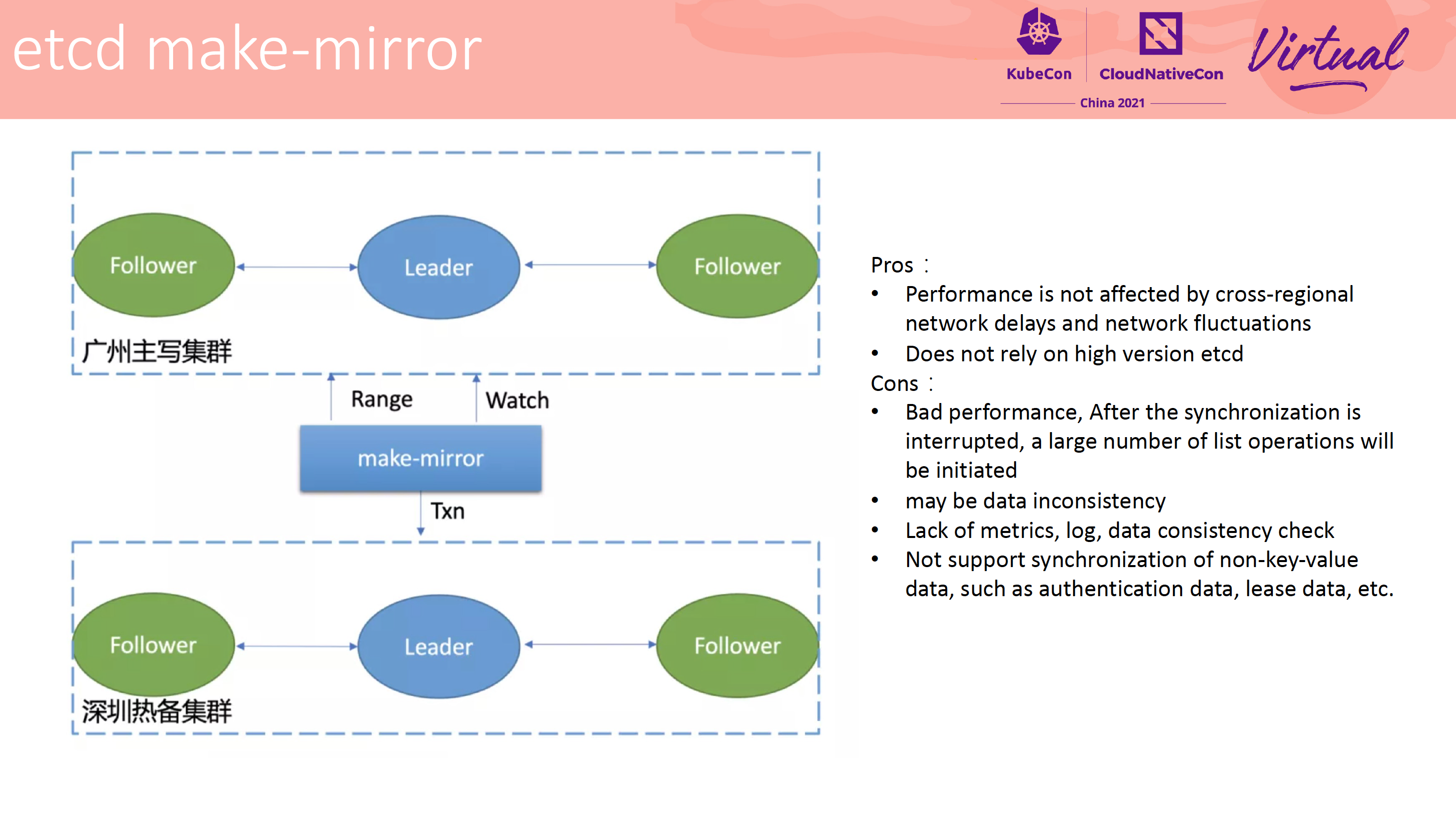
方案 3 的问题主要是性能差、写量大会造成读到脏数据。

方案 4,腾讯基于方案 3 做的加强版。
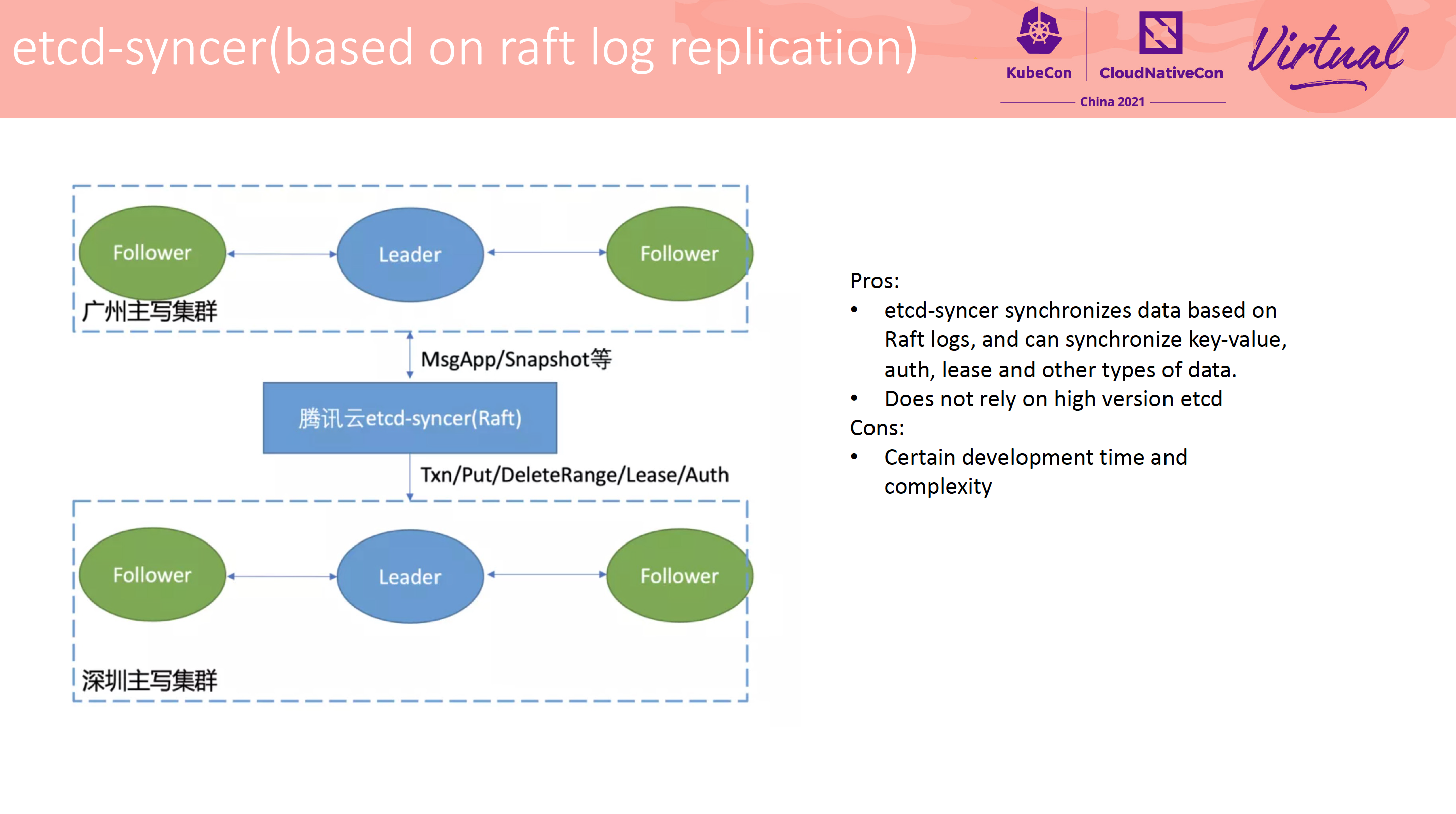
方案 5,将 syncer 节点伪装成 learner 加入集群。
该方案很像字节跳动一次分享上讲的 Kafka 跨地域同步: https://files.alicdn.com/tpsservice/cd9626b87ca646a05f05eb1d1c962126.pdf
InnerSource & DevOps They Are Soul Mates
谭老师讲的关于 InnerSource 的 Session。 非常推荐观看。


写代码很重要,而写代码之前知道自己要写什么更重要,这句话真是太棒了。
Deep Dive Into Profilers How CPU Profilers Measure Your Application’s Performance
CPU Profile 是可以获取当前函数消耗了多少 CPU 比例的工具。
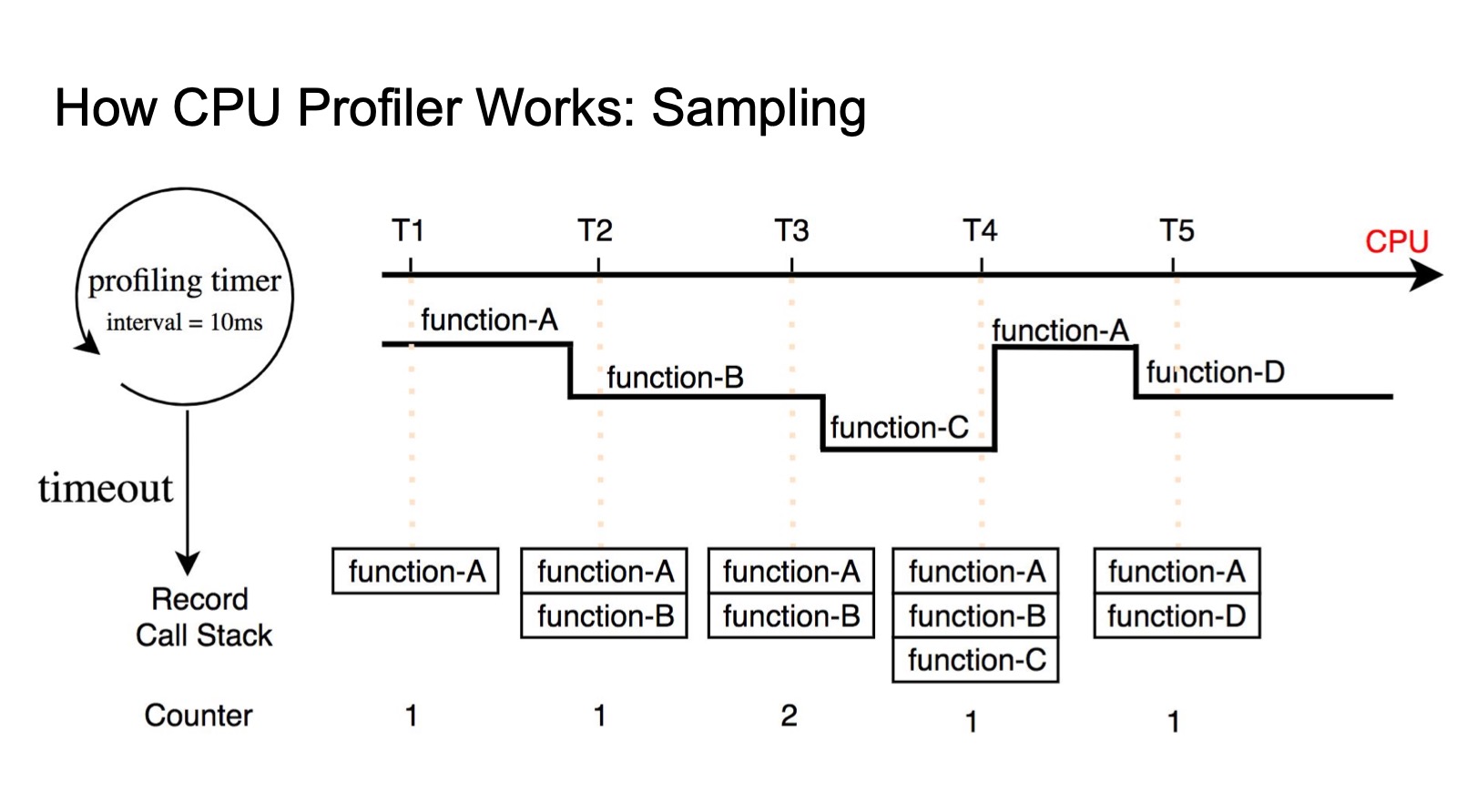


CPU Profile 工具适合对代码做性能调优、线上出现故障的时候。
CPU Profile 工具容易漏掉执行速度快且执行次数少的函数,对 CPU 负载并不高但 CPU hang 住在等待网络或者磁盘 I/O 的程序。
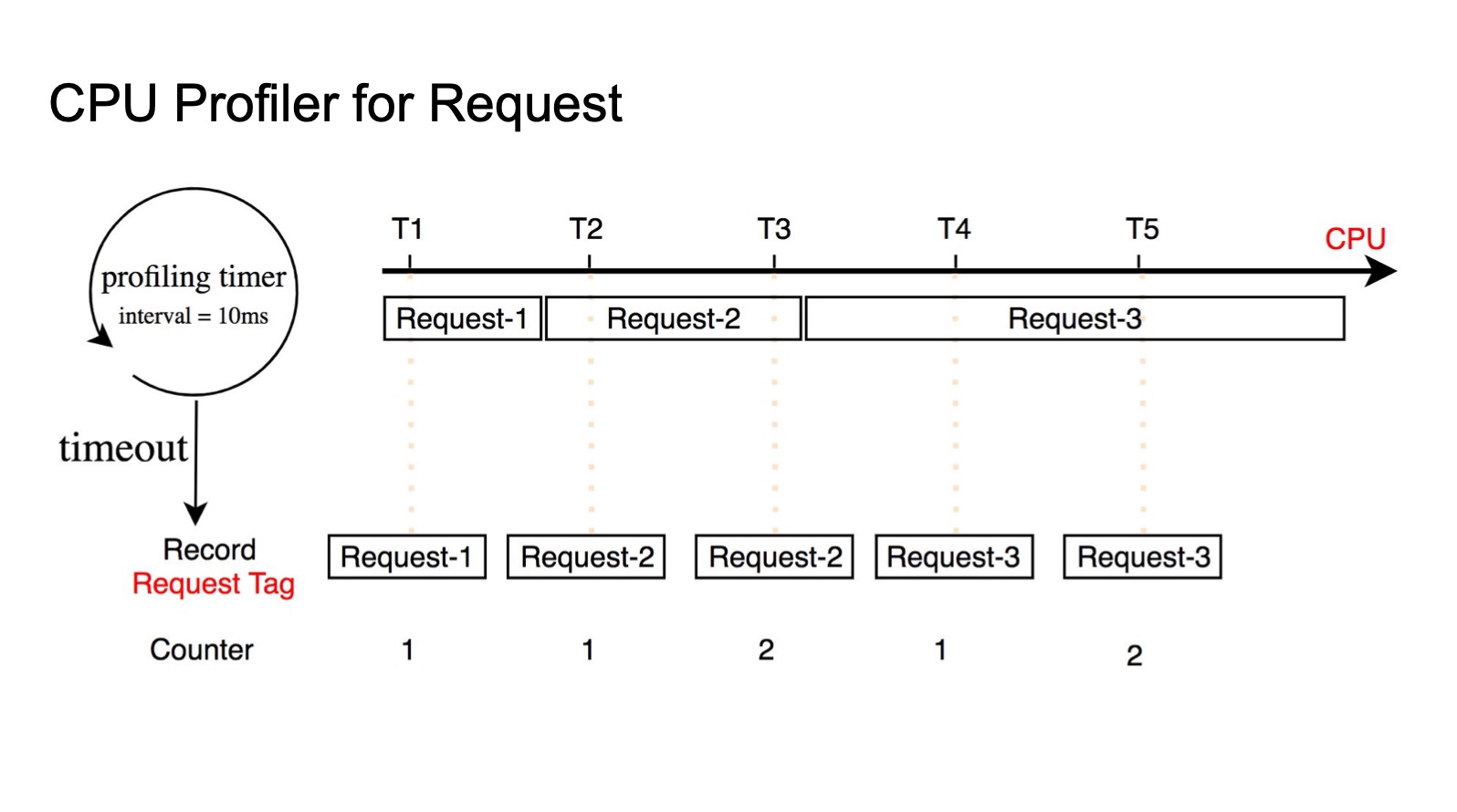

为什么不在函数开始执行和结束执行的时候记录时间戳,然后相减?
- 函数执行流程并不都在使用 CPU,比如陷入中断等待 I/O 等(请求处理时间不等于 CPU 消耗时间)
- 没有办法保证实时性
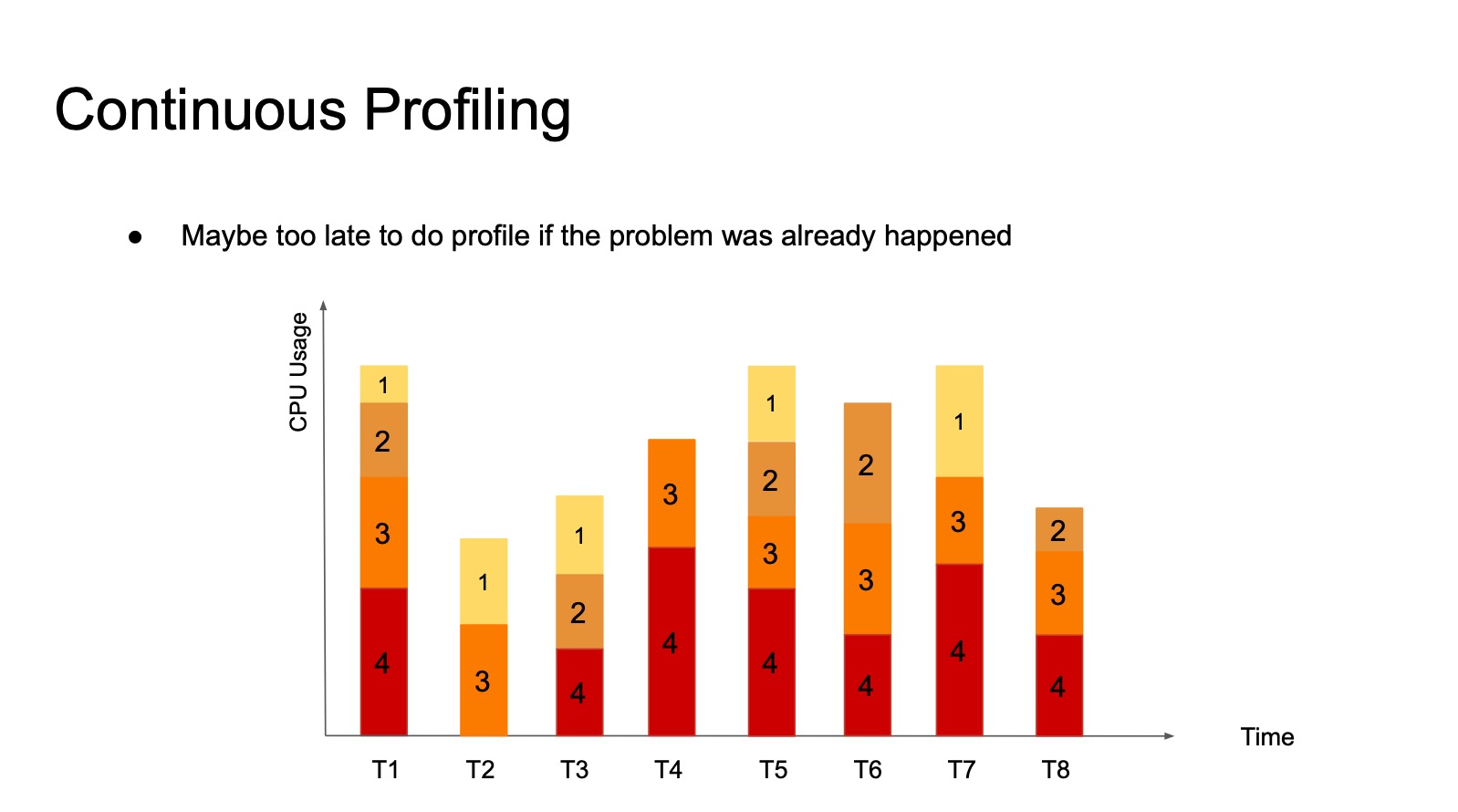
事后做 CPU Profile 会有点晚,需要持续采集 CPU Profile。
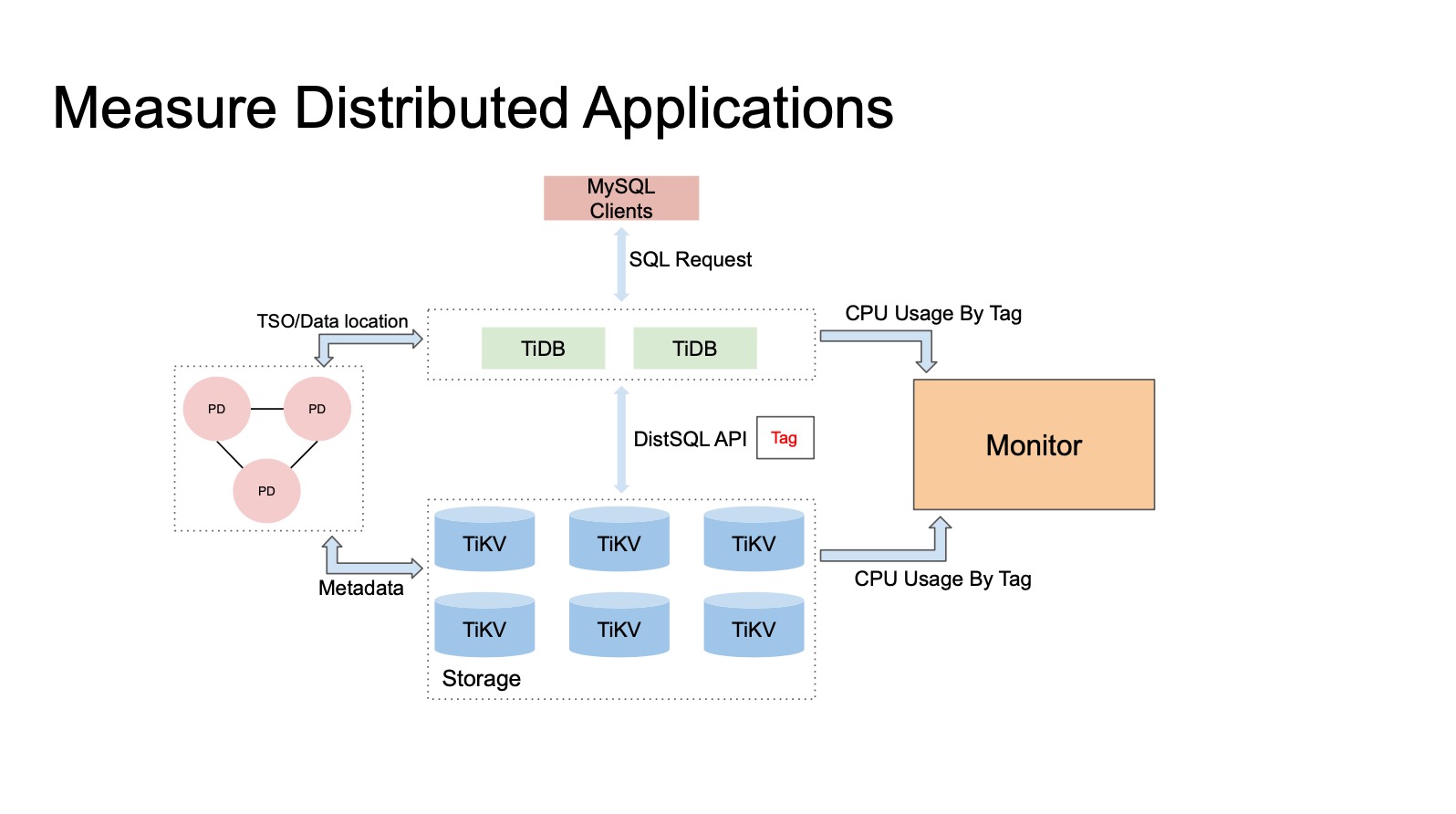
通过 Tag 来做分布式 CPU Profile。
Redteam Views Security Practice of K8s Cluster Administrator
通过攻击流程,阐述了 K8s 各个环节应该注意的安全问题。

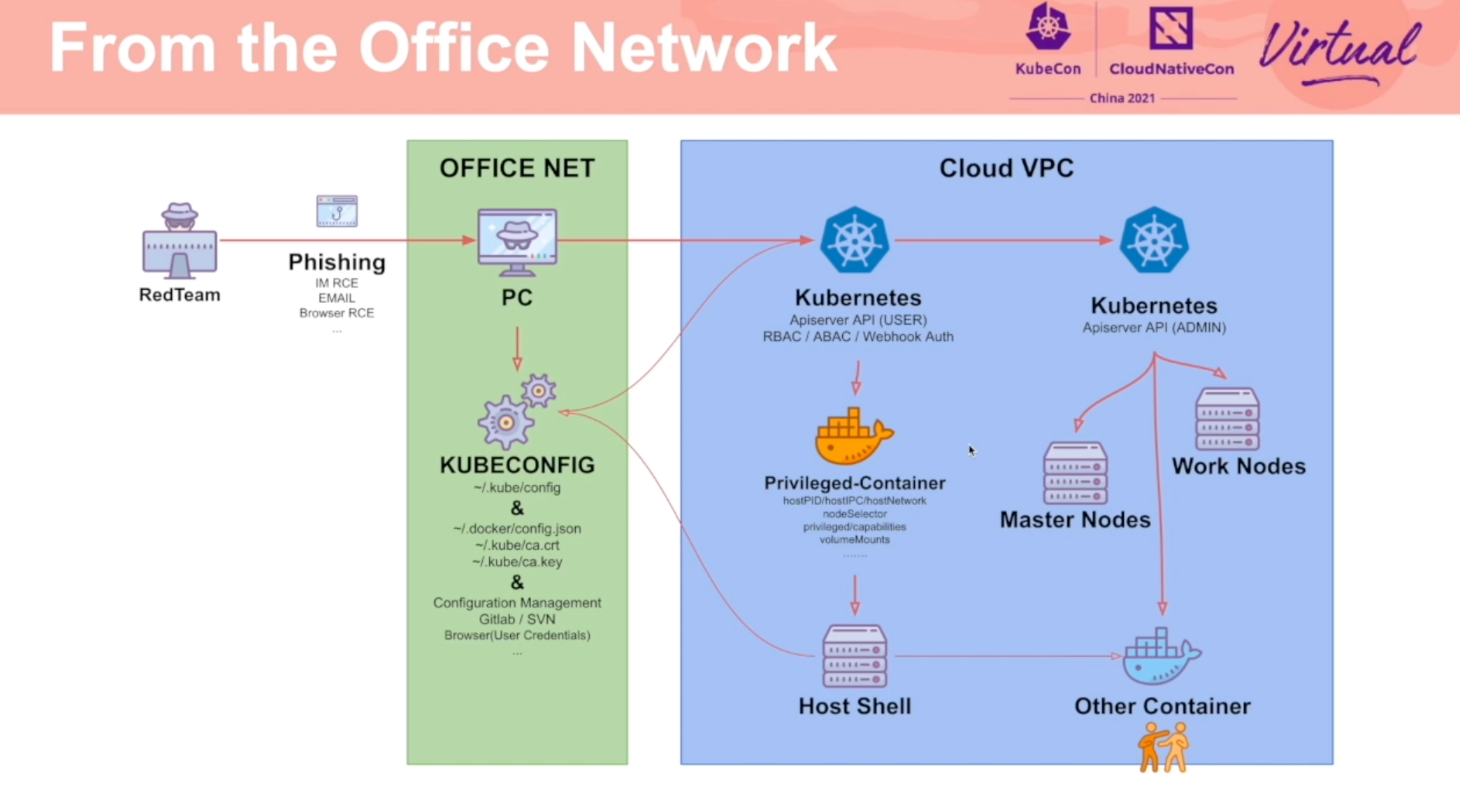
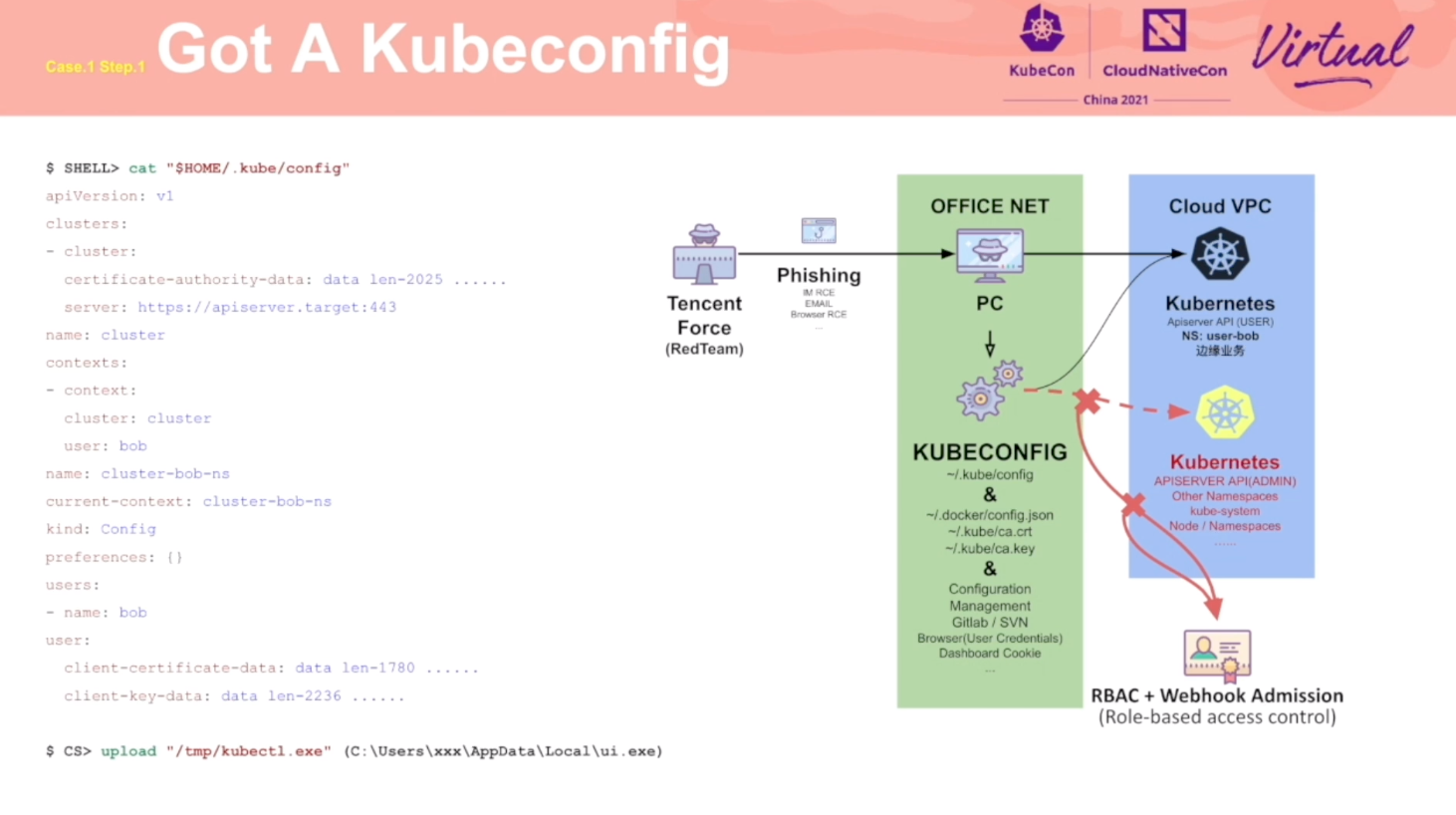

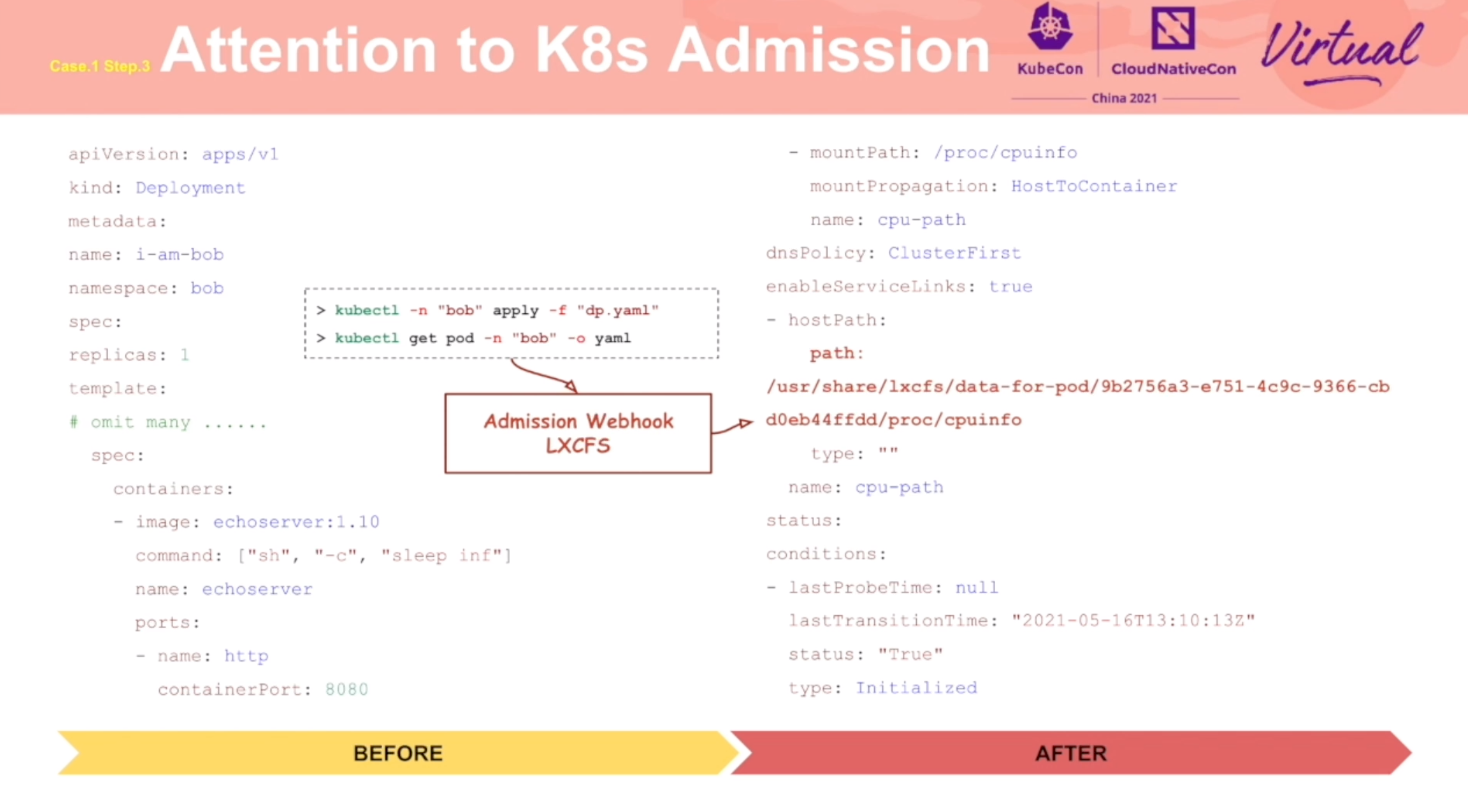

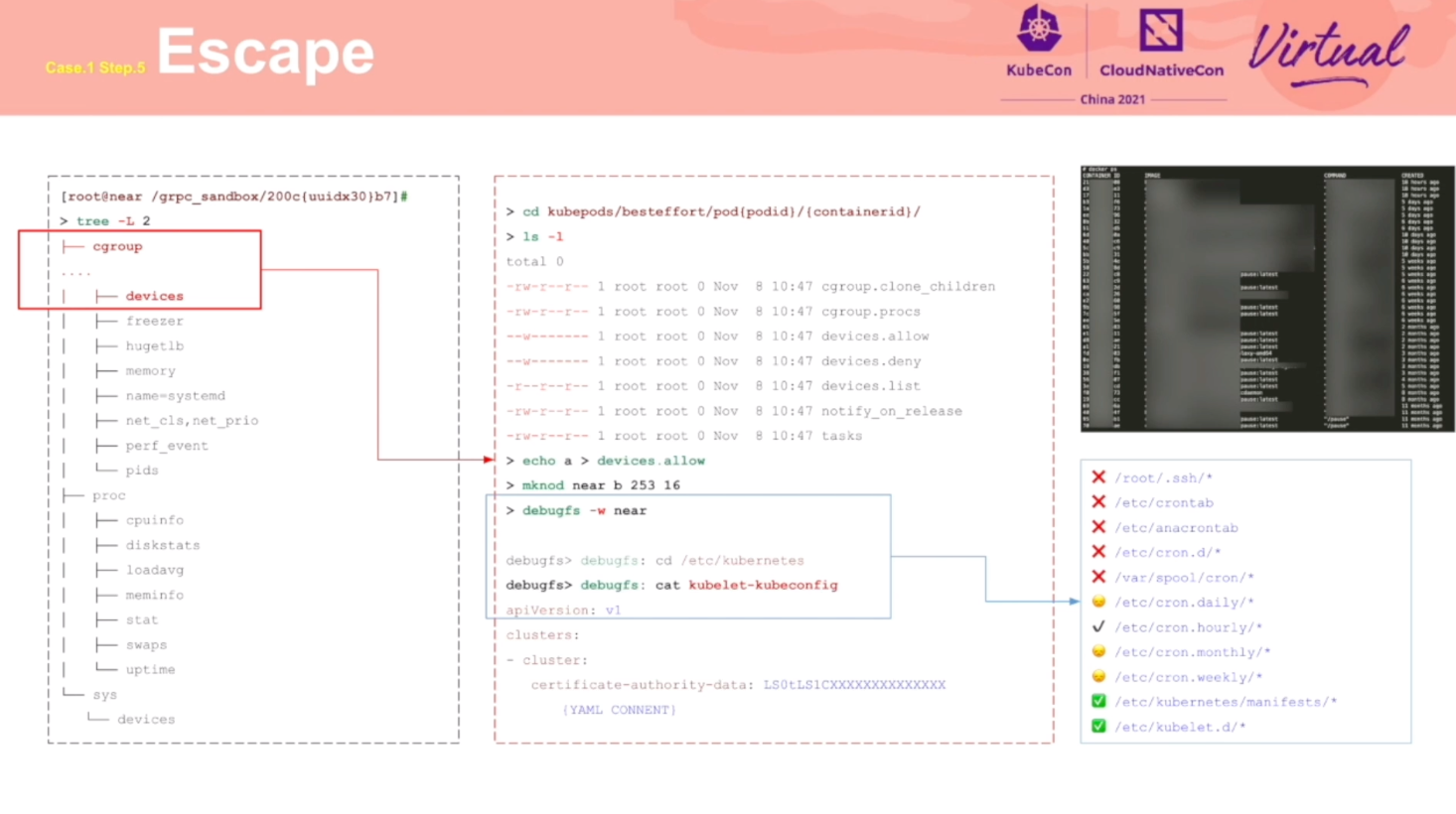
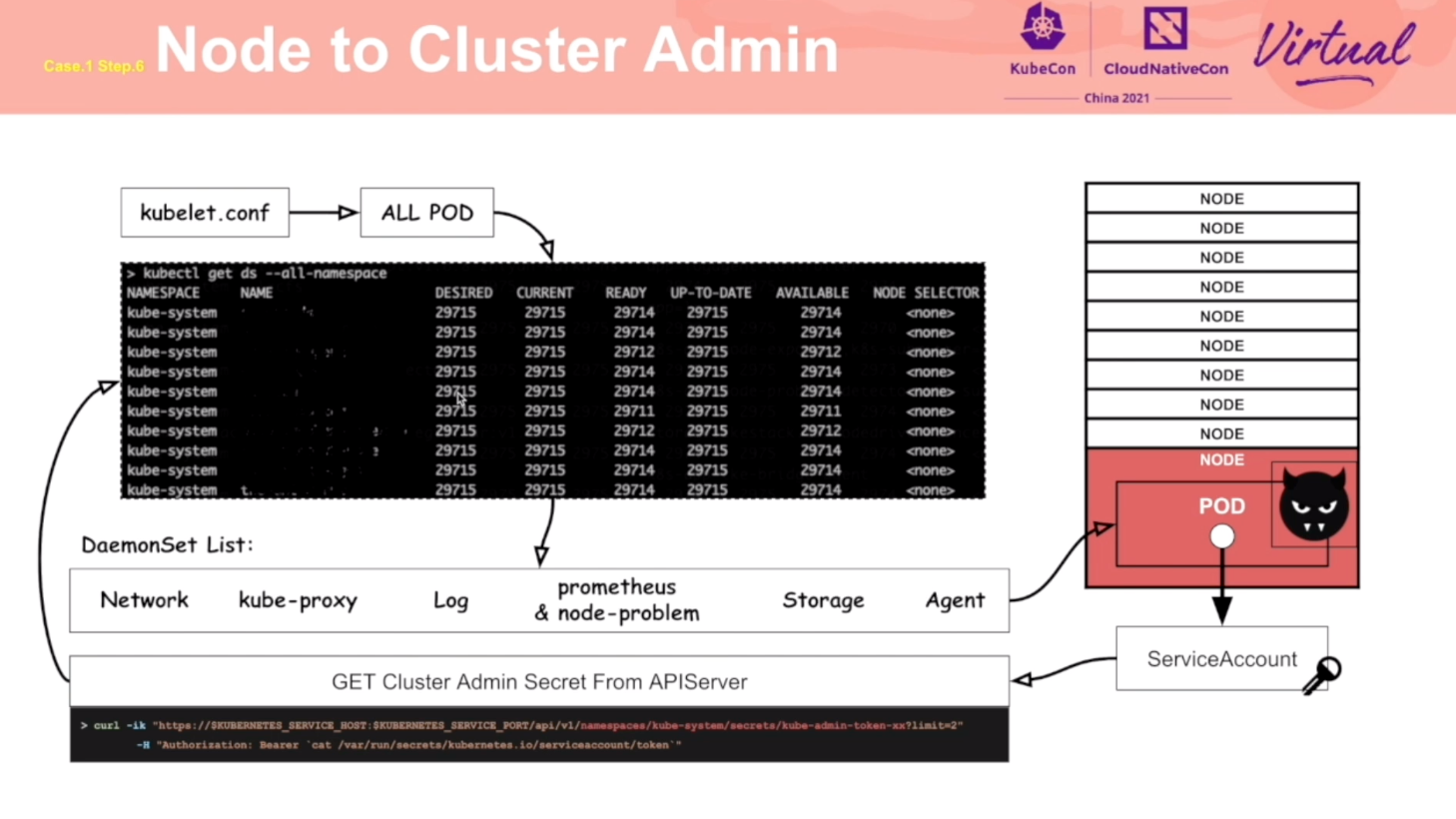

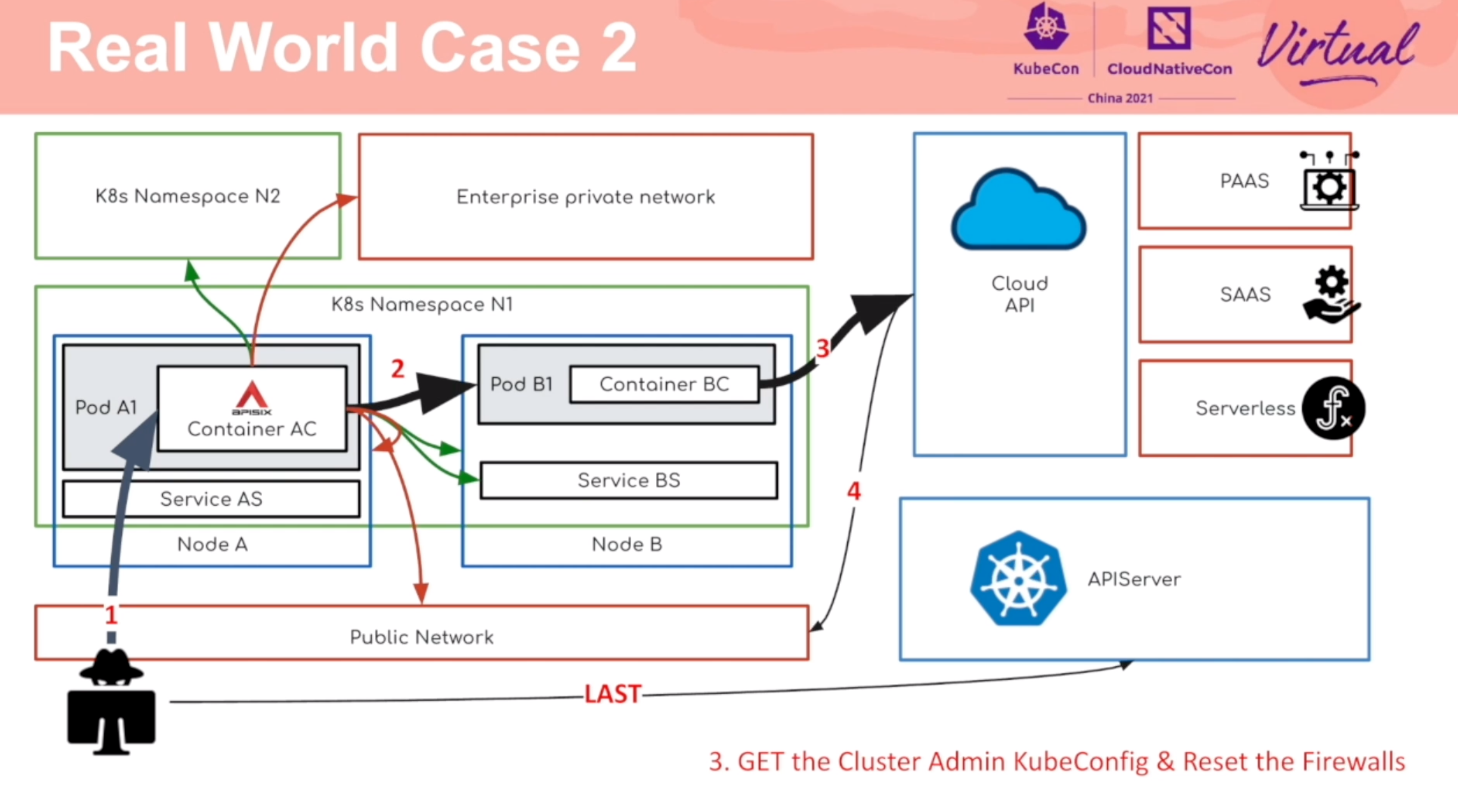

推荐同时阅读乐枕的这篇文章: https://developer.aliyun.com/article/765449
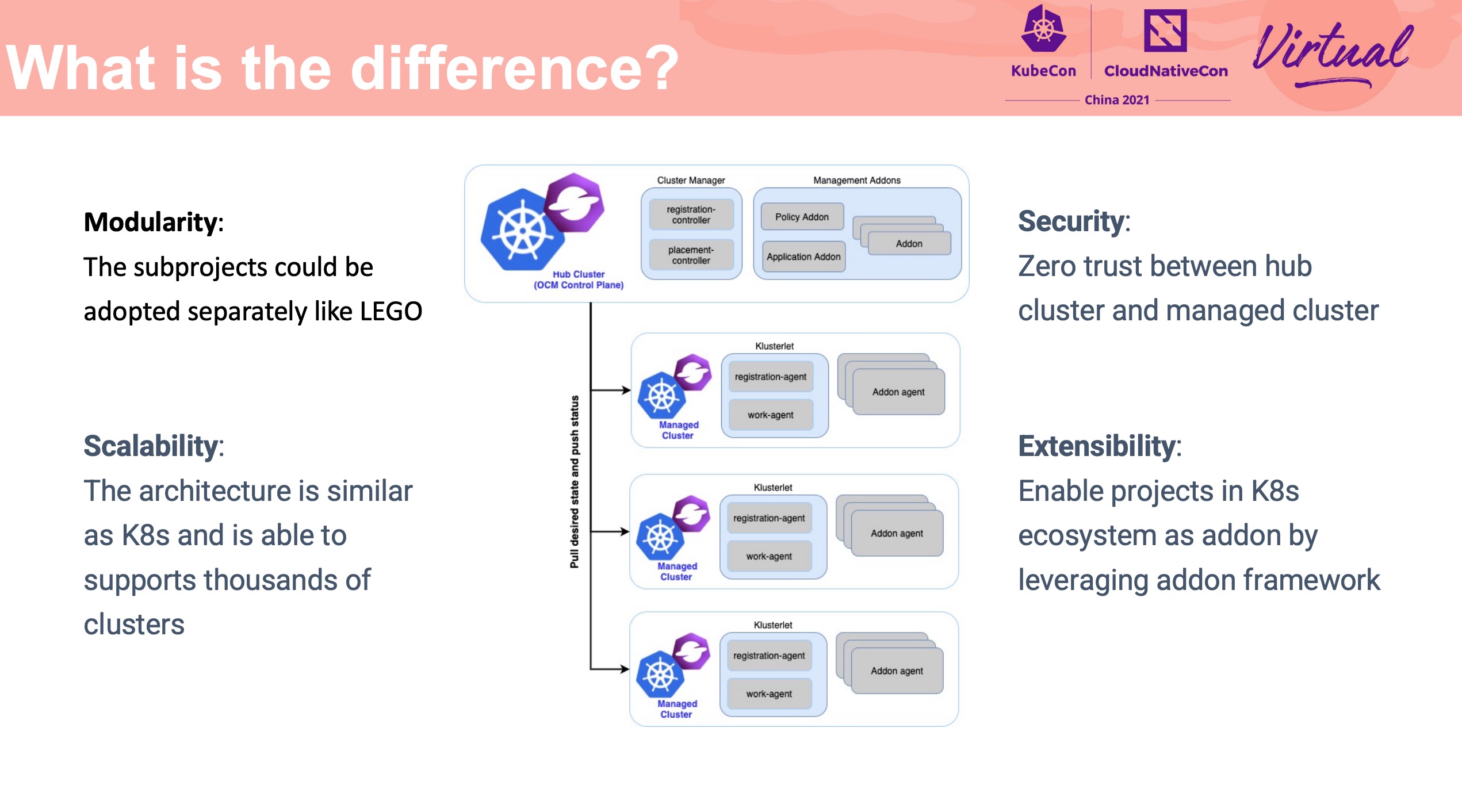
Build and Manage Multi-cluster Application with Consistent Experience
KubeVela
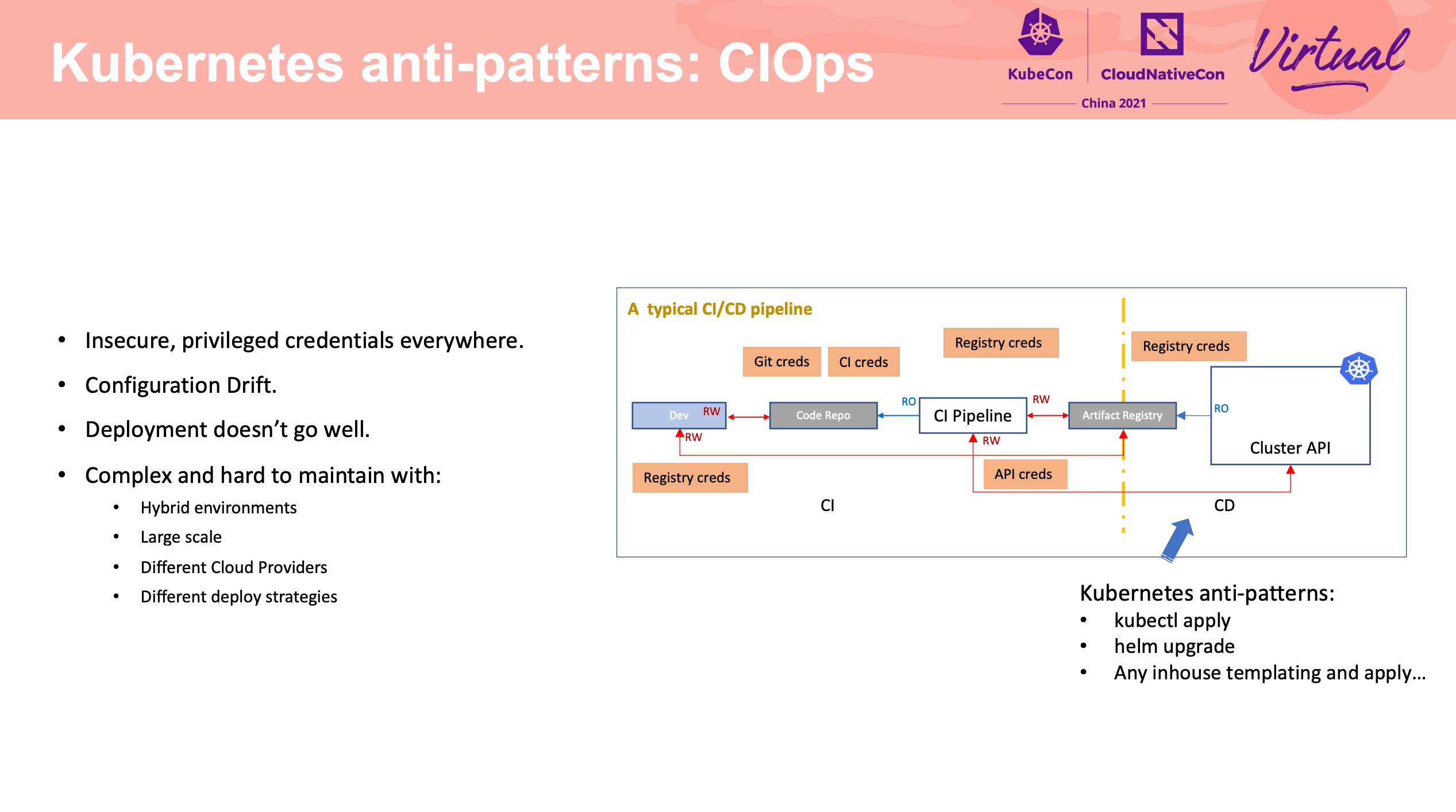

OCM

A full-scenario colocation of workloads based on Kubernetes

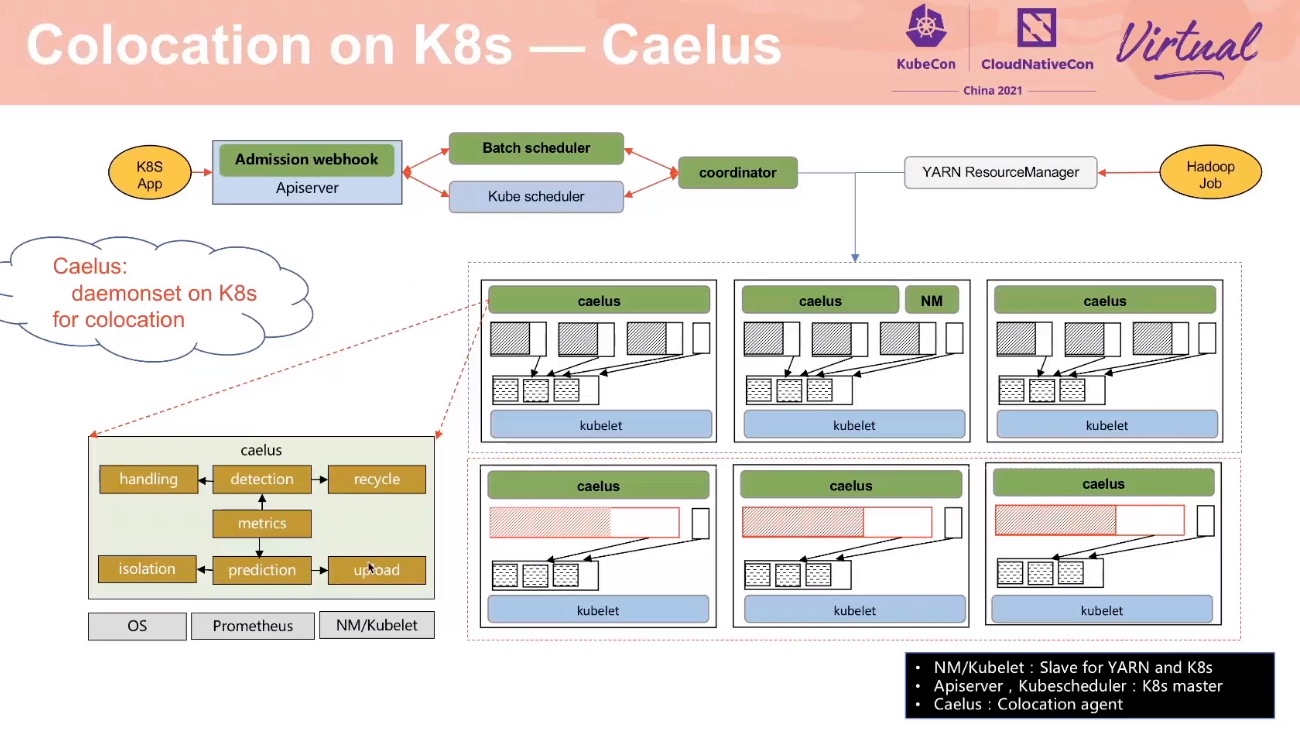
需要优先保证在线资源的可用性。
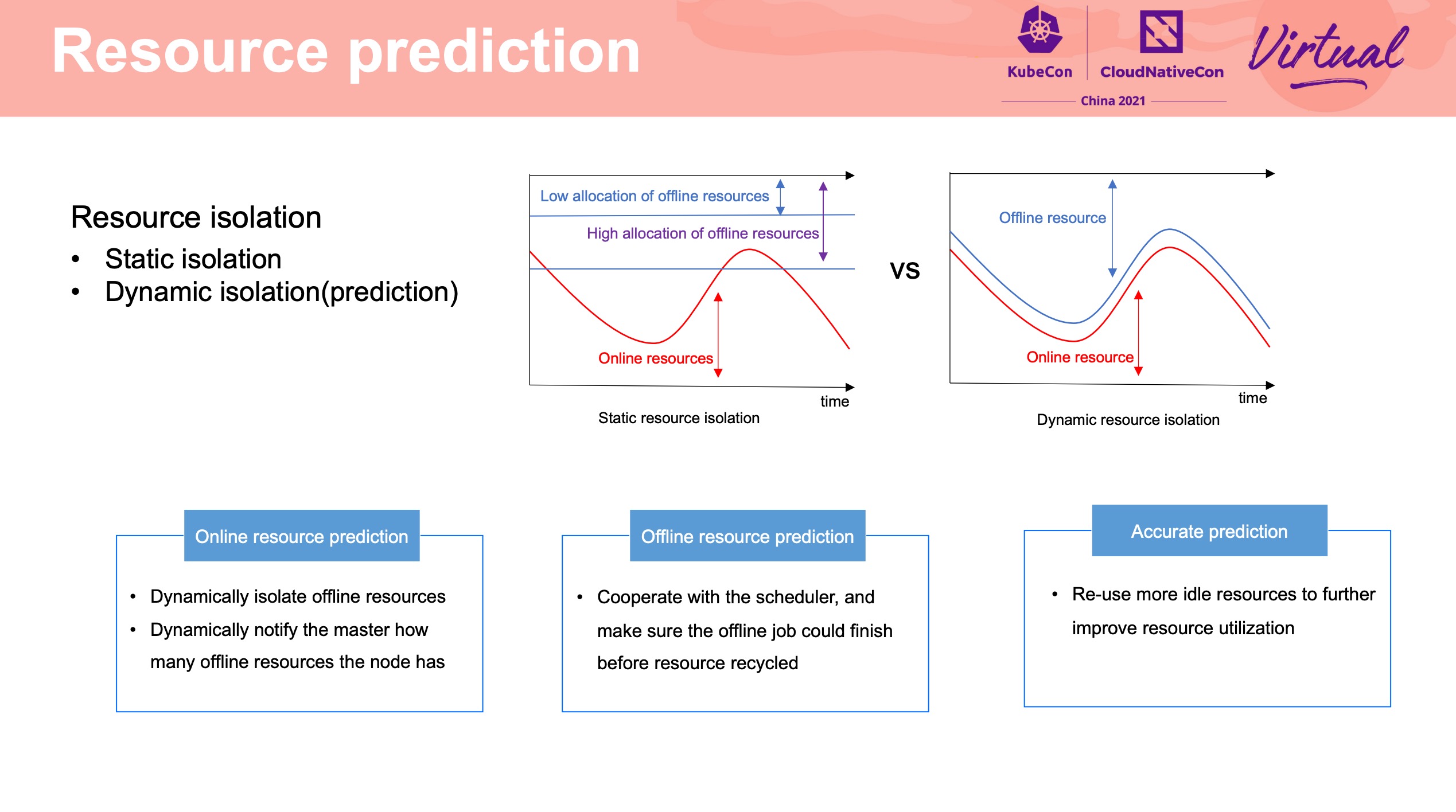
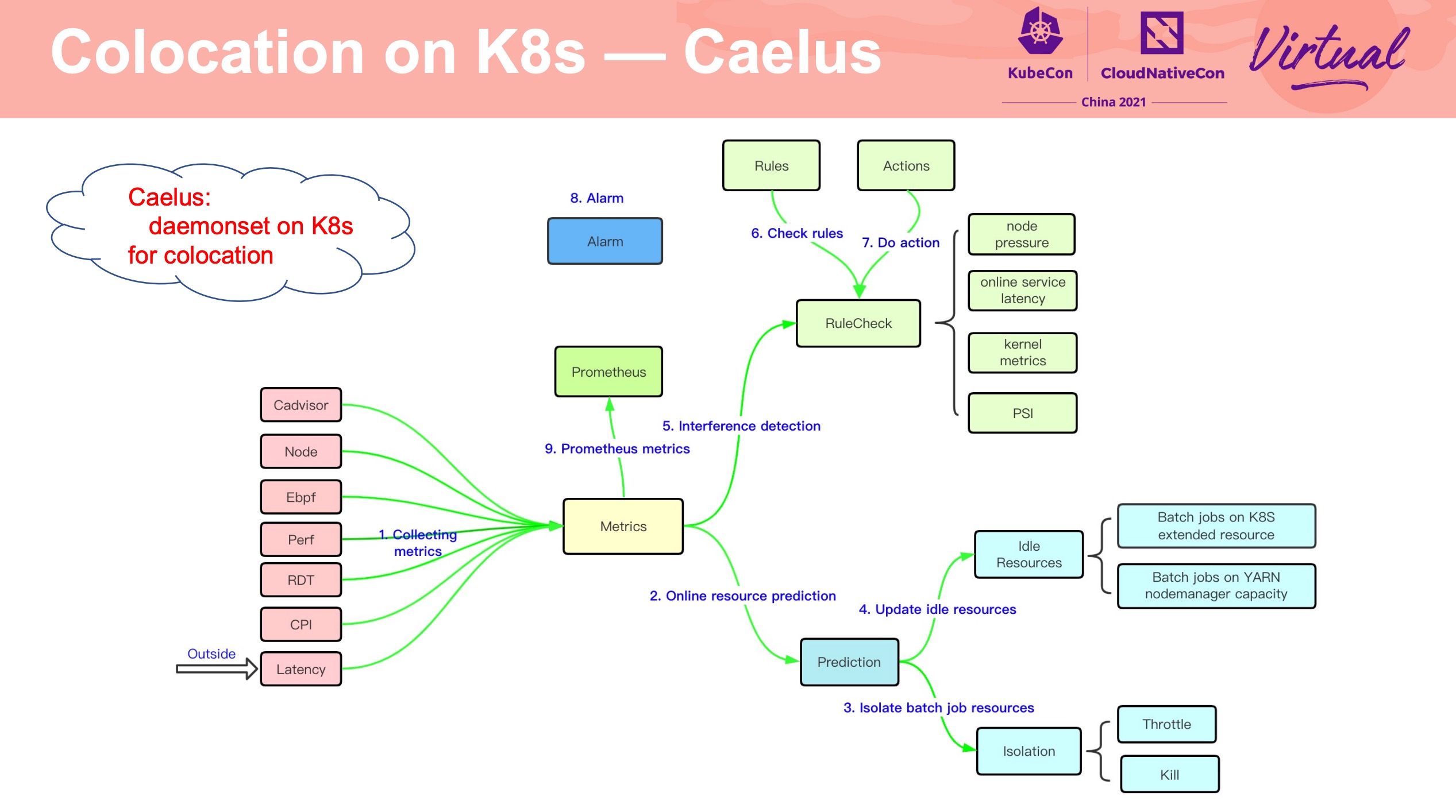
Resource Prediction
为在线资源做画像,预测在线资源使用,动态做隔离。
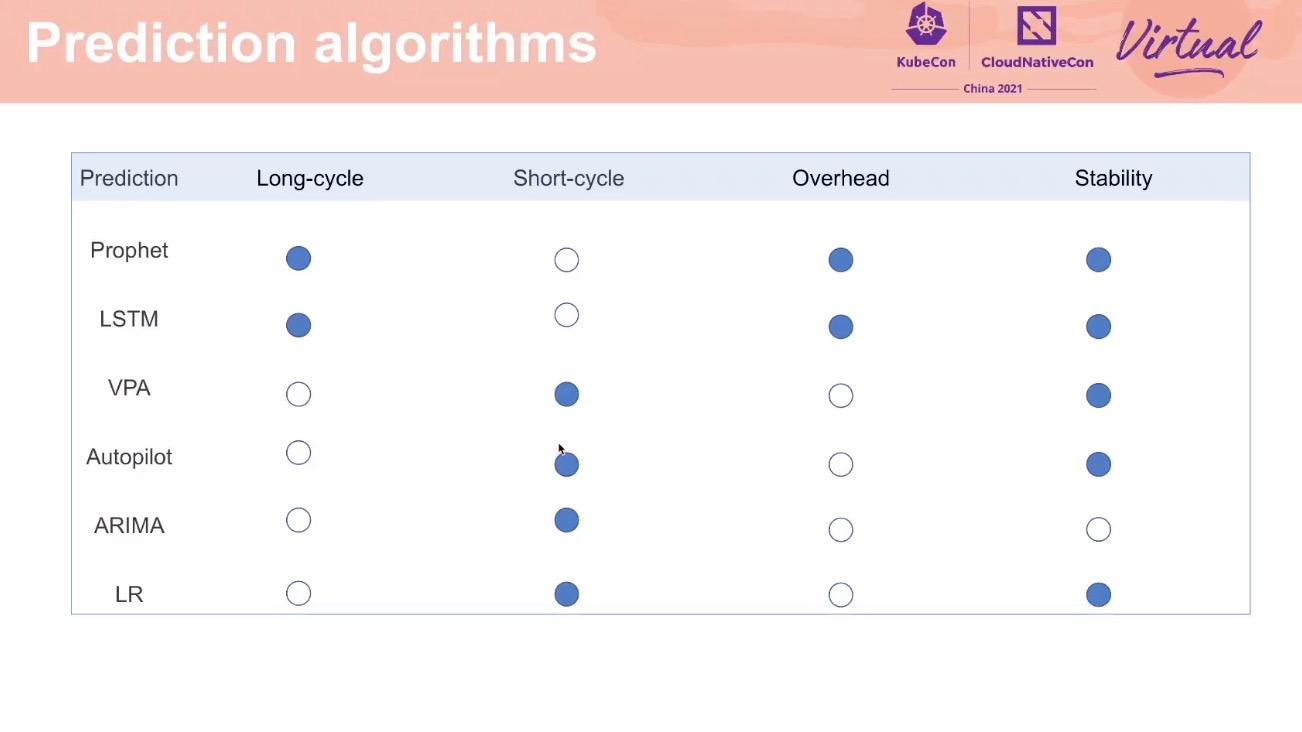
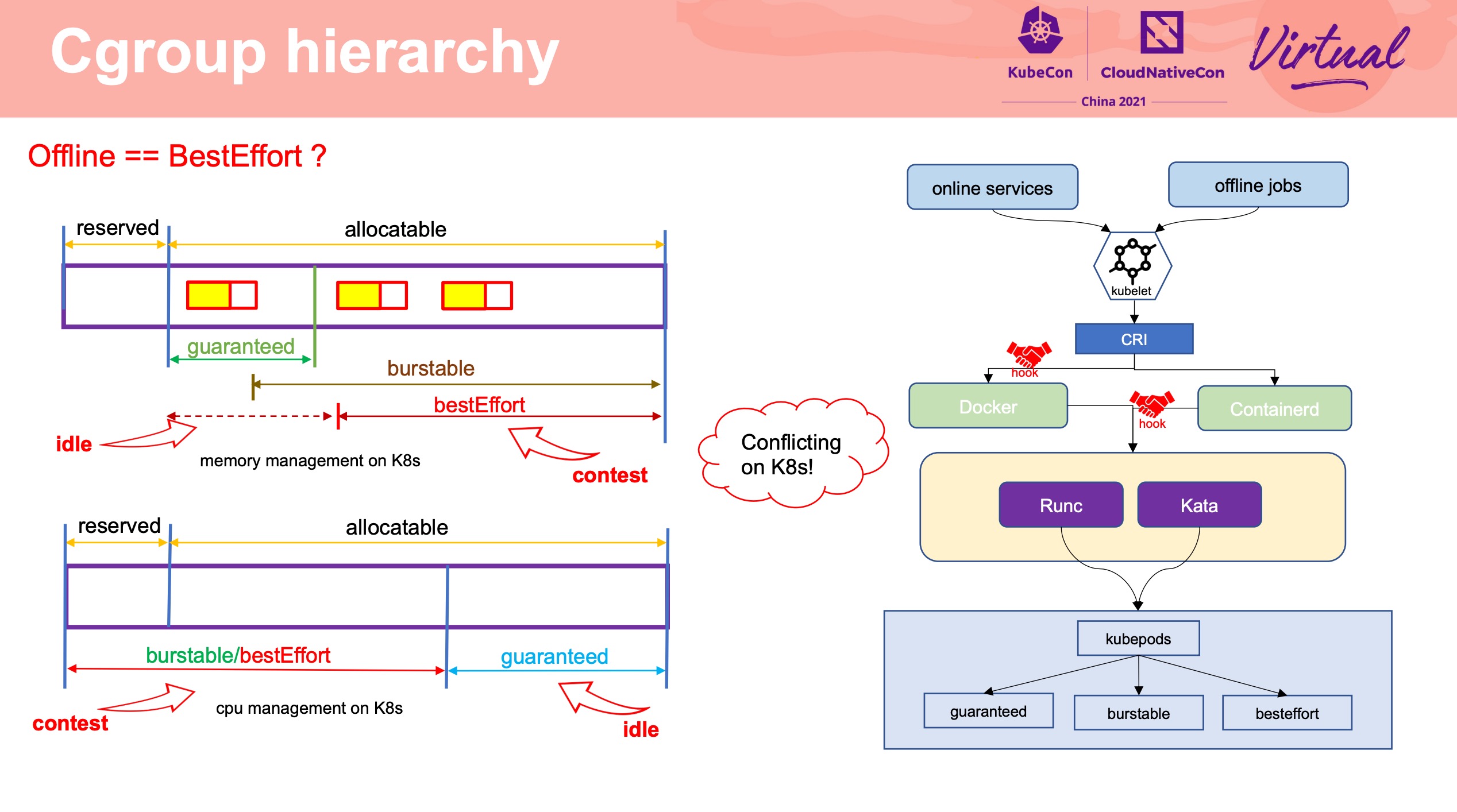
K8s BestEffort 容易在可用的资源范围内,调度大量的离线资源作业,造成资源阻塞。
通过修改 cgroup 层级结构来扩大混部资源池。 离线资源统一管理,而不受 K8s 管理。
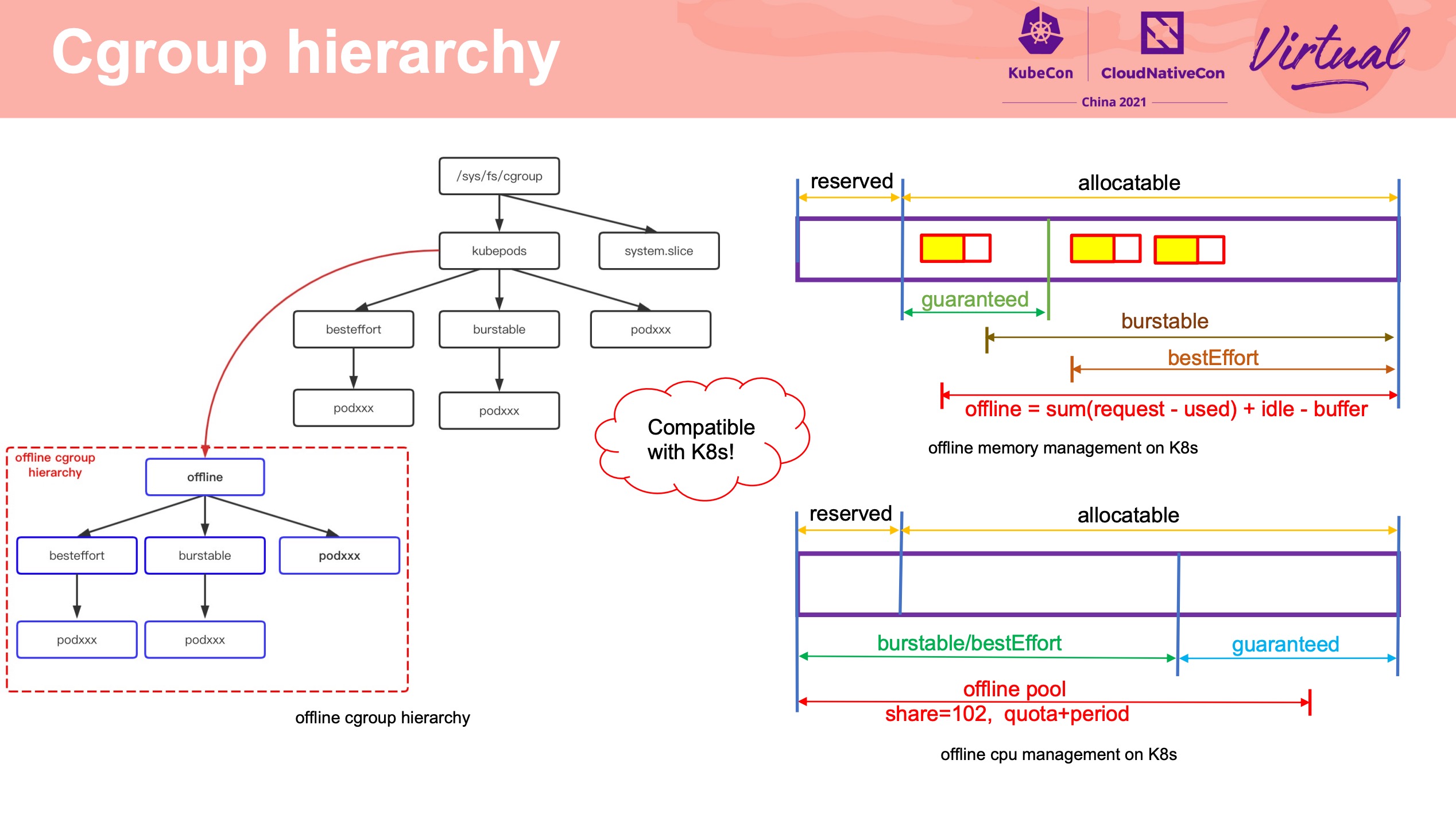
Resource Isolation
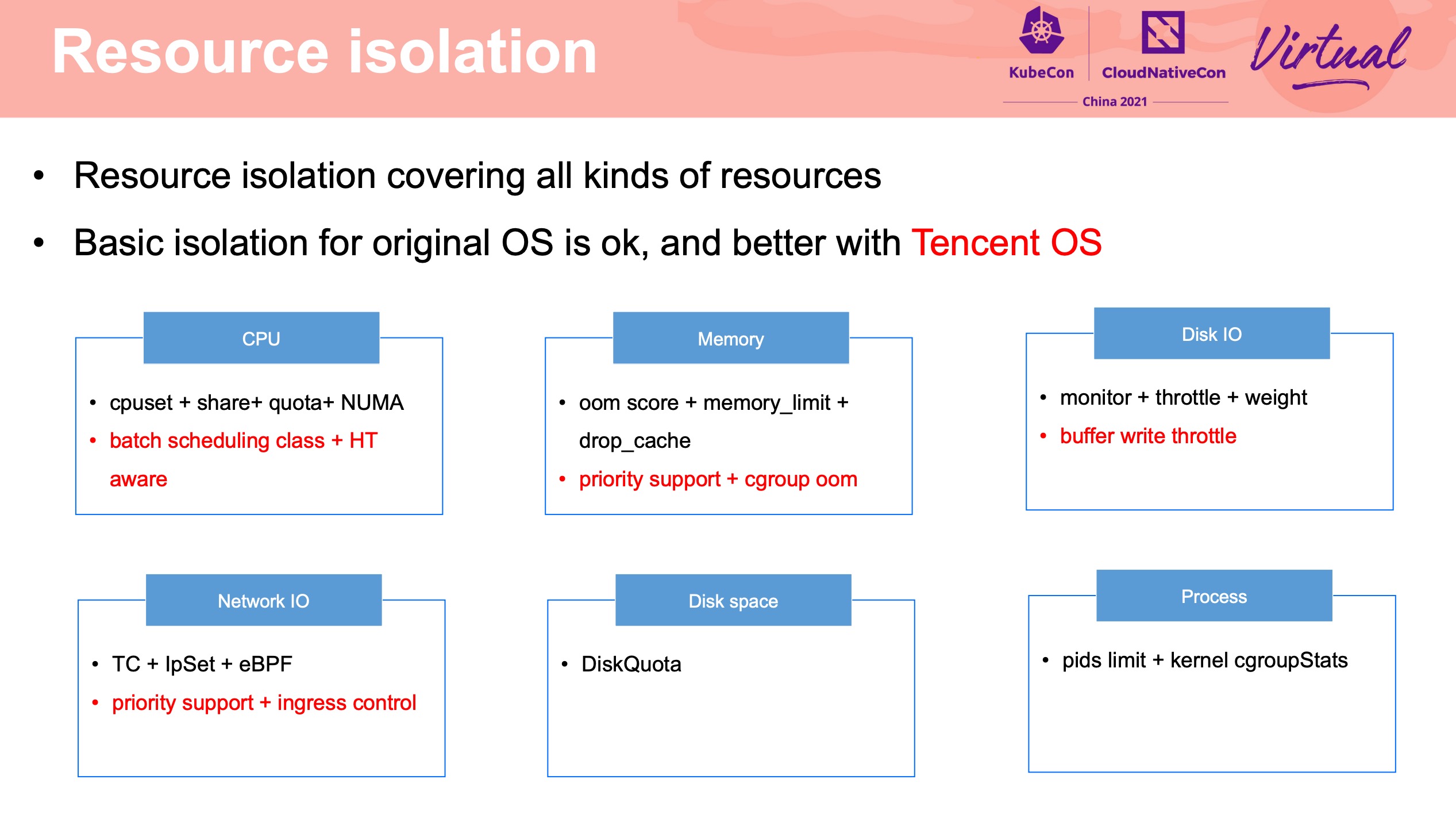
这块感觉有点魔改了。
Interference Detection
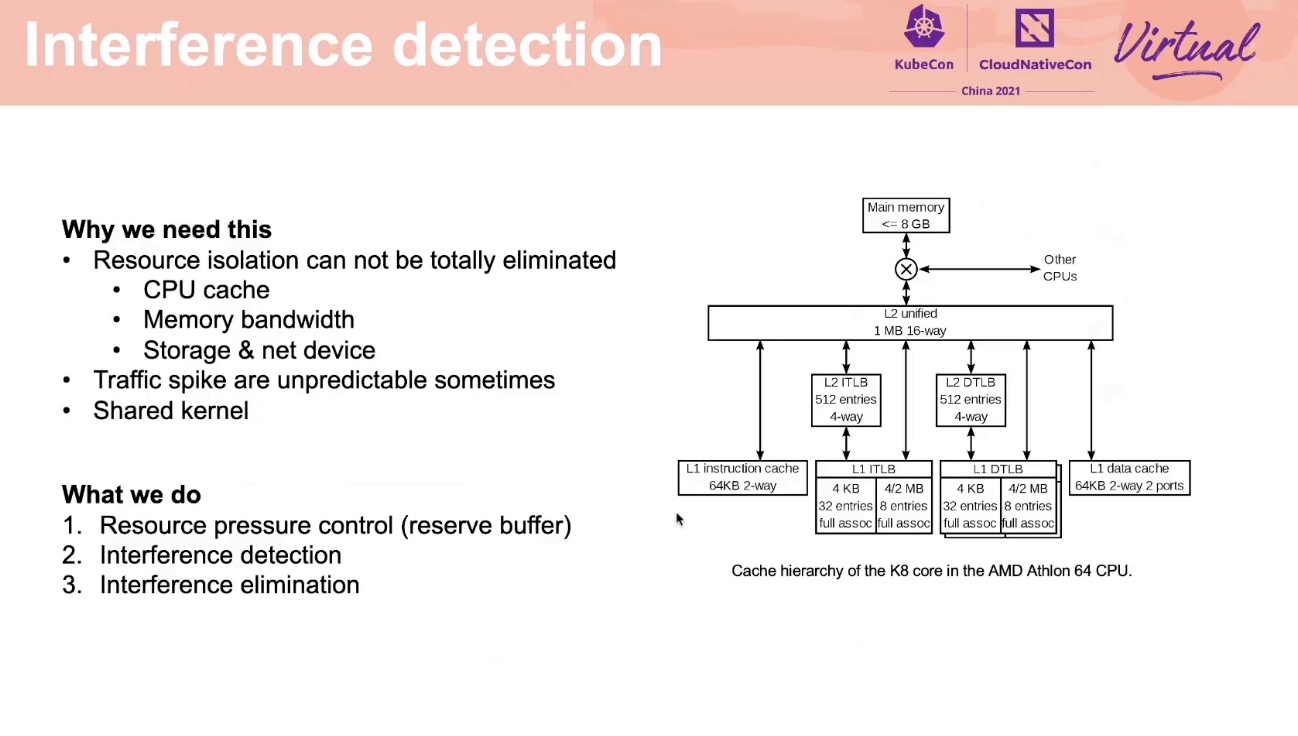
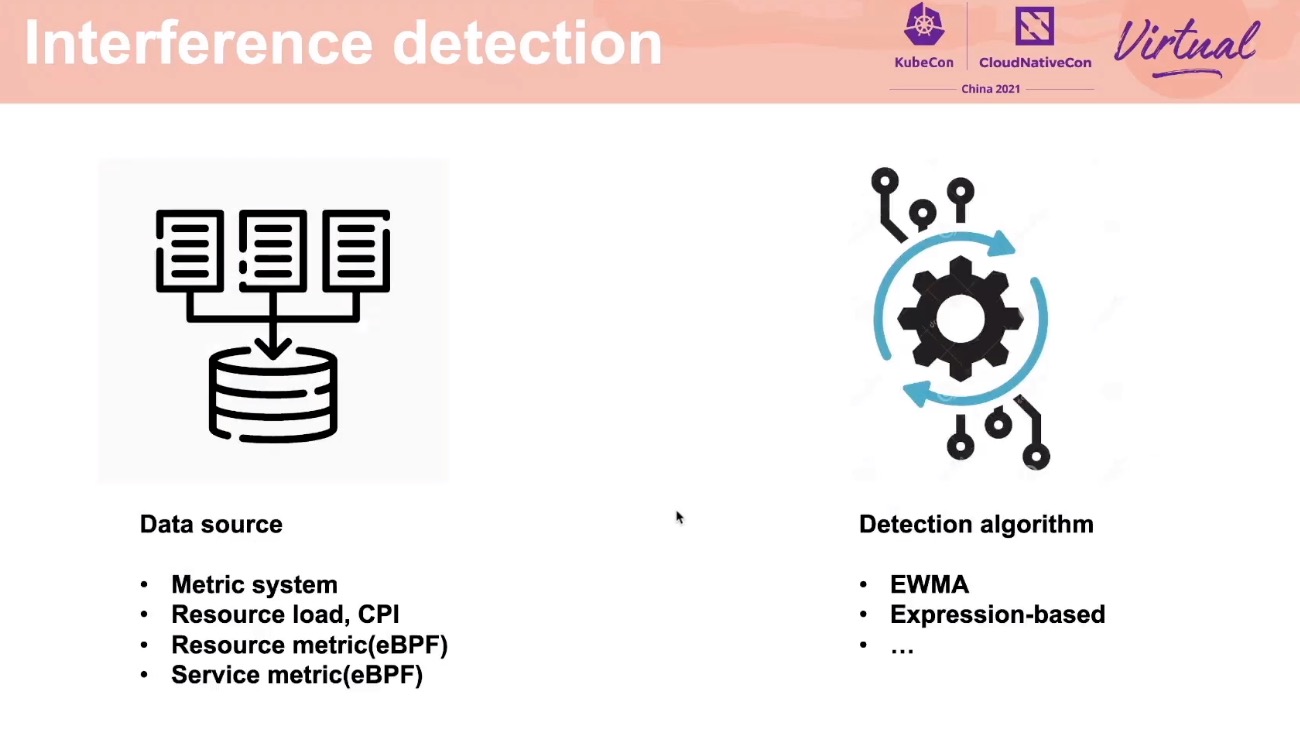
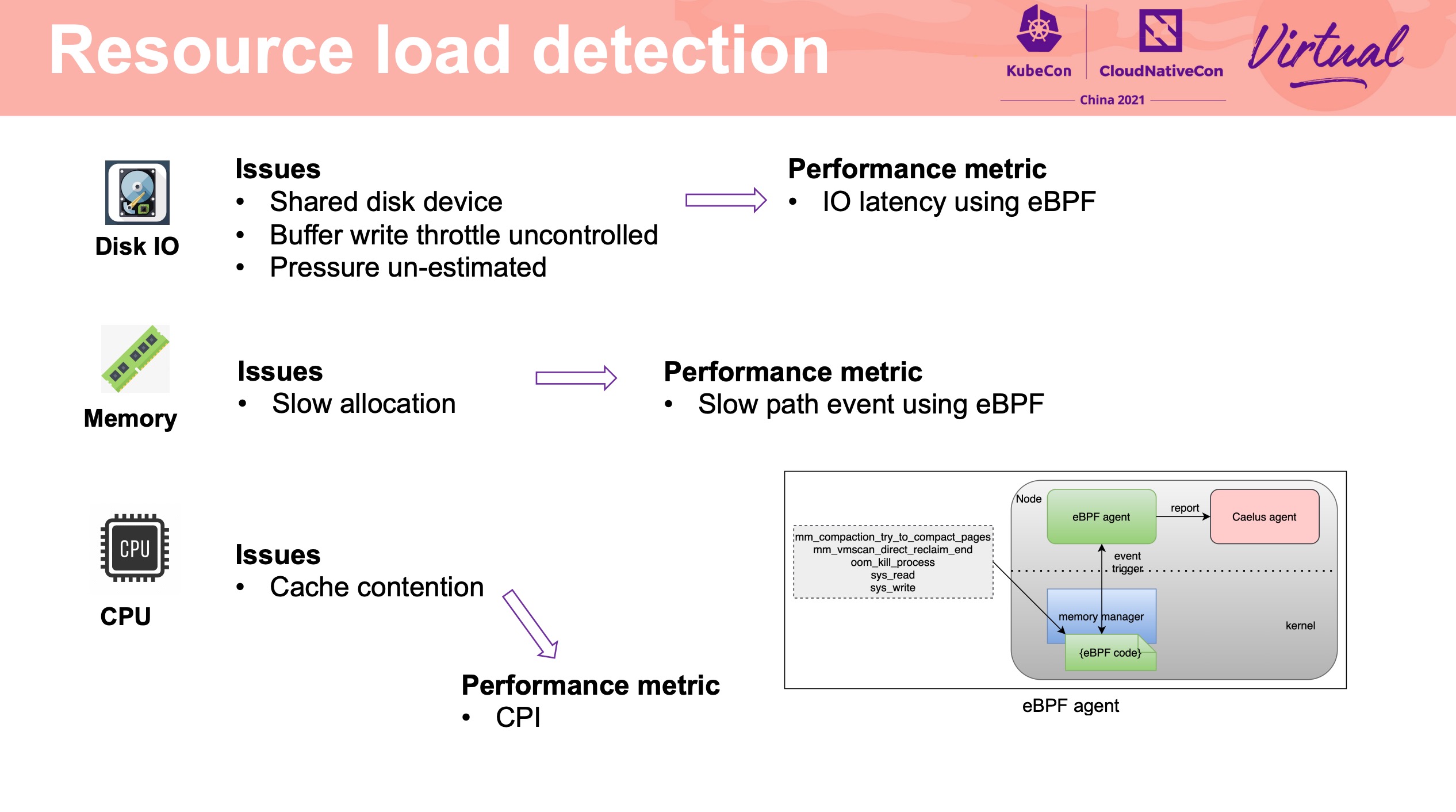
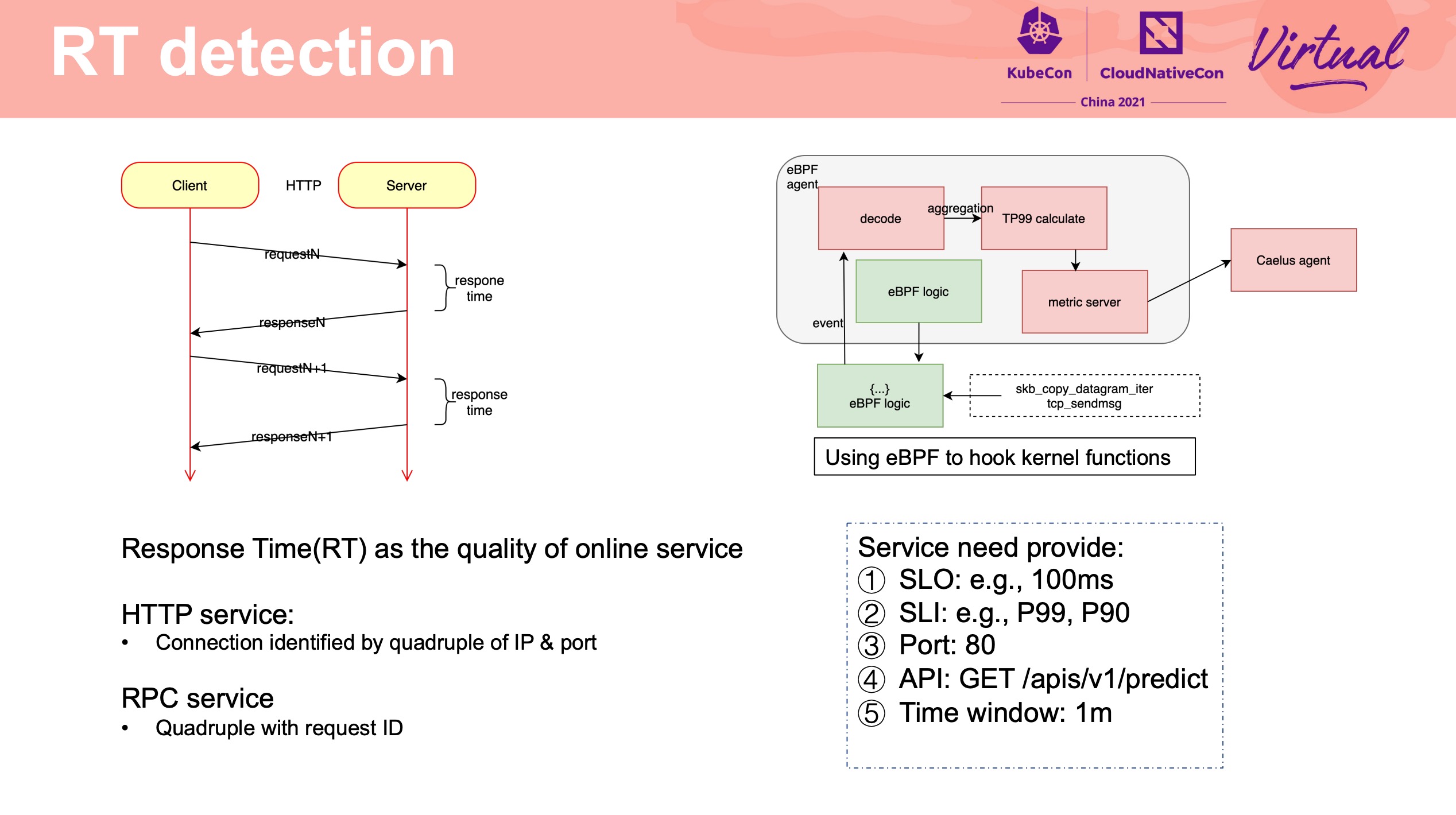
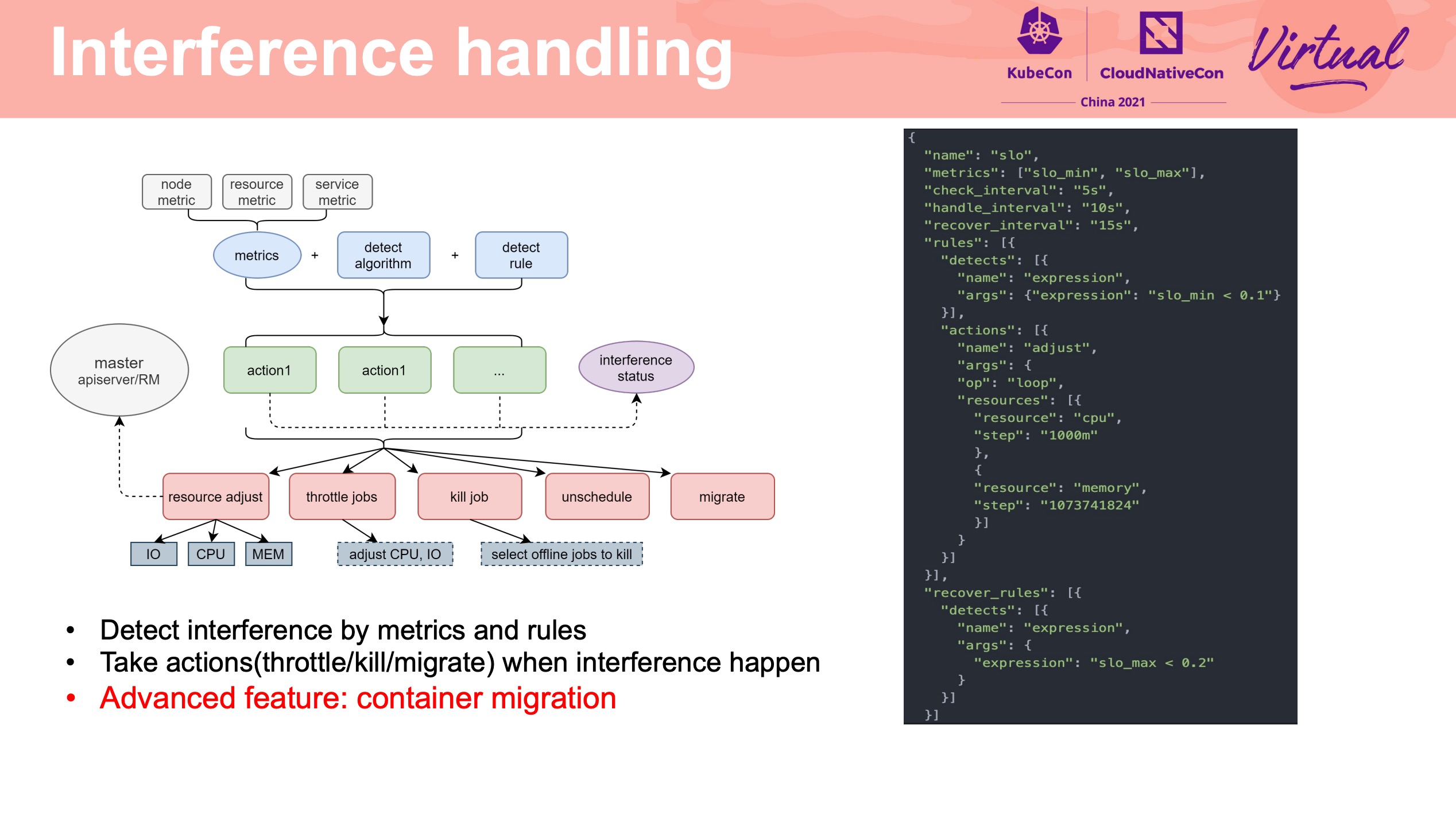
腾讯这个项目也开源了: https://github.com/Tencent/Caelus
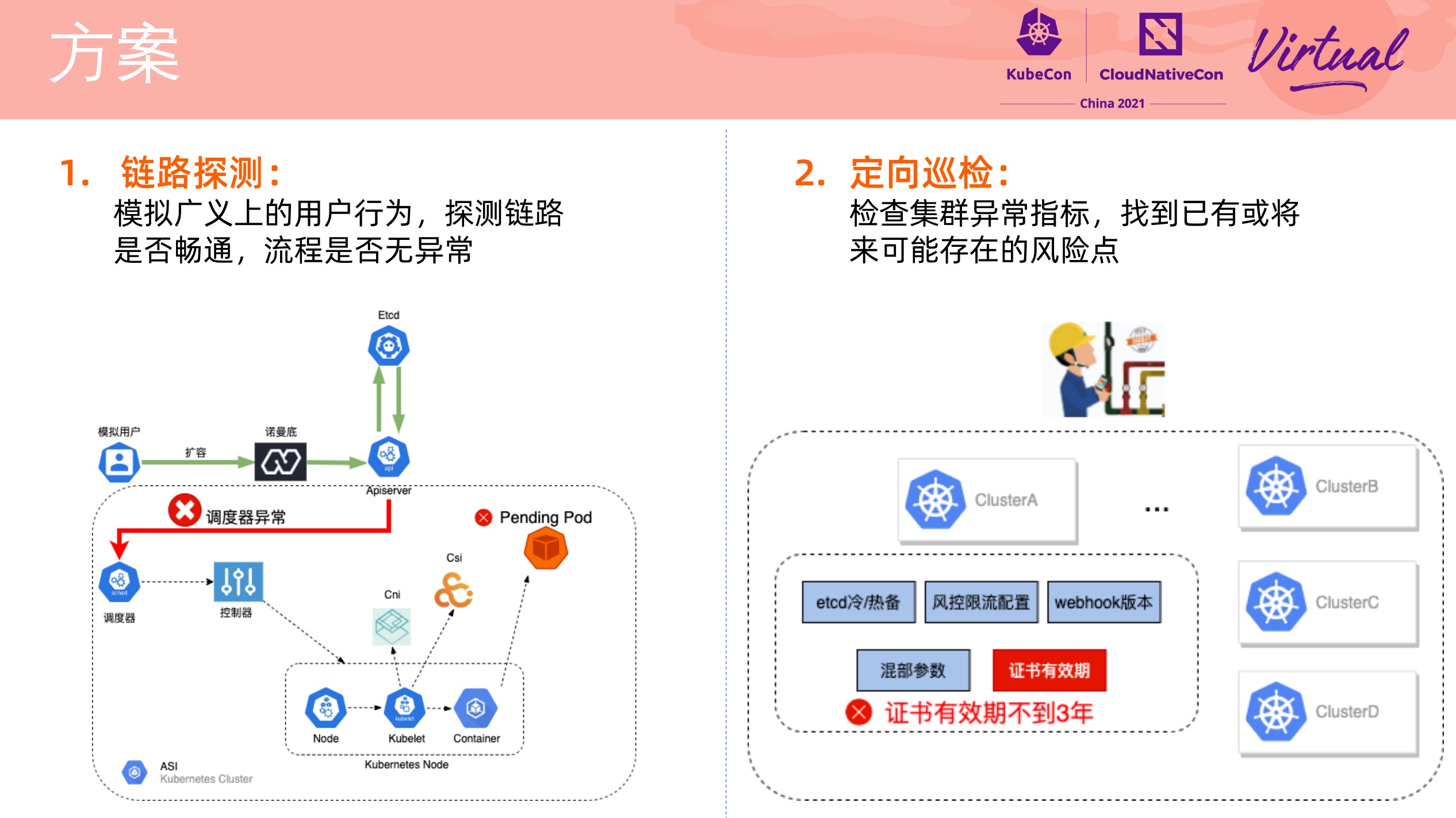
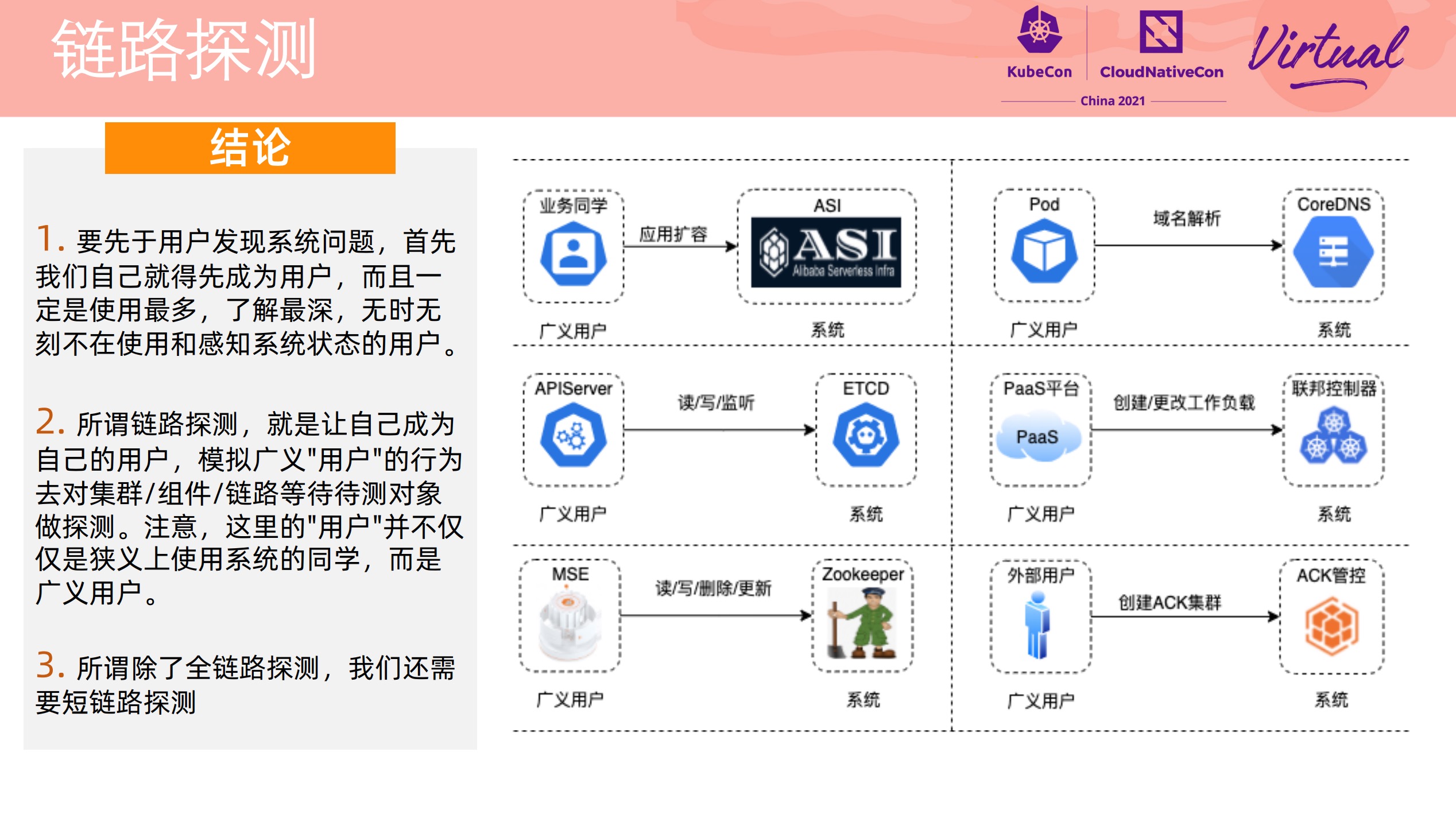
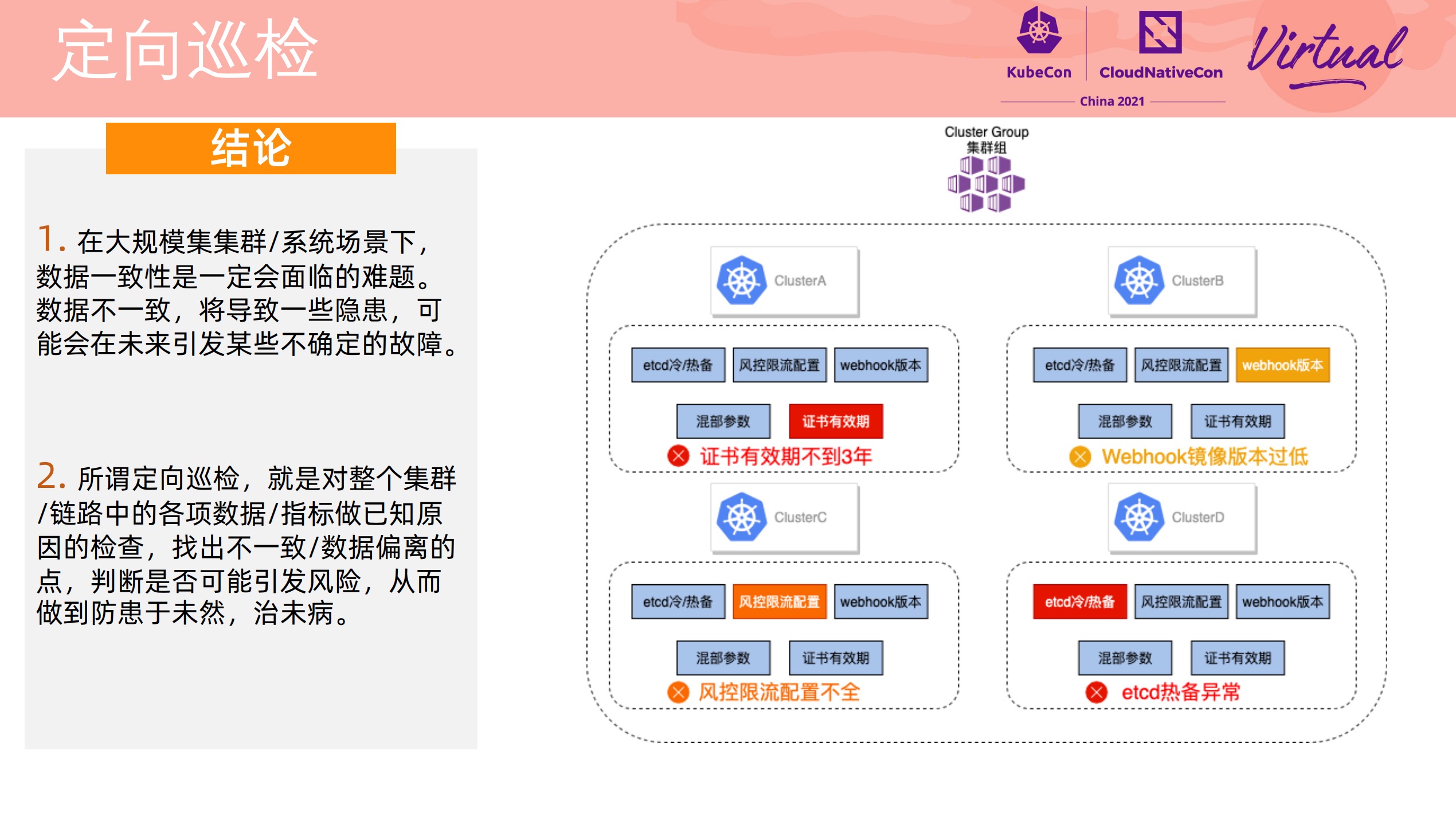
How We Discover and Locate k8s Cluster Problems Before Users at Alibaba
加强版集群巡检,直接看 PPT 就好。
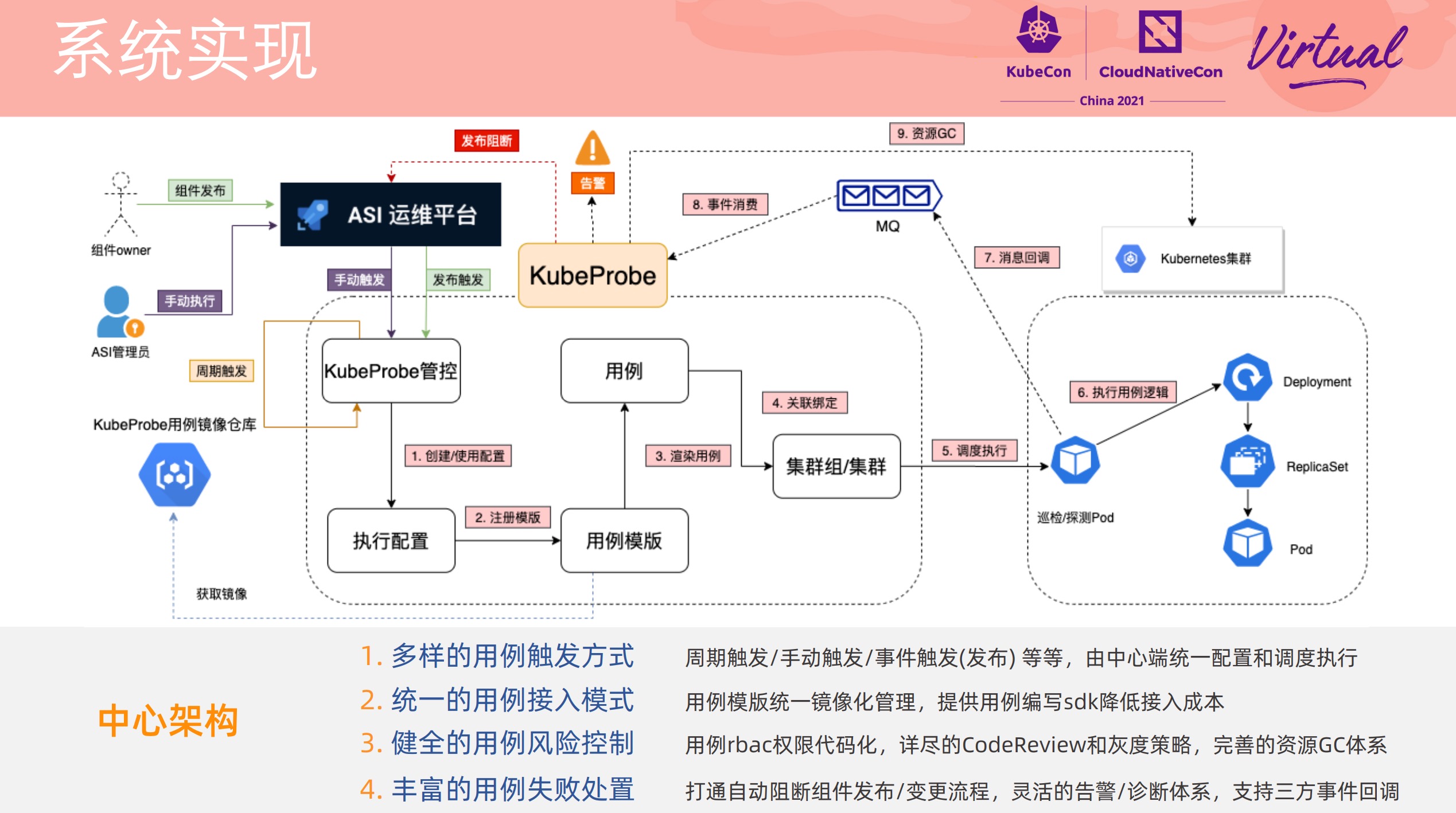
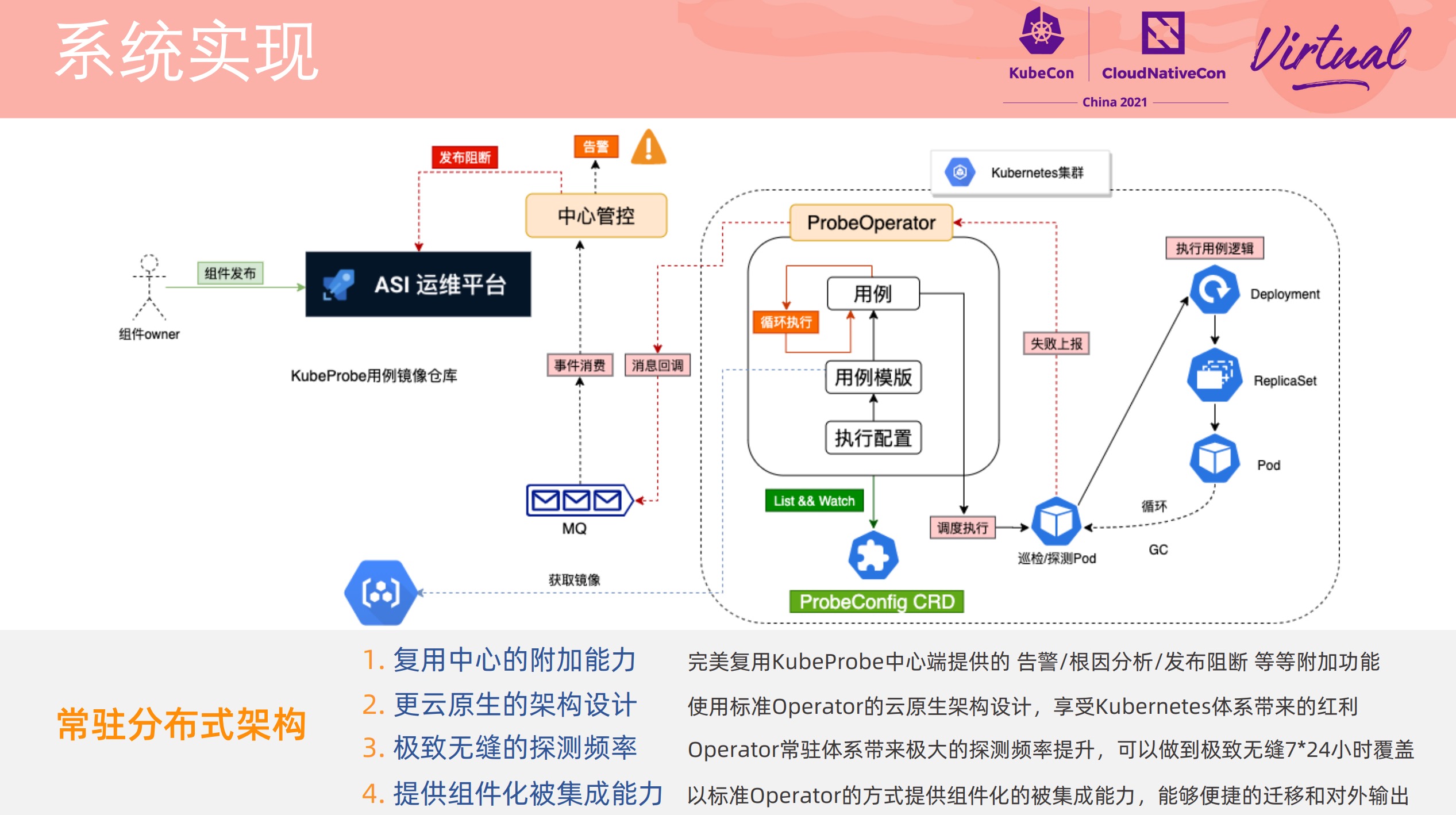
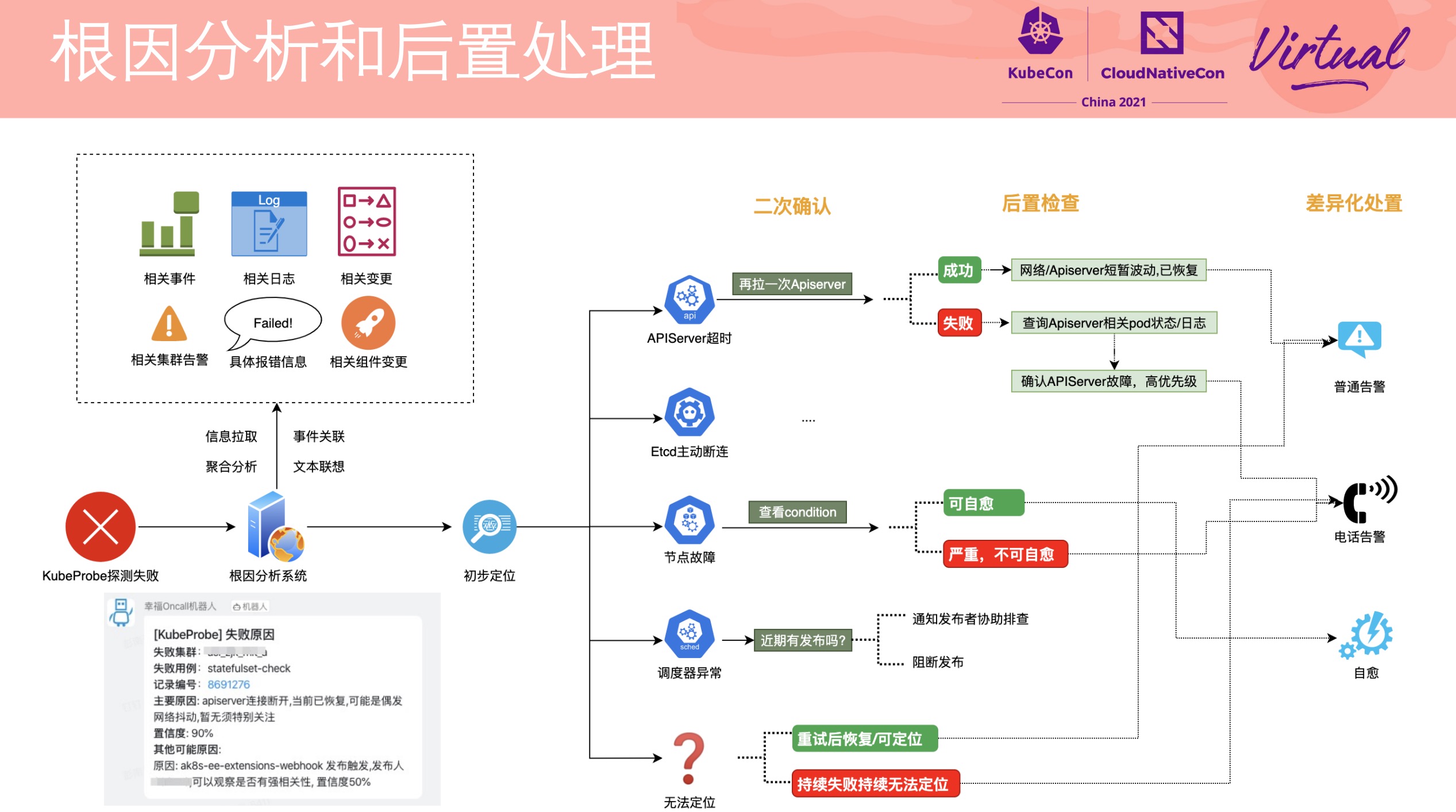
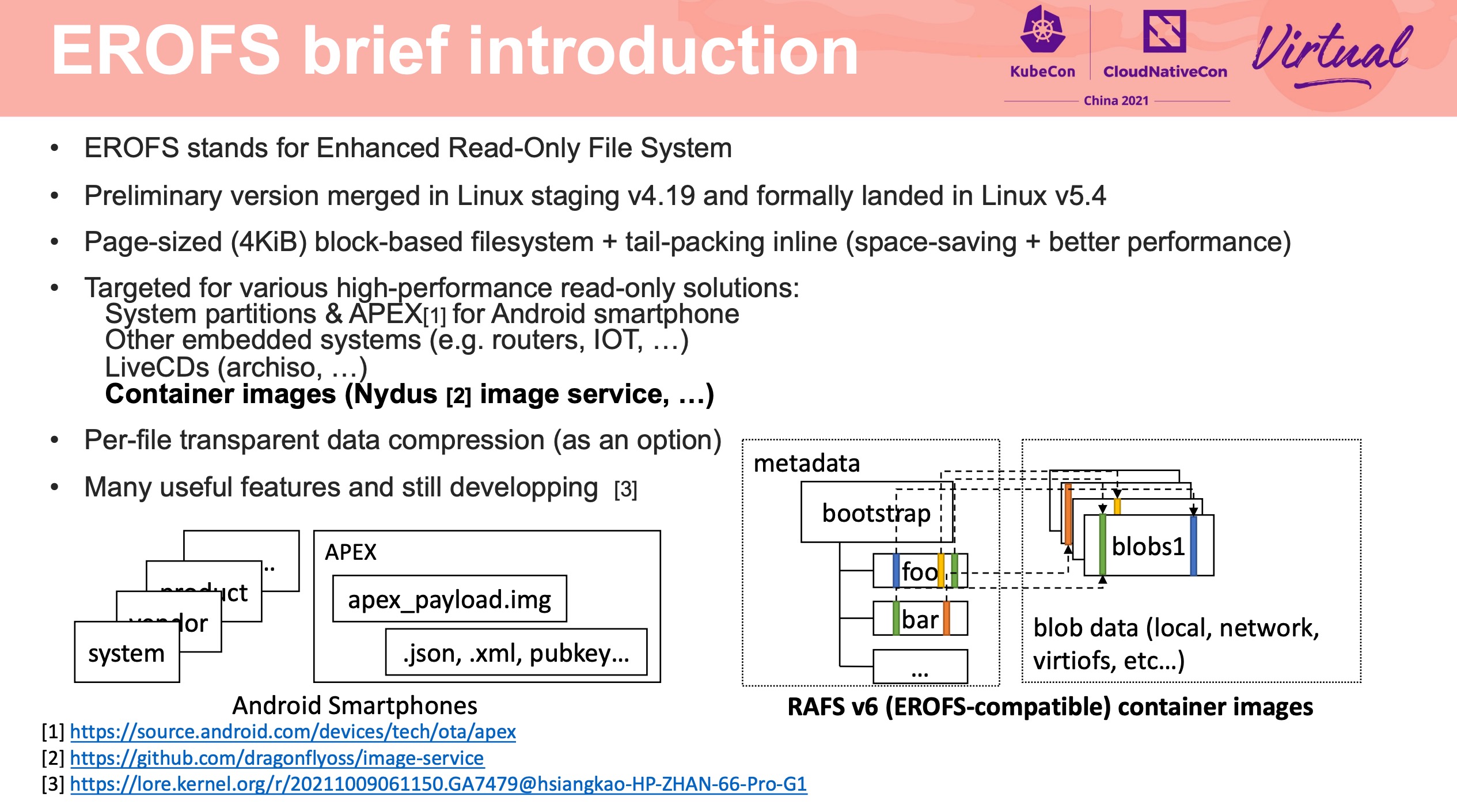
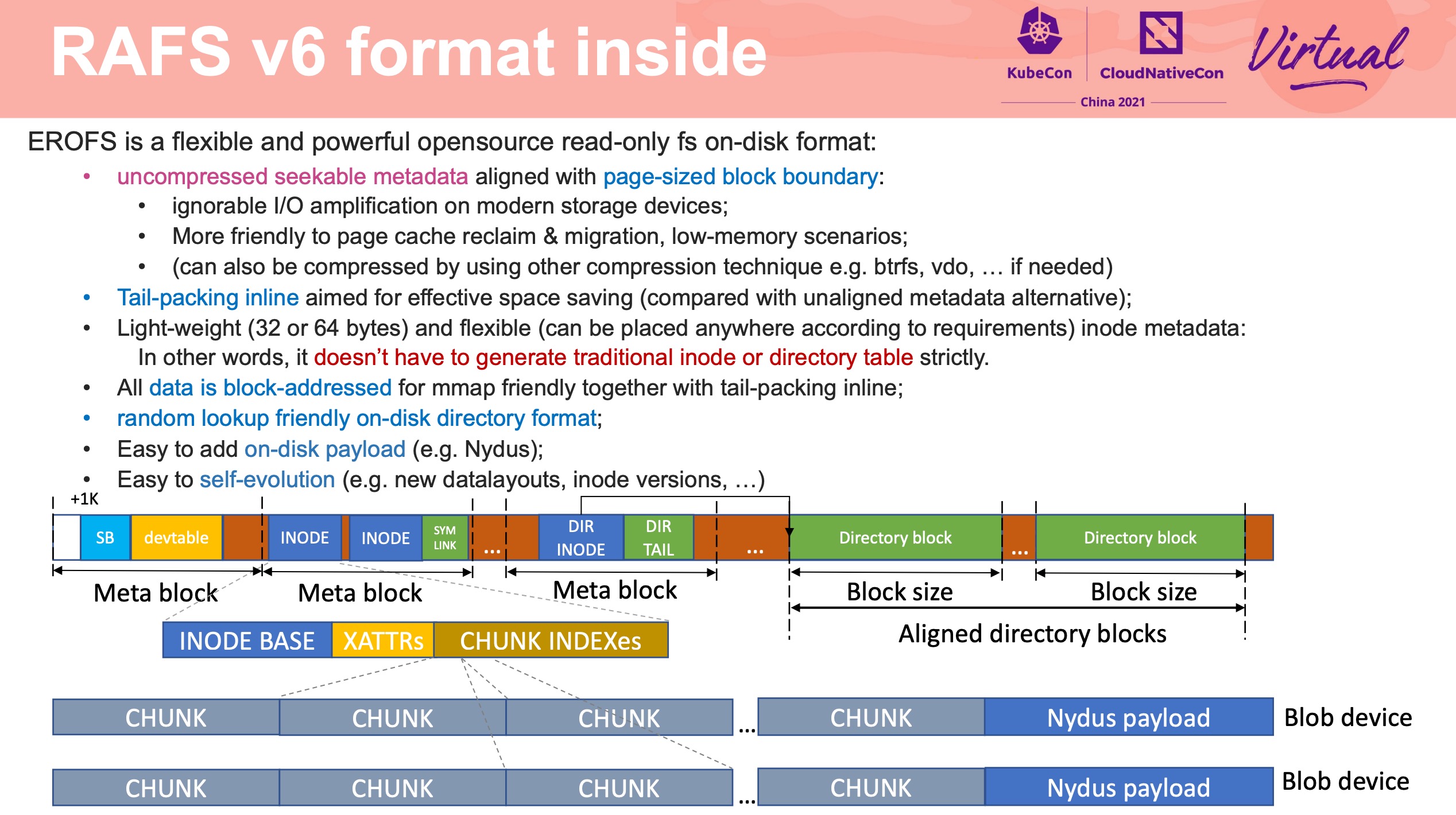
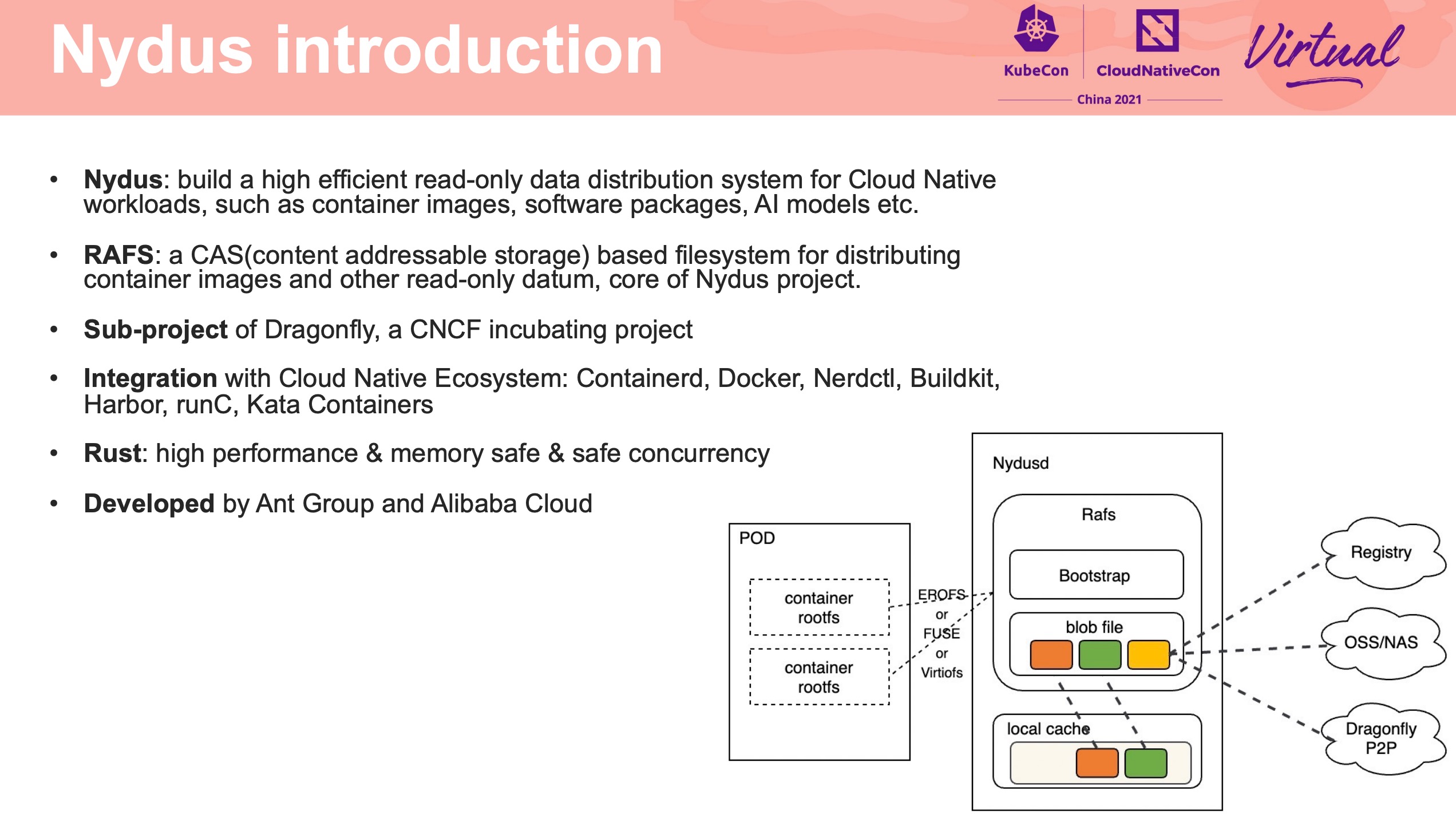
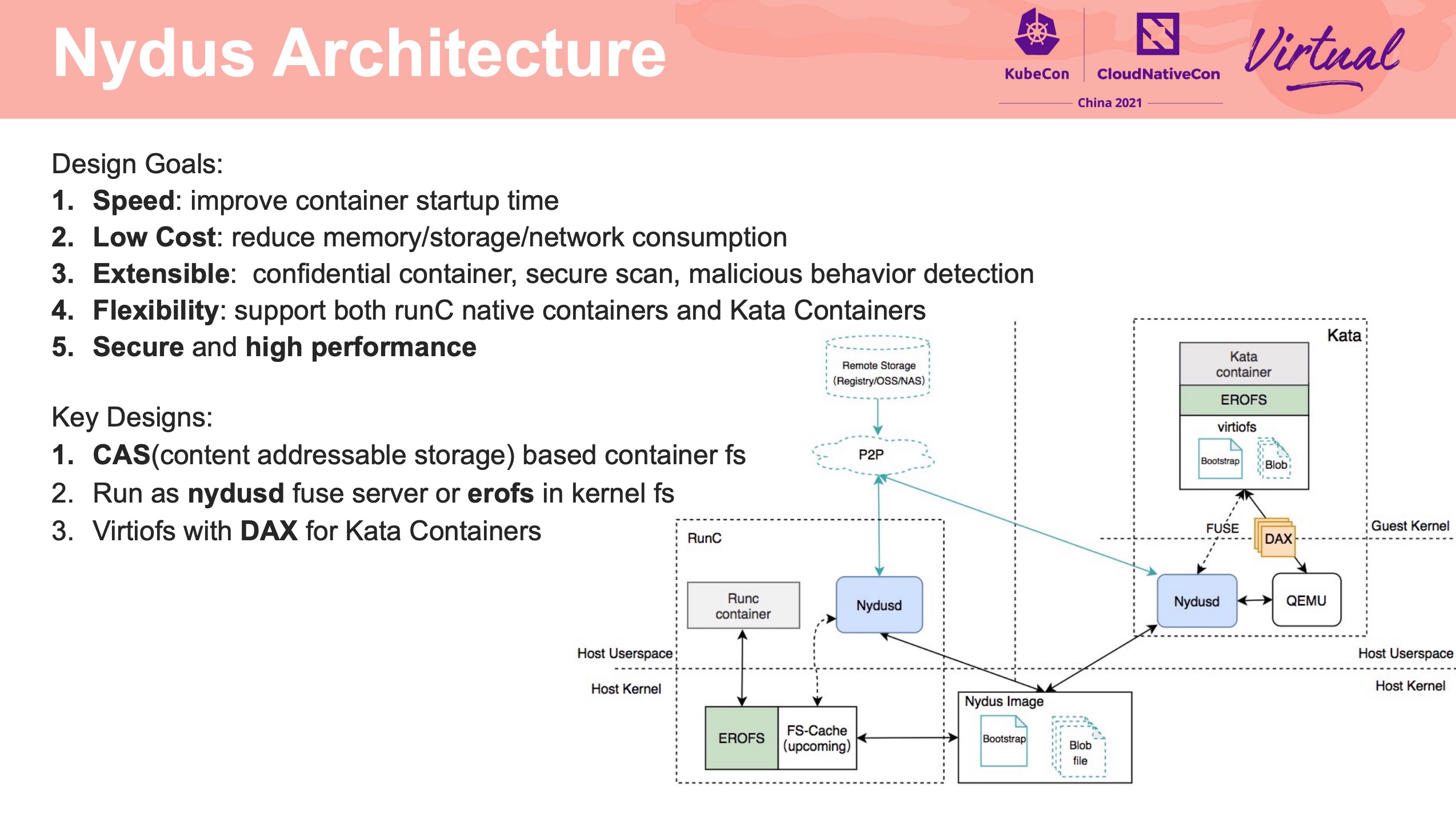
EROFS What Are We Doing Now For Containers
感觉通篇都很硬核。
在镜像存储方面打开了另一扇大门。
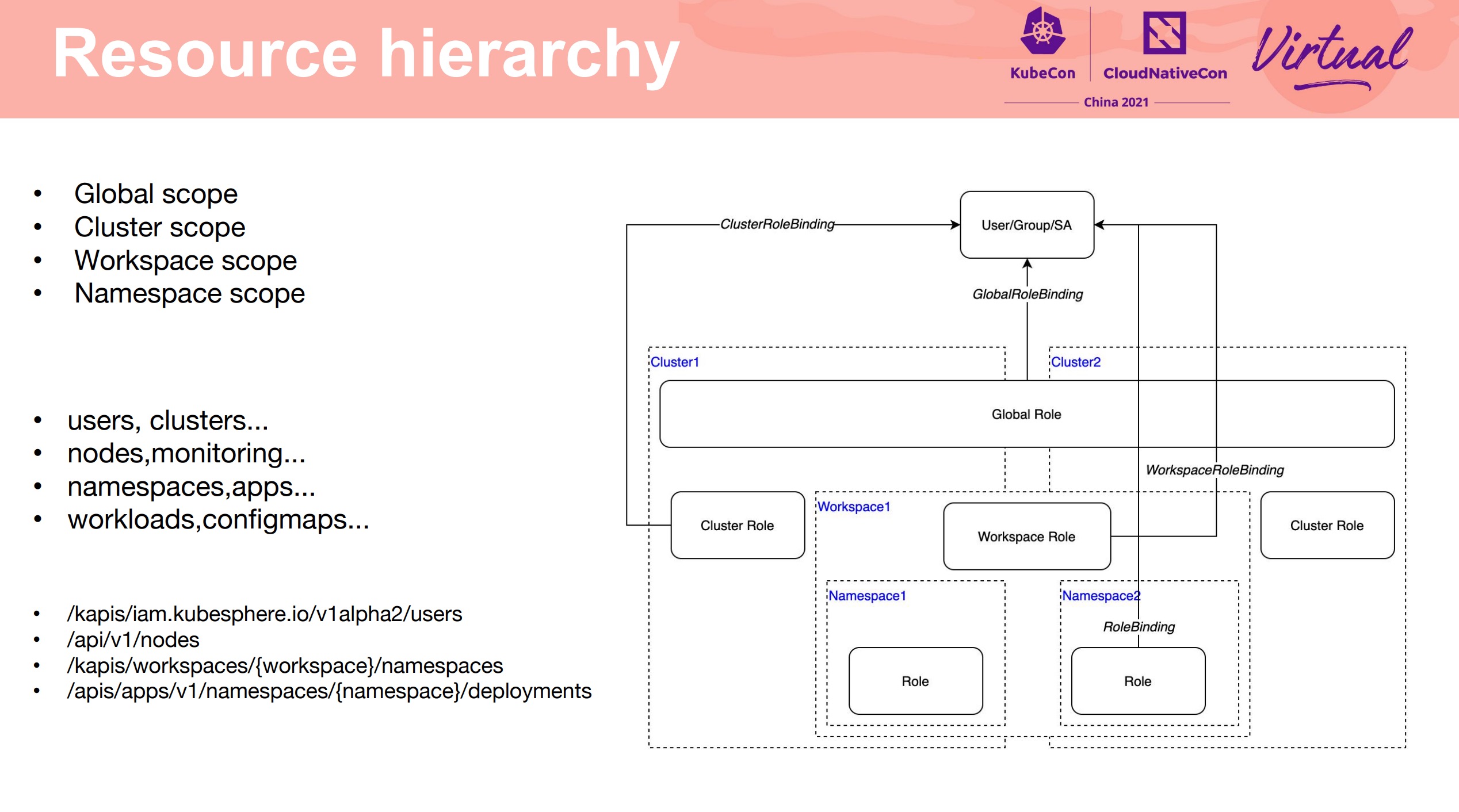
Kubernetes Multi-Cluster and Multi-Tenancy With RBAC and KubeFed
基于 KubeFed 的多租户方案。


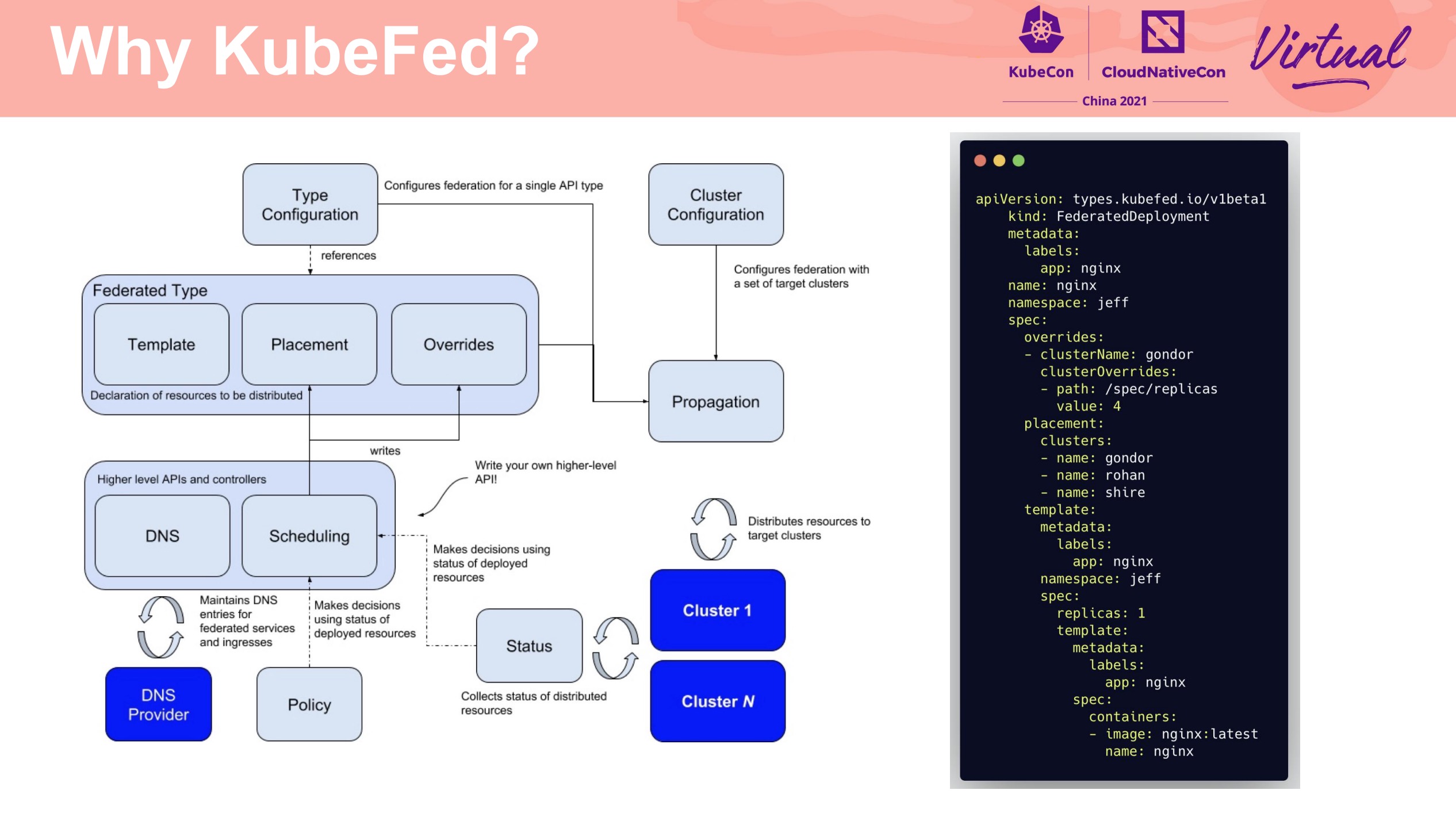
A story of managing kubernetes cluster with 15k nodes and various workloads
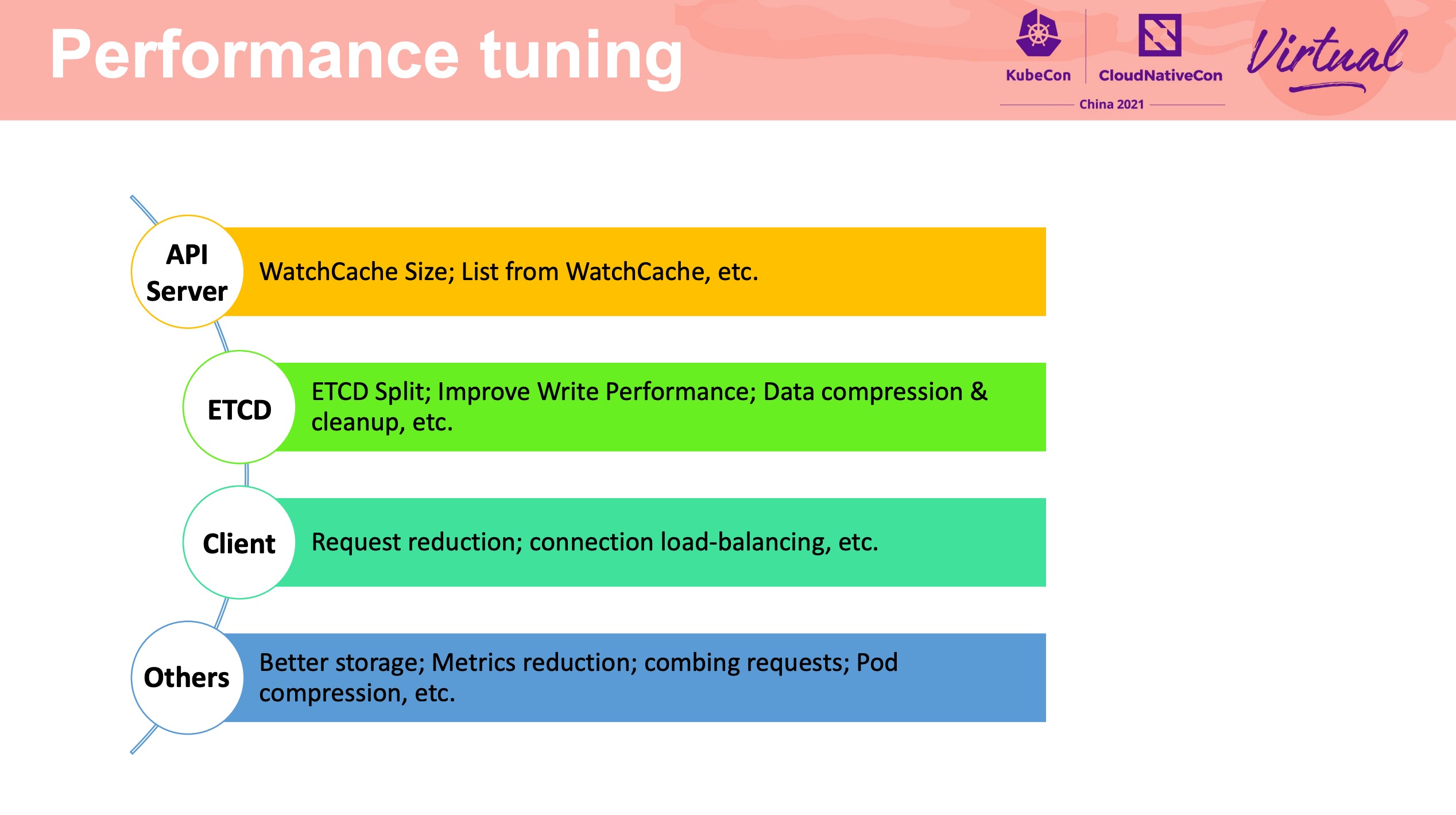
细节非常多。 不过一般公司也没这么大规模。
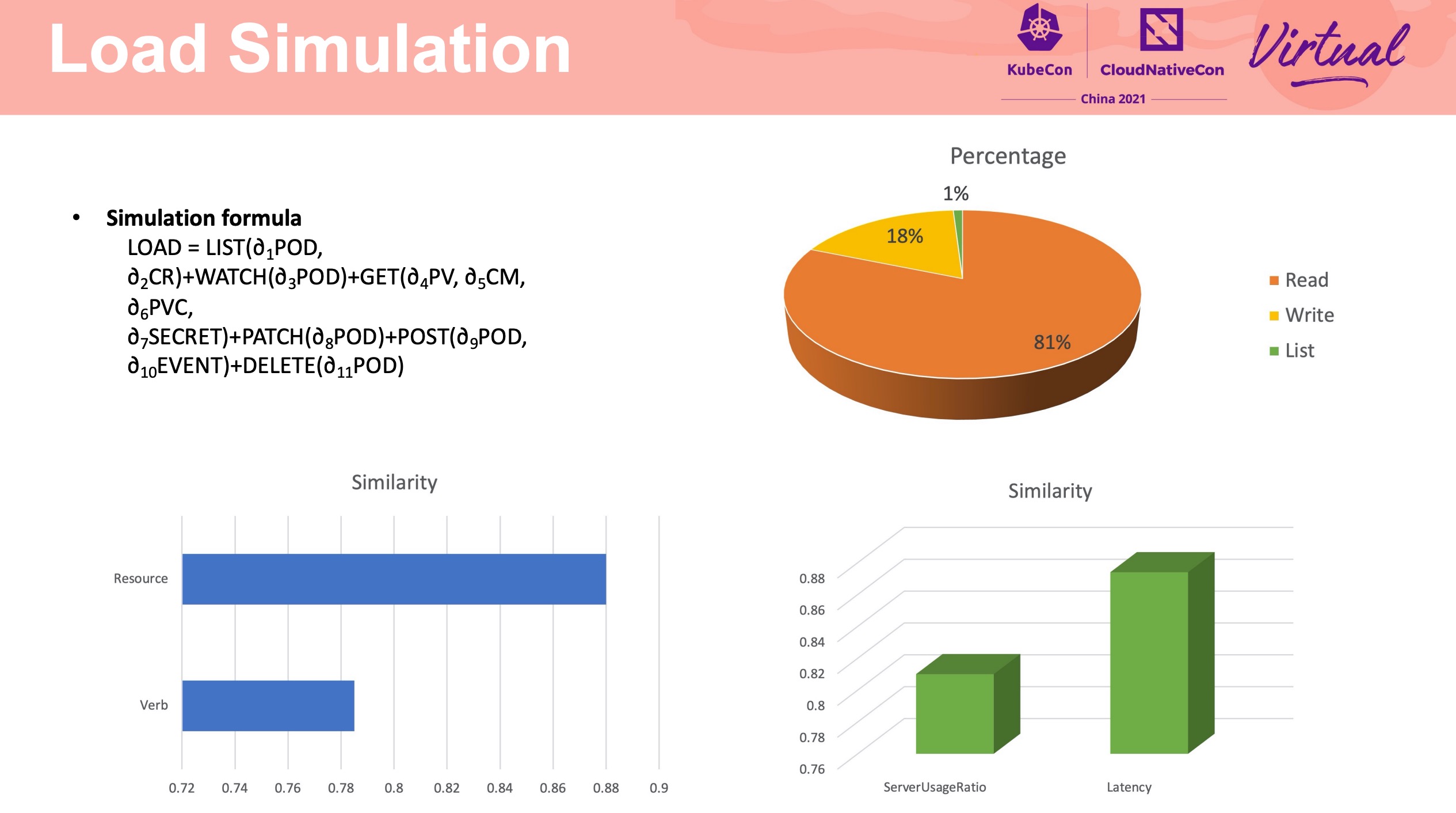
需要做集群请求流量分析与模拟。


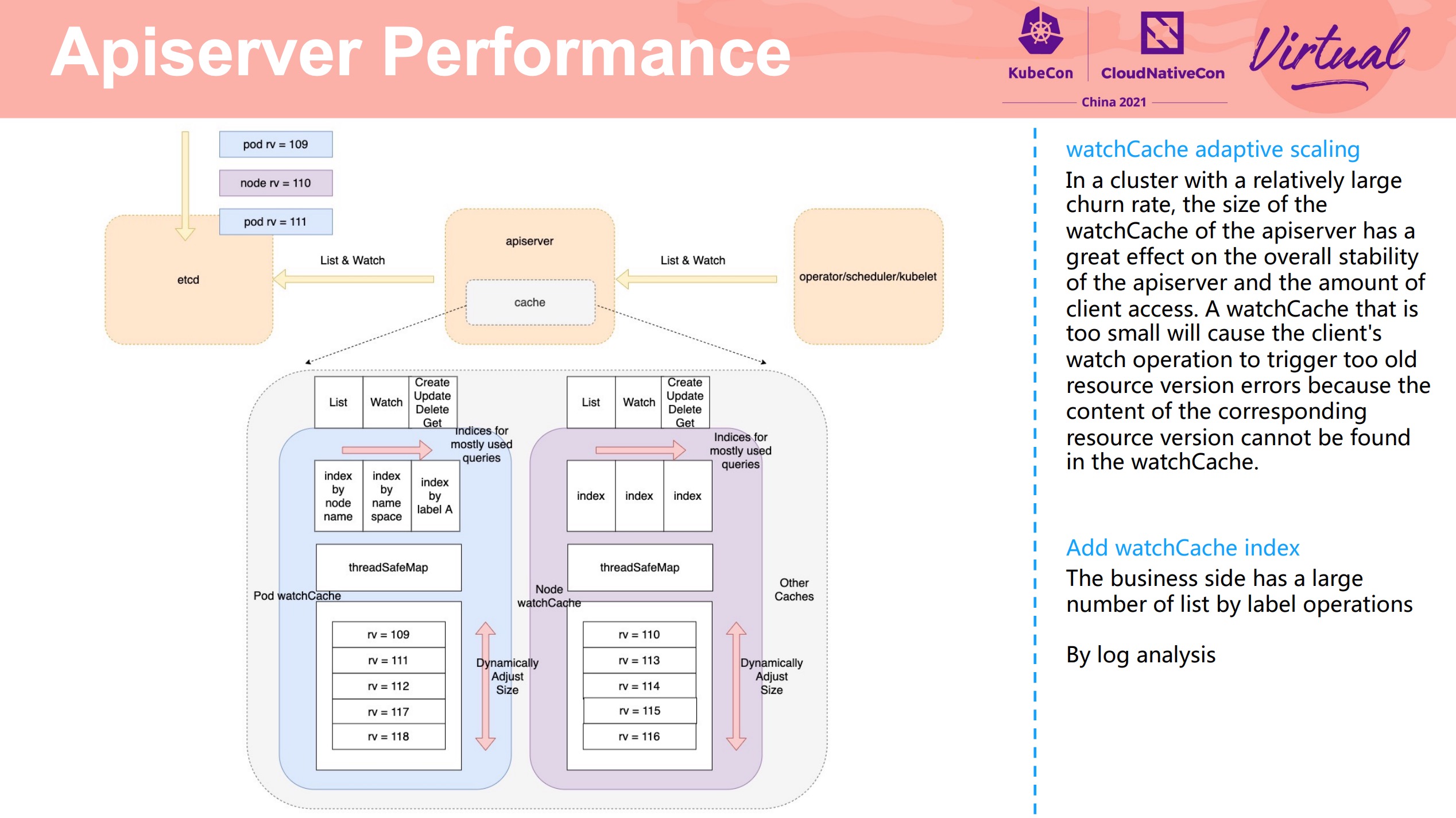


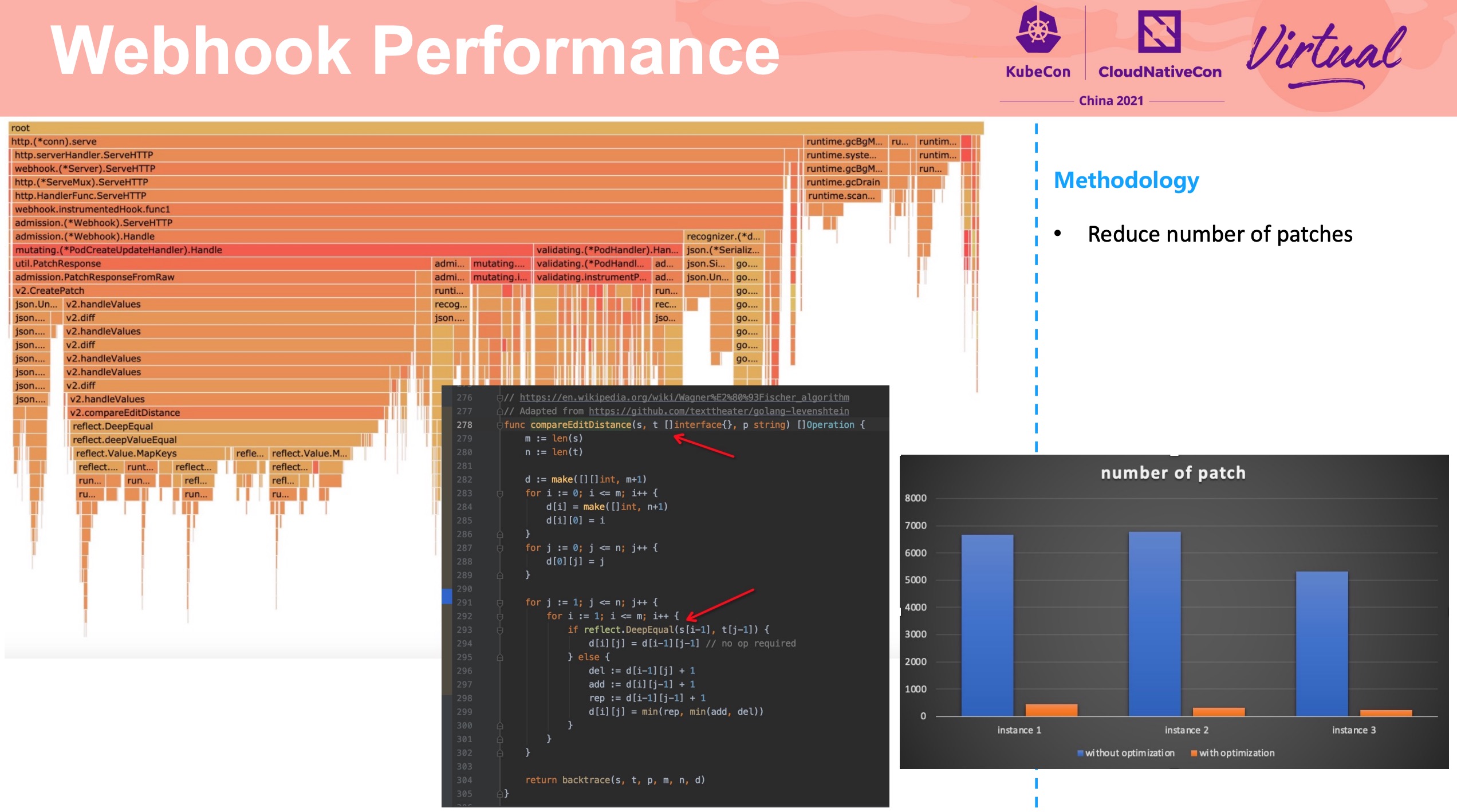
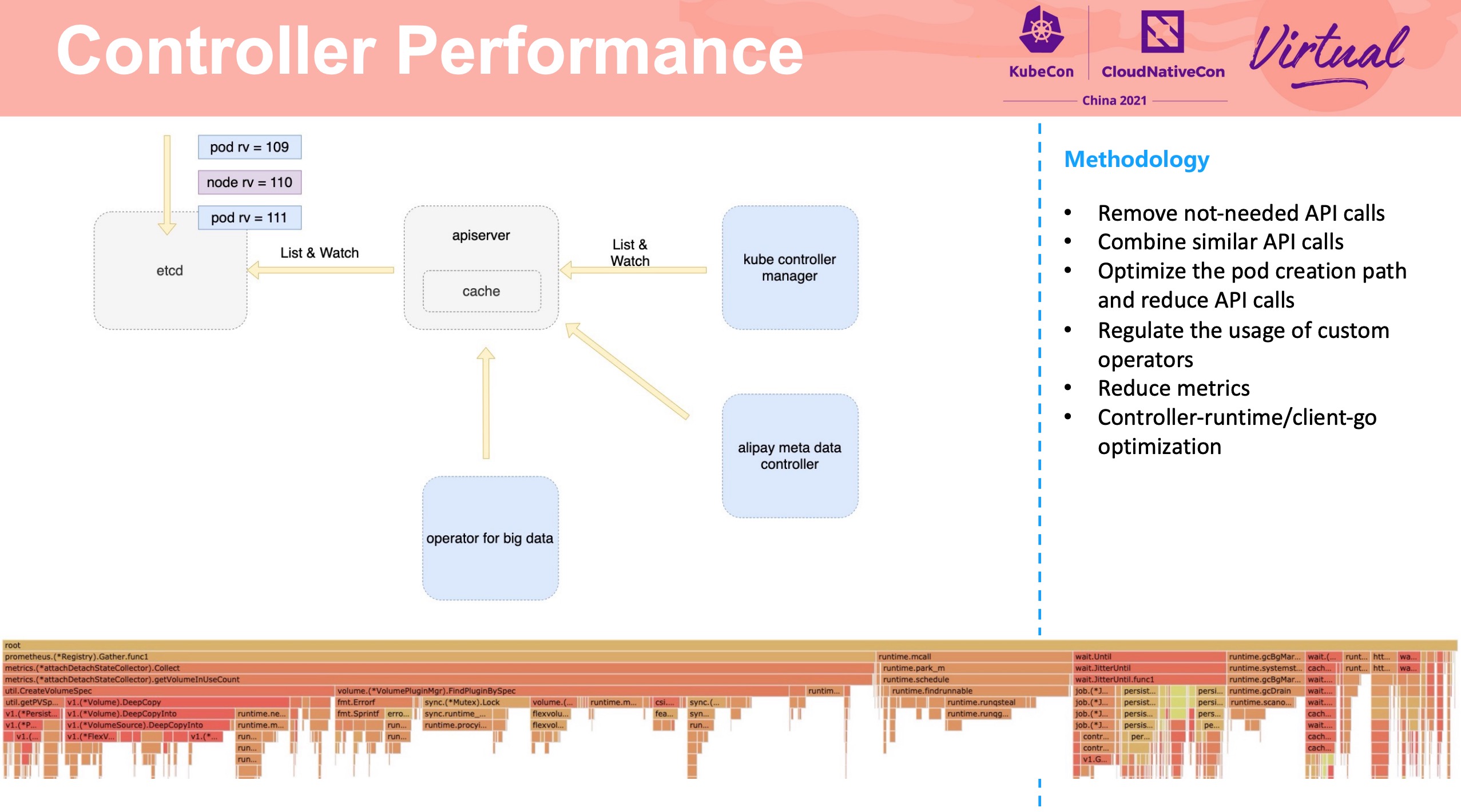
Service Mesh Acceleration From Iptables to Fully BPF
这两天朋友圈都在转发的网红 Session。
具体可以直接看腾讯云原生公众号: https://mp.weixin.qq.com/s/U6-wcBsBC-Khffb7kTBtjA。
Introduction to WasmEdge A Cloud-native WebAssembly Runtime
项目挺有趣的。
主要解决了 WebAssembly 的使用成本问题。
Panel Discussion How to Attract Developers to Join Your Community
非常有意思的 Session。
简单做了一下摘录:
- 做一个好的项目,能实际解决开发者和用户的问题
- 直接的价值交换
- 组织驱动
- 找到定位,区分用户群体
- 上手门槛低,有成长路径
- 消除参与社区的阻力
- 运营者的积极的参与
- 社区流程结构化
- 需要主动站出来做一些事情
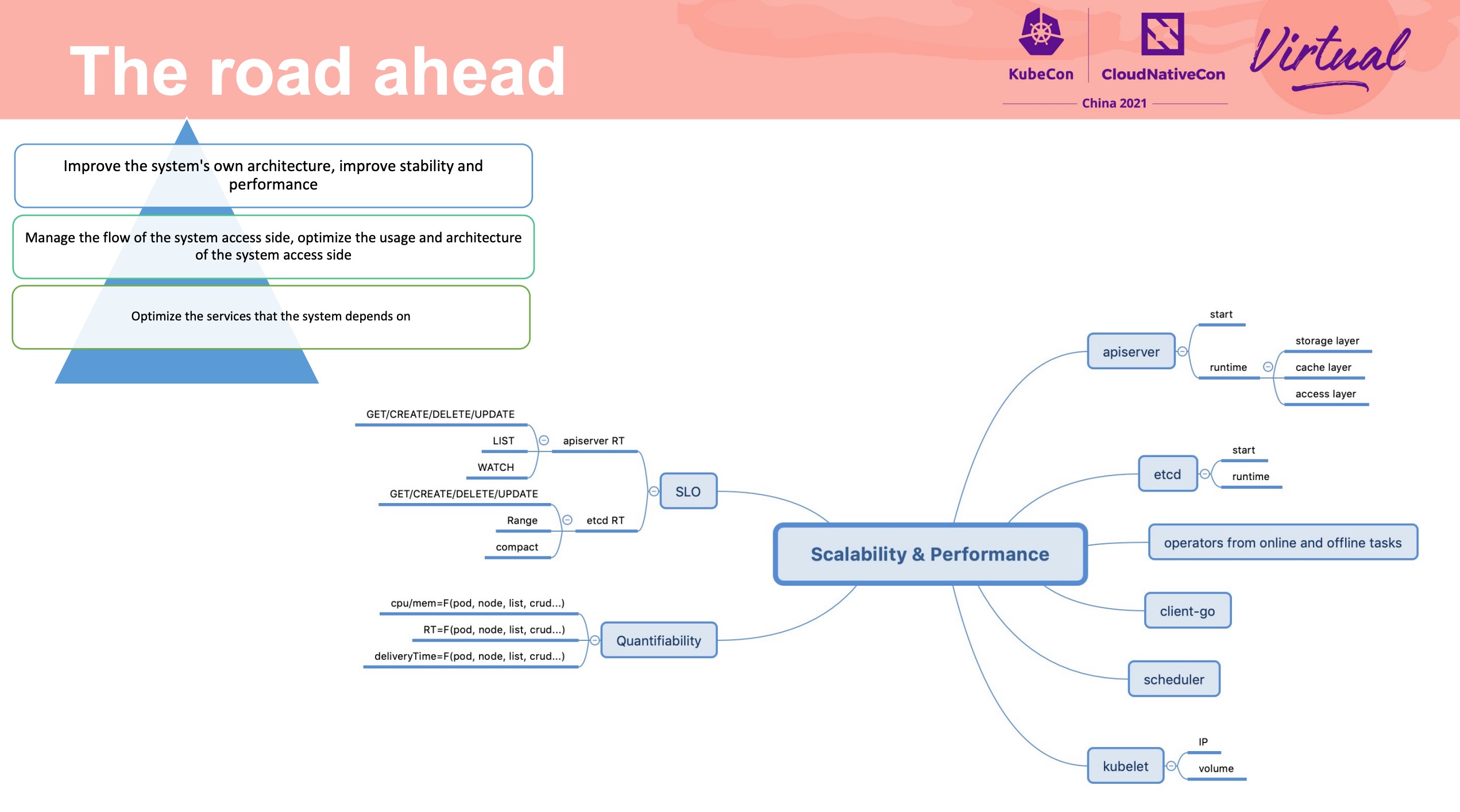
Managing Large-Scale Edge Cluster Over Unstable Network with KubeEdge
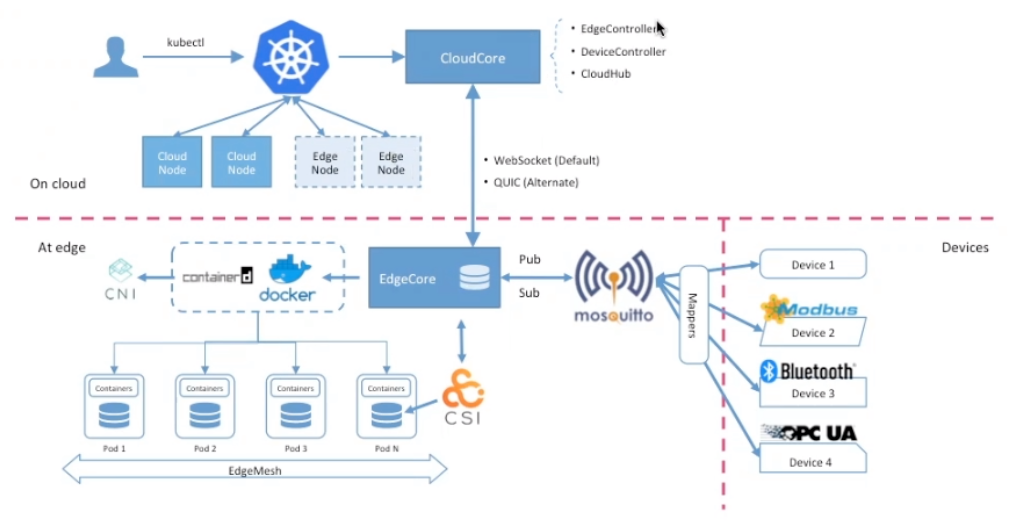
通过 WS + QUIC 替代 List & Watch,在不稳定的网络环境下避免大量重复传输造成的带宽浪费。
- 增量传输
- 每次传输做响应,避免传输失败
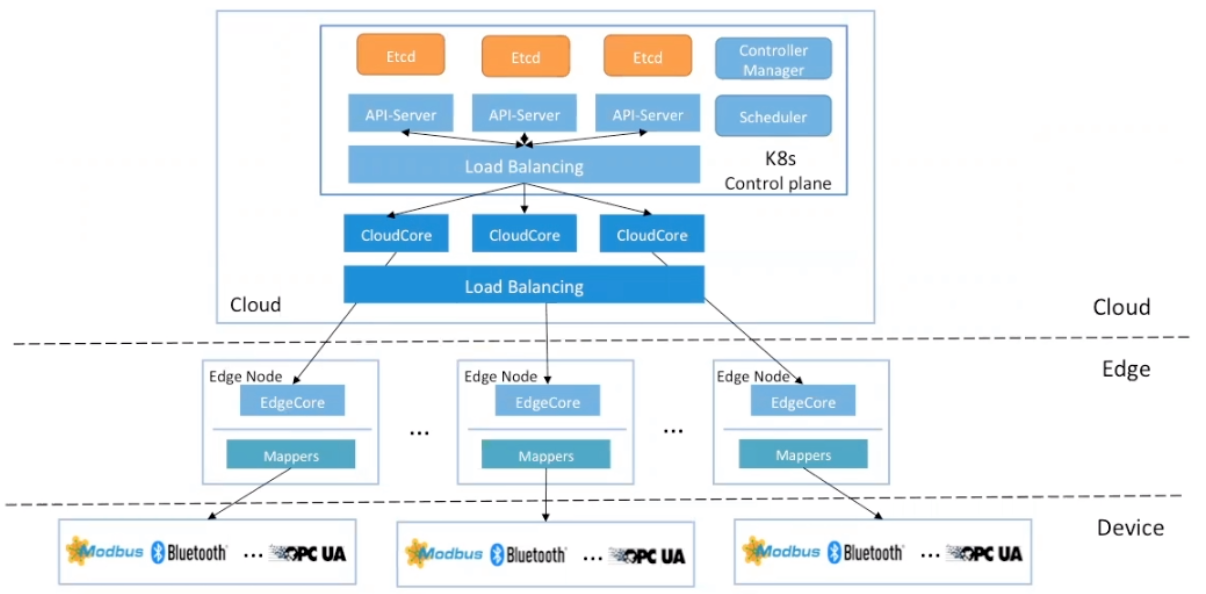
通过 CloudCore 支撑更多的节点。
How to Build Your Cybersecurity Toolkits with Open Source Tools
来自 Aqua 的 Session。
基于边界保护在云原生场景下不是很适用。
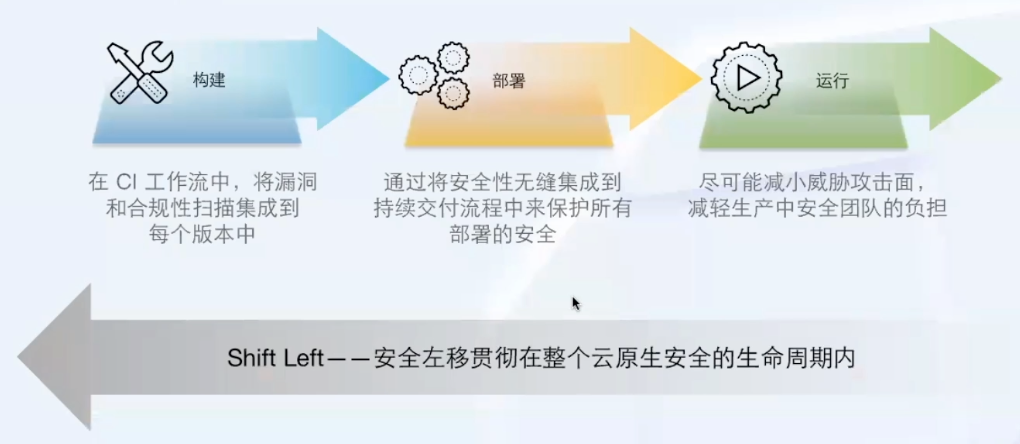
左移翻译成“前置”是不是好一些,感觉“事前”也有点牵强。
下面这张图作为补充更合适:

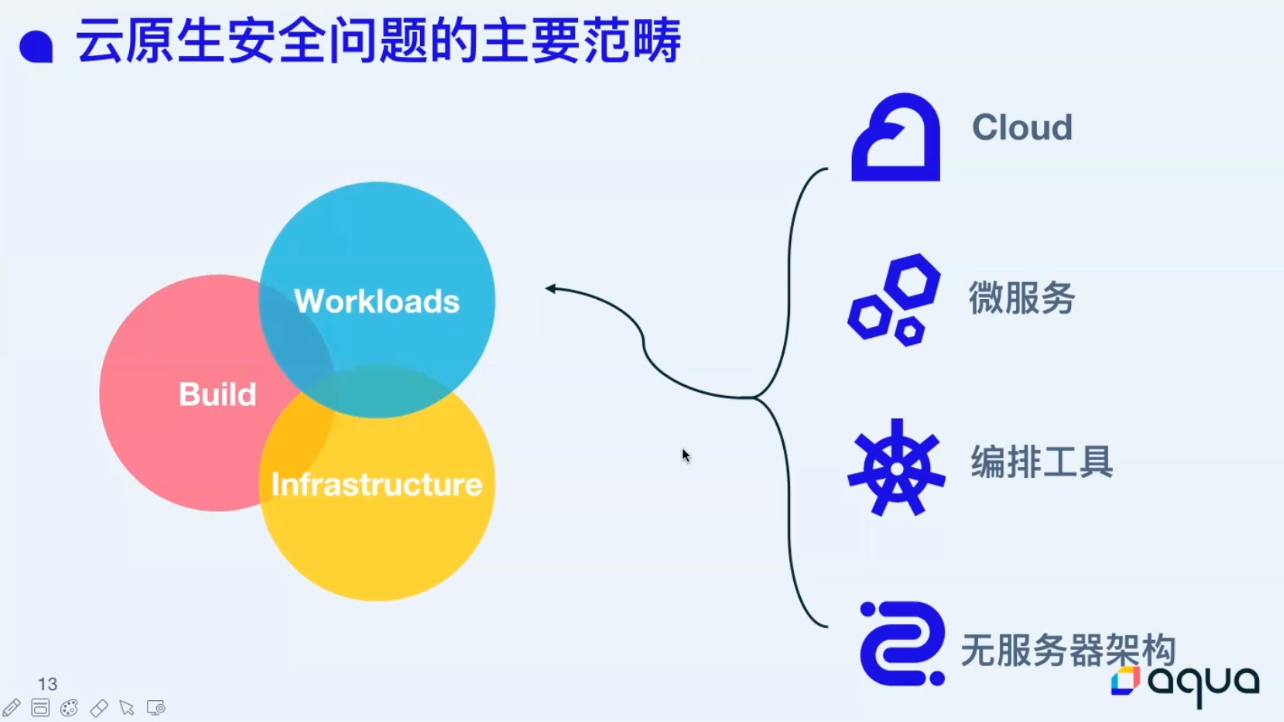

供应链攻击是重中之重,感觉云原生场景下供应链攻击的相关资料真不多。

Aqua 全家桶。


How To Migrate Kubernetes Cluster With Zero Downtime
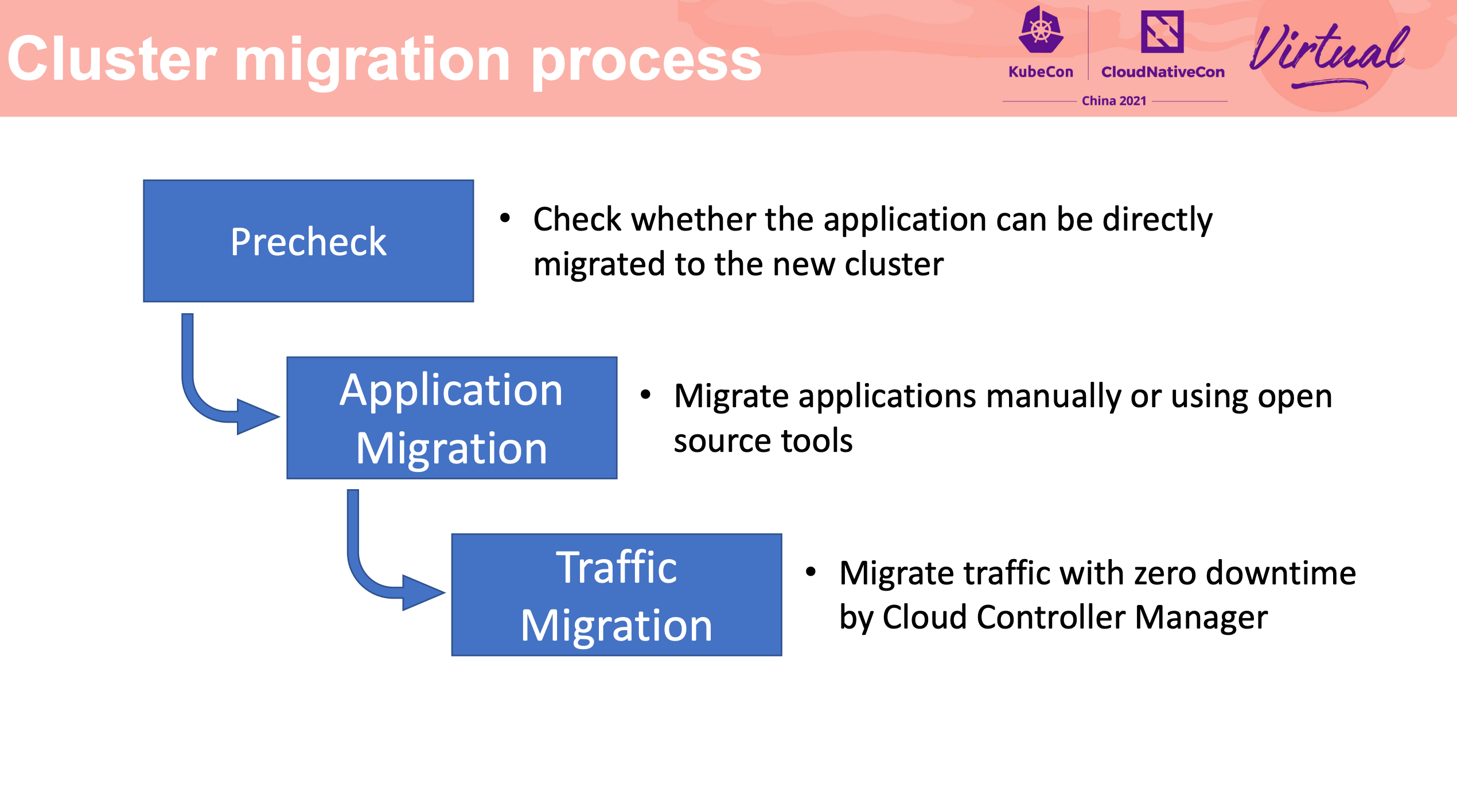

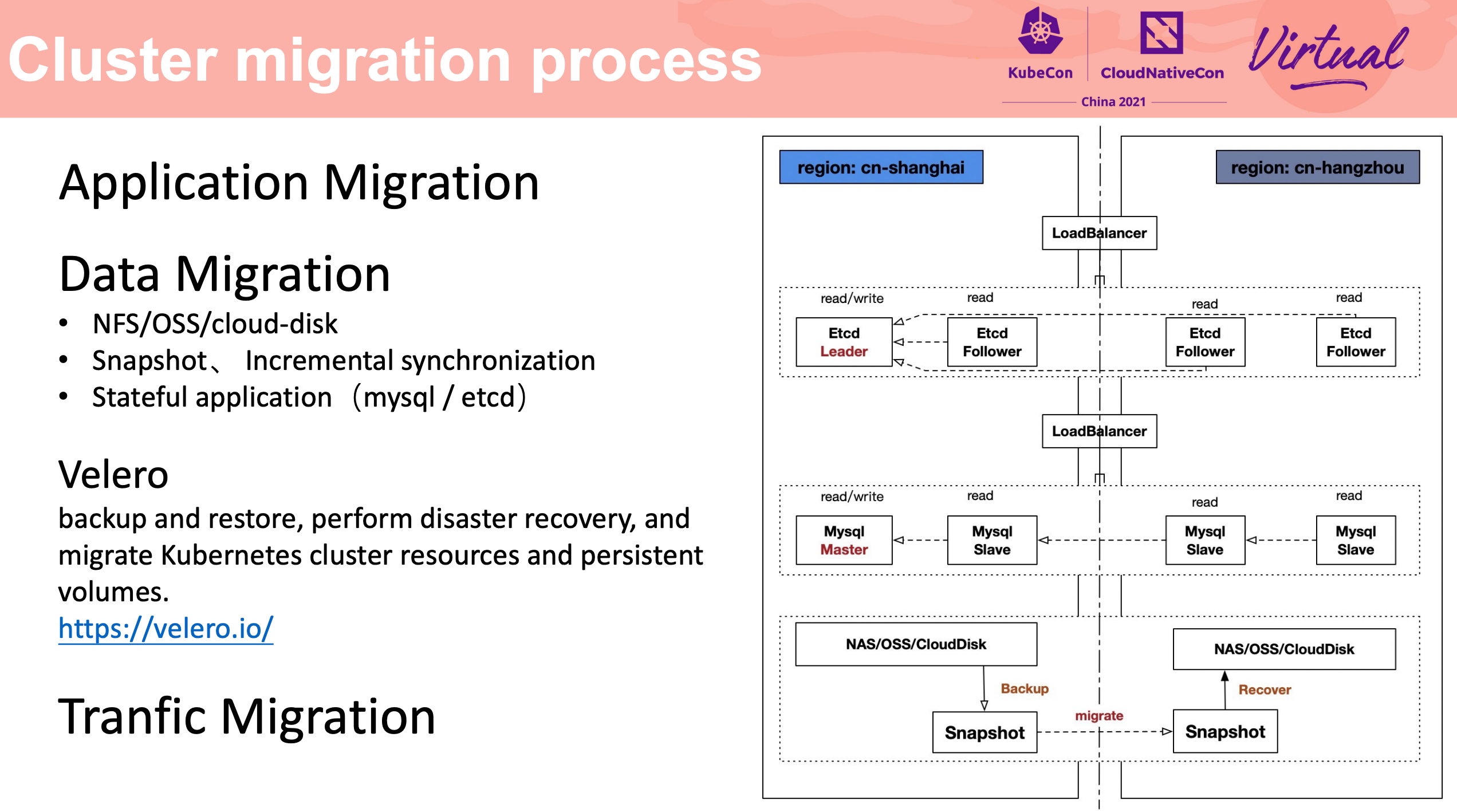
Stateful Application 的迁移还是要靠应用自身的能力来完成啊。
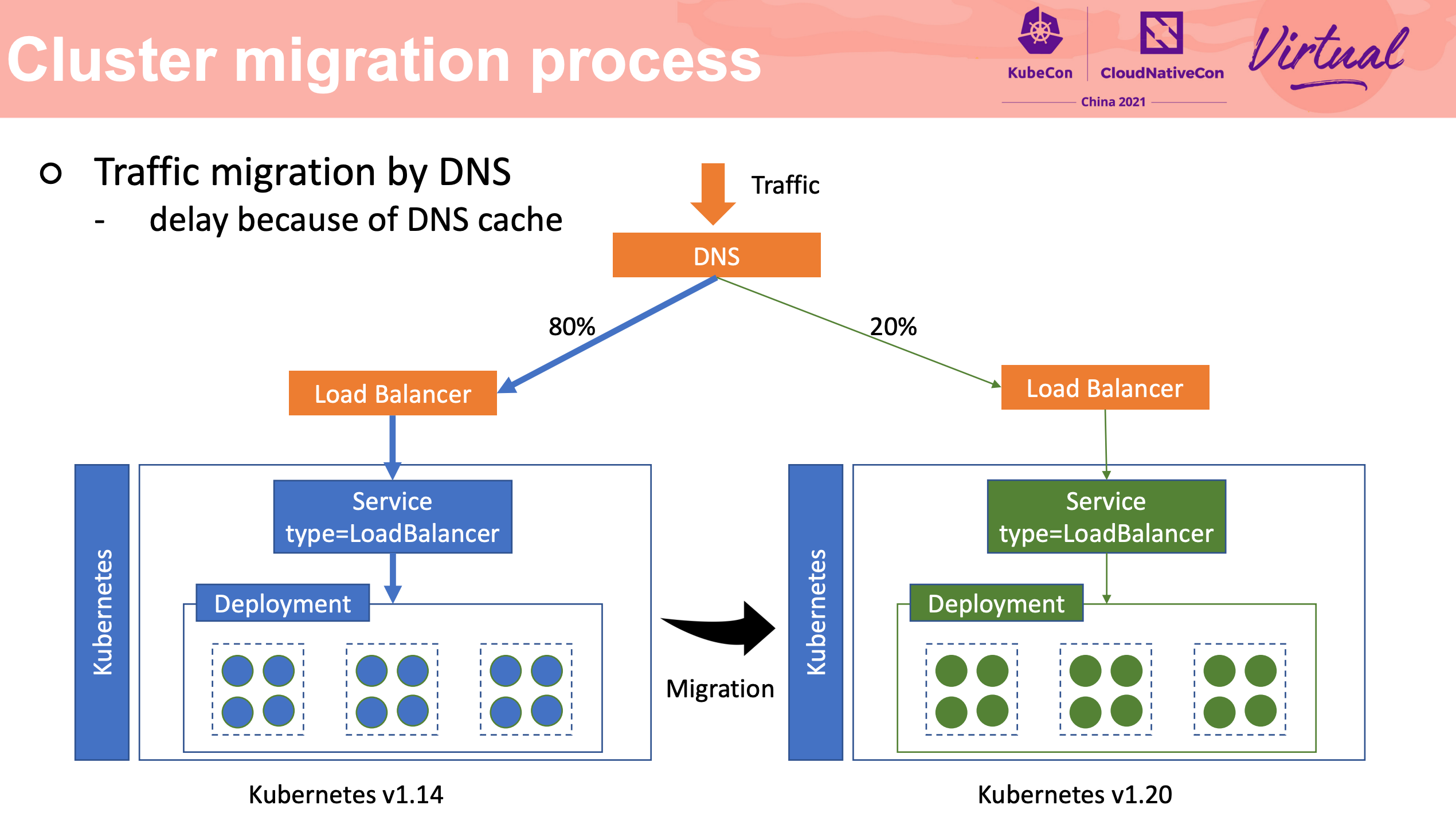

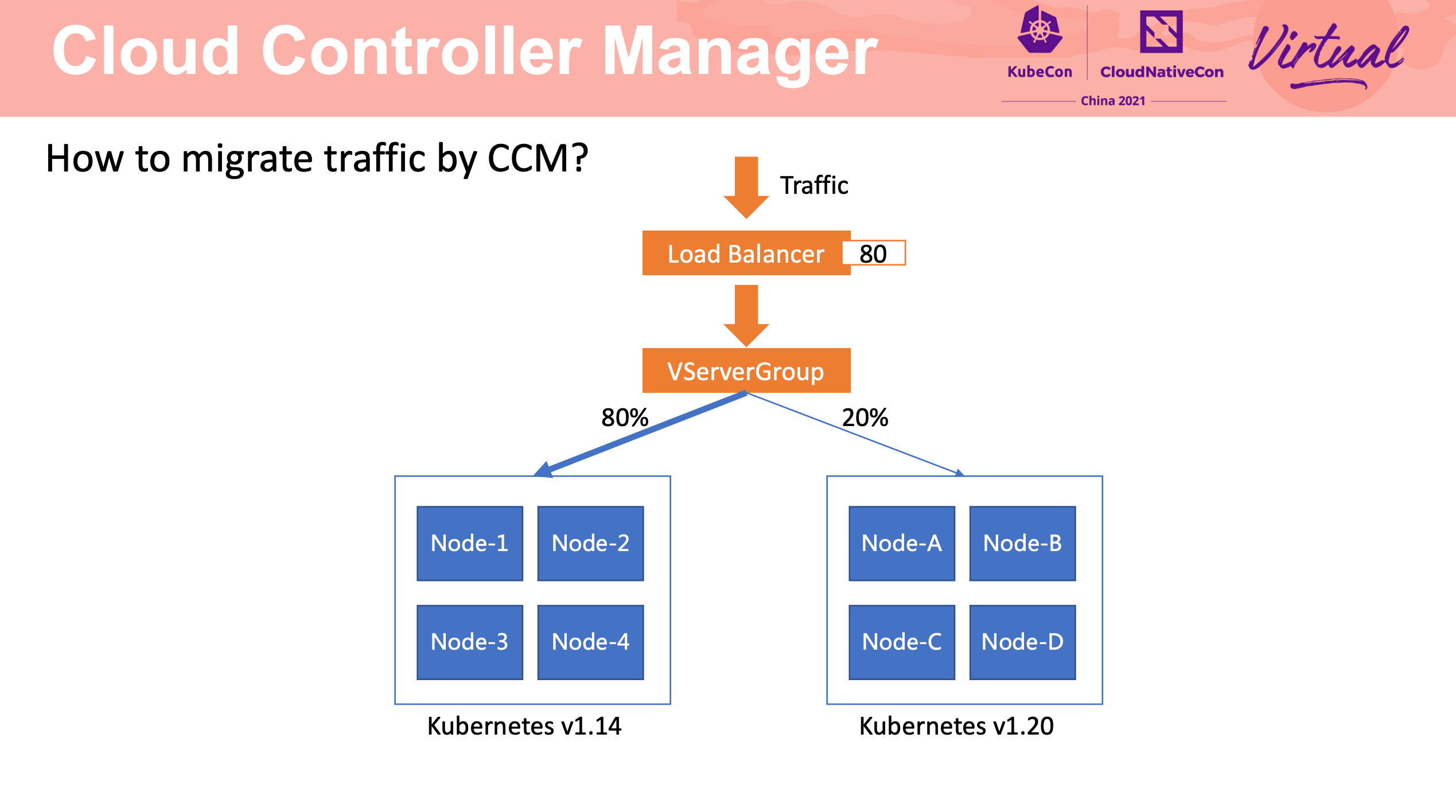
流量迁移主要还是 LB + Cloud Controller Manager。
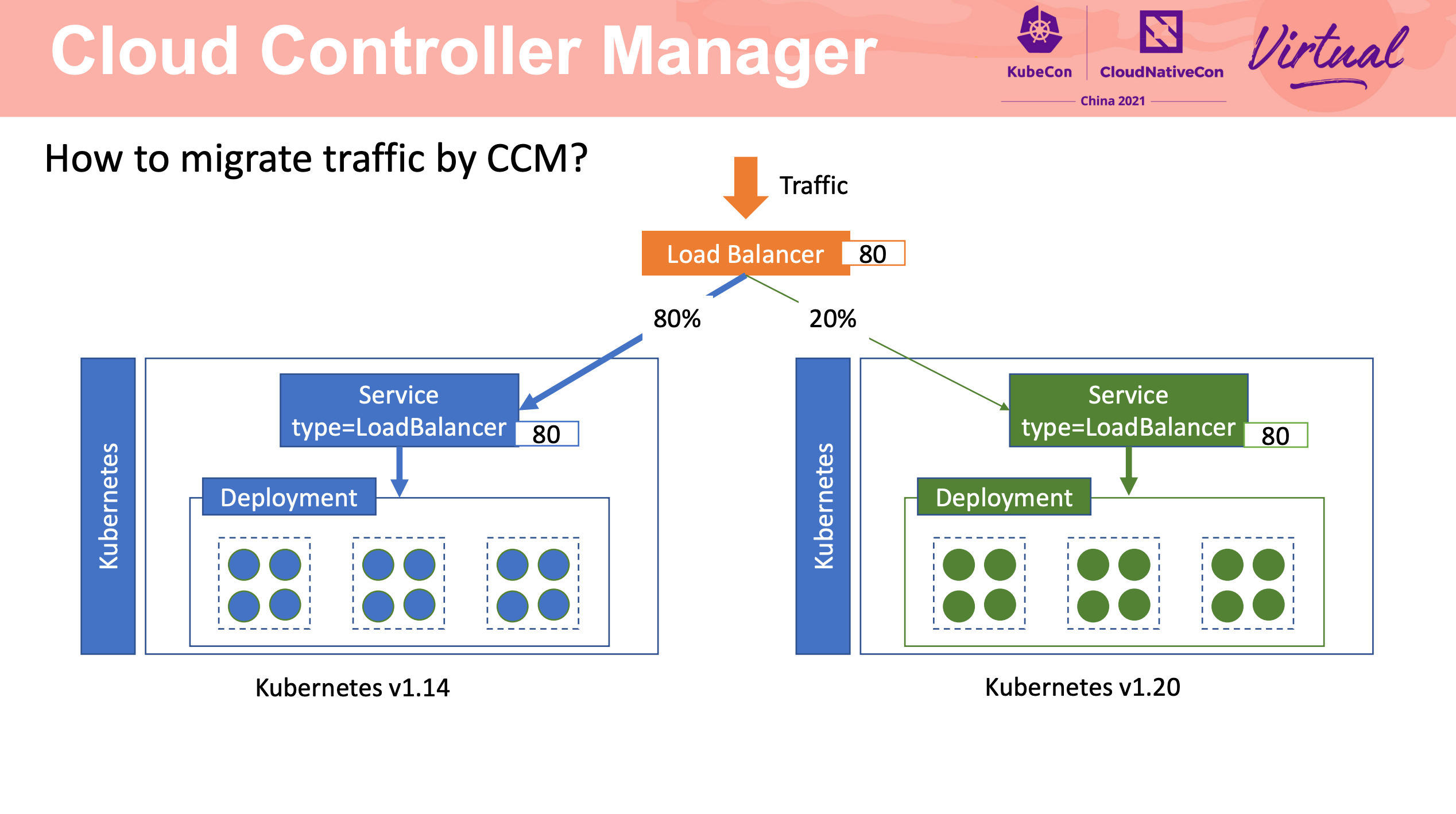
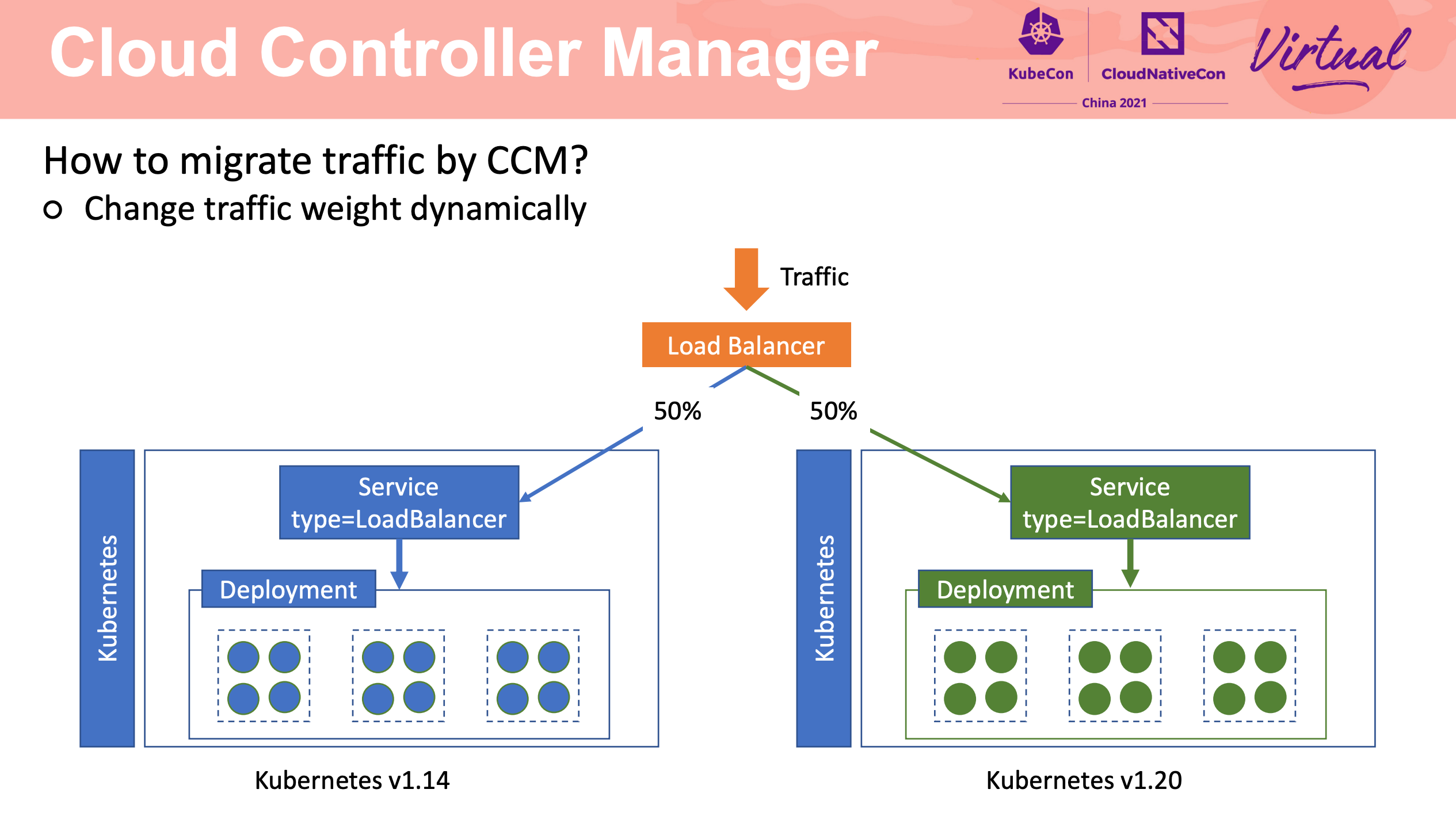
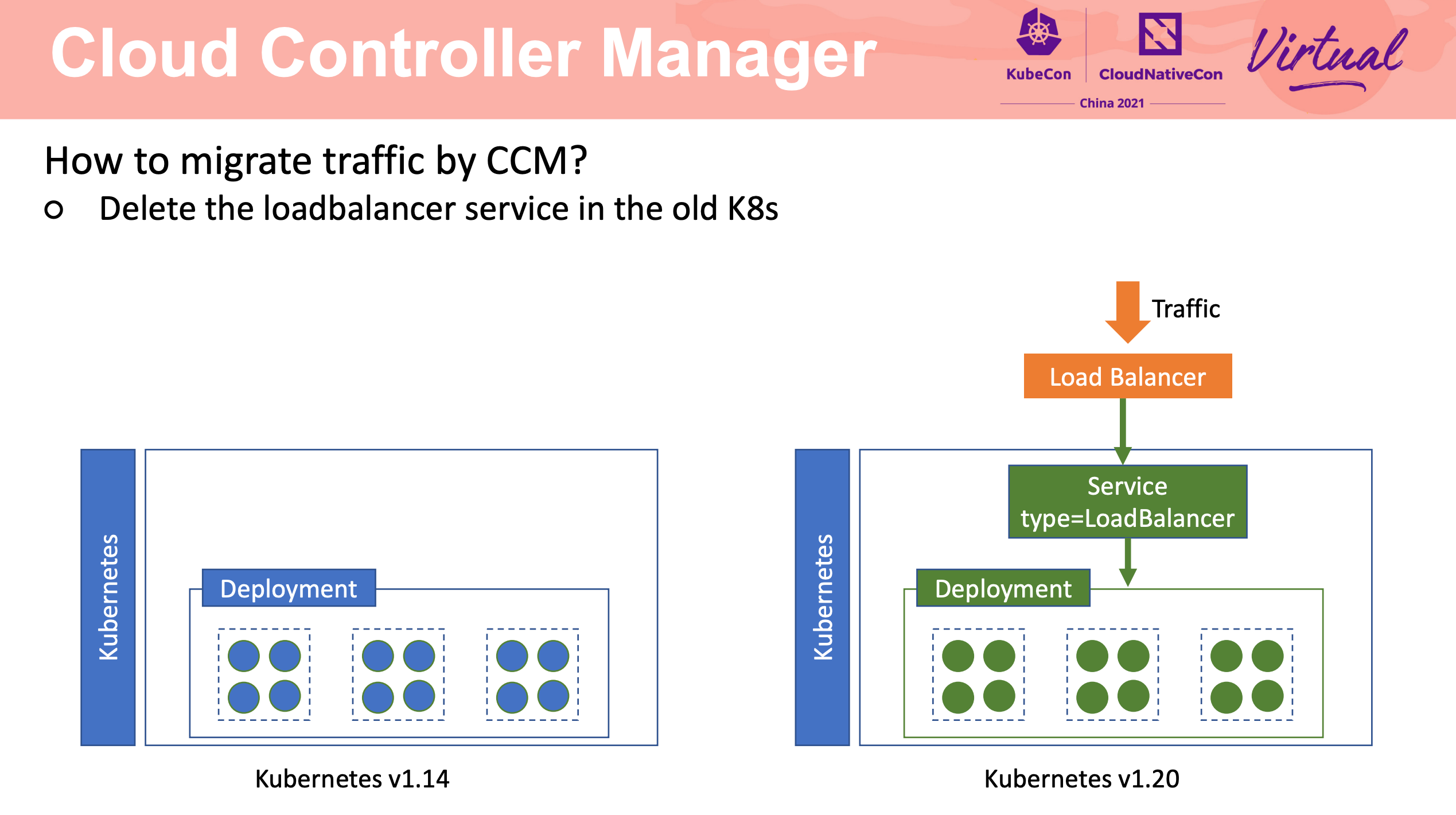
可以说非常值得网关产品借鉴。

依赖健康检查的正确配置、容器的优雅退出。
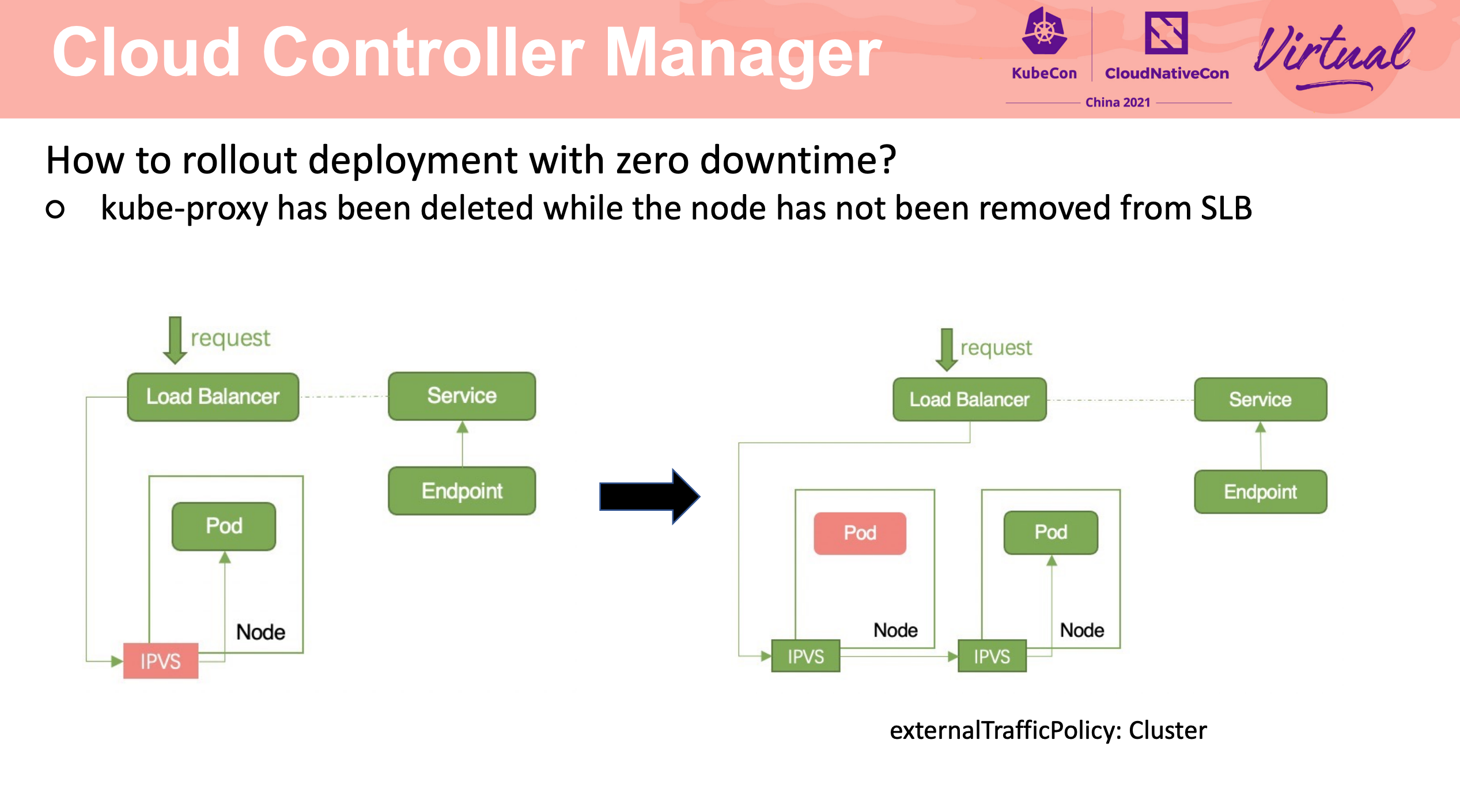
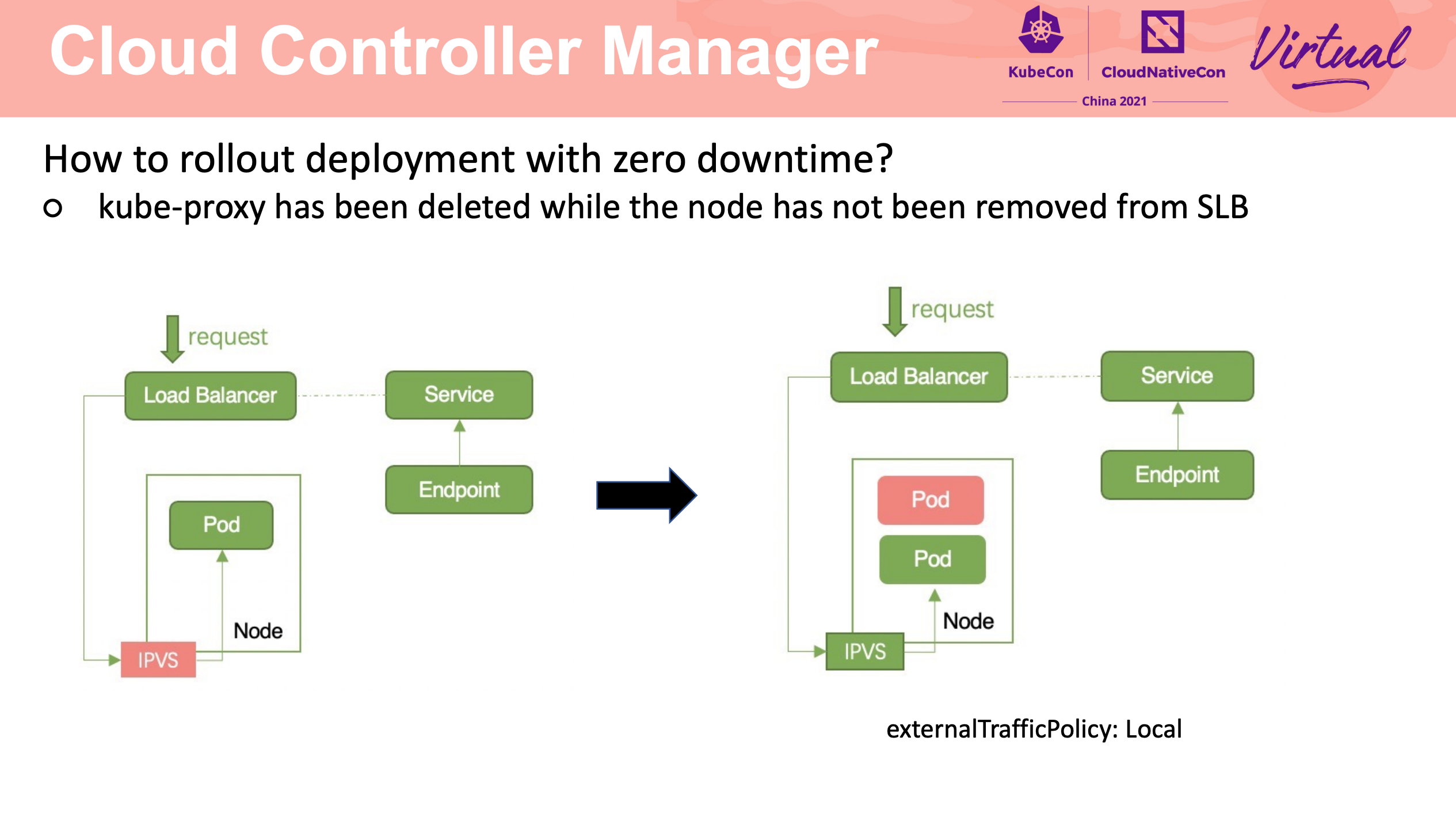
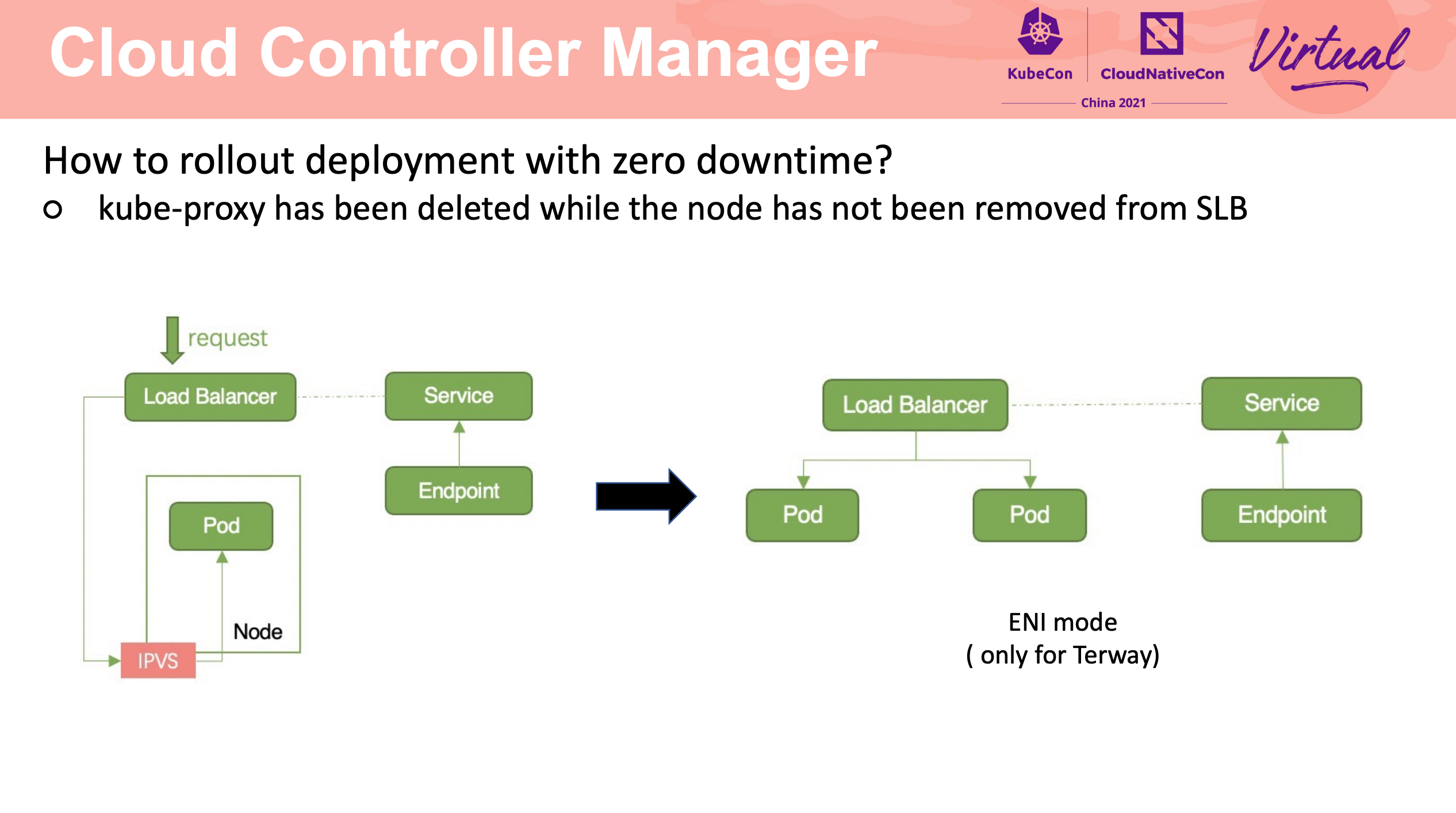
kube-proxy 最靠谱的使用方式就是不用 kube-proxy。
Bagua Lightweight Distributed Learning on Kubernetes
可以说是非常期待的 Session。
Bagua 刚开源的时候就在关注:
又回到了 100 张卡训个 Bert 的场景。 多机多卡并行训练,好多公司既没能力,也玩不起。 Bagua 看起来比 DDP 靠谱多了。
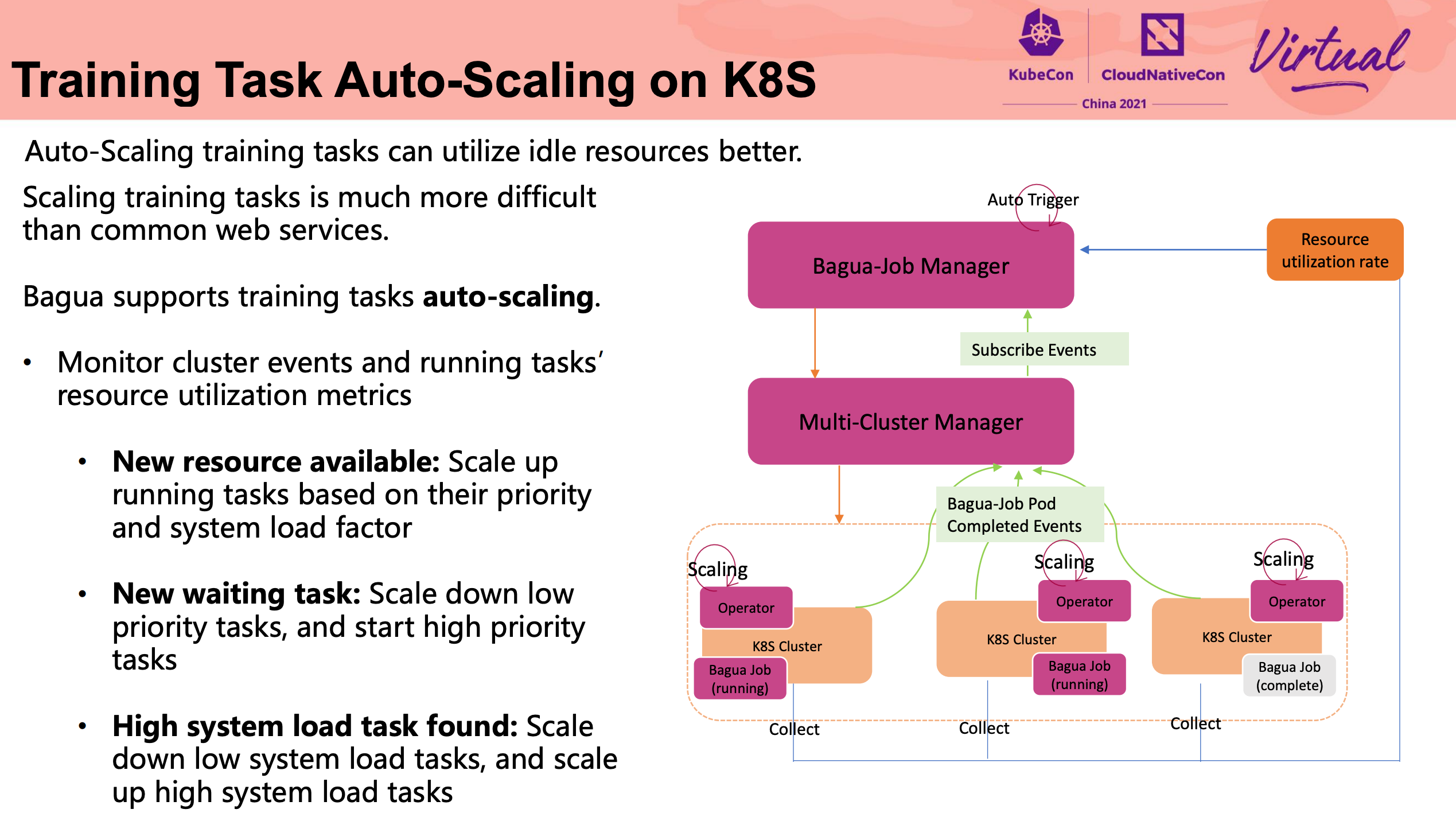
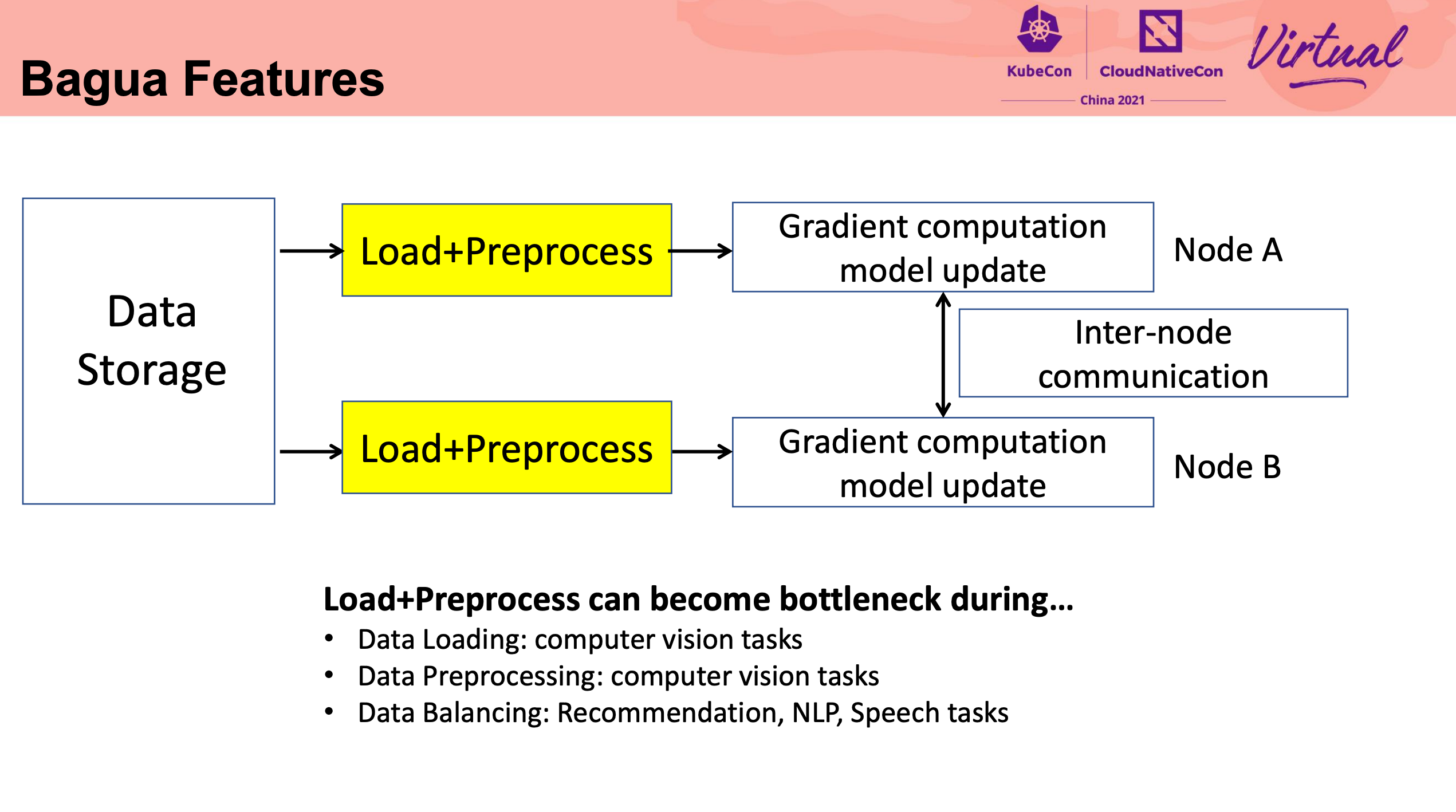
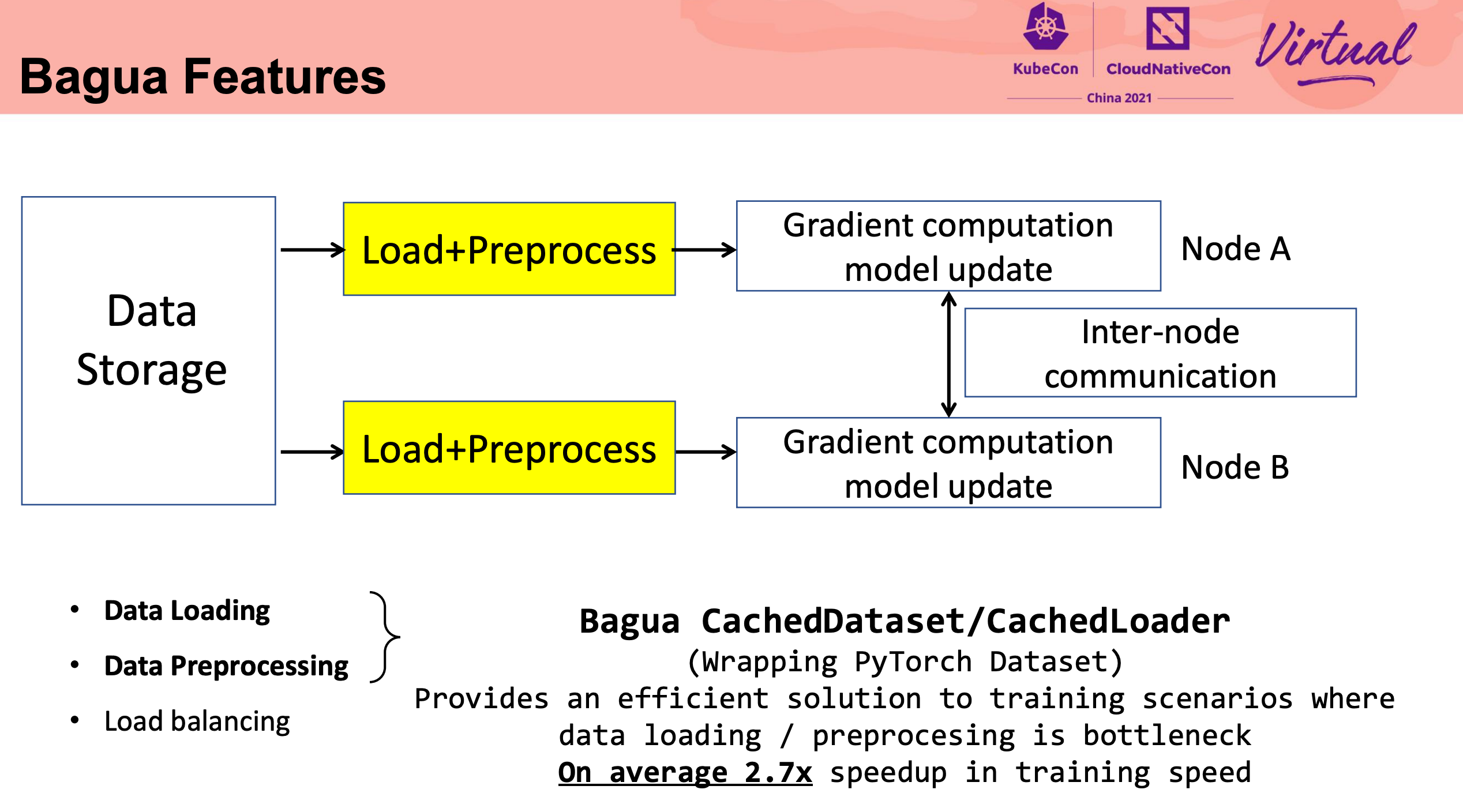
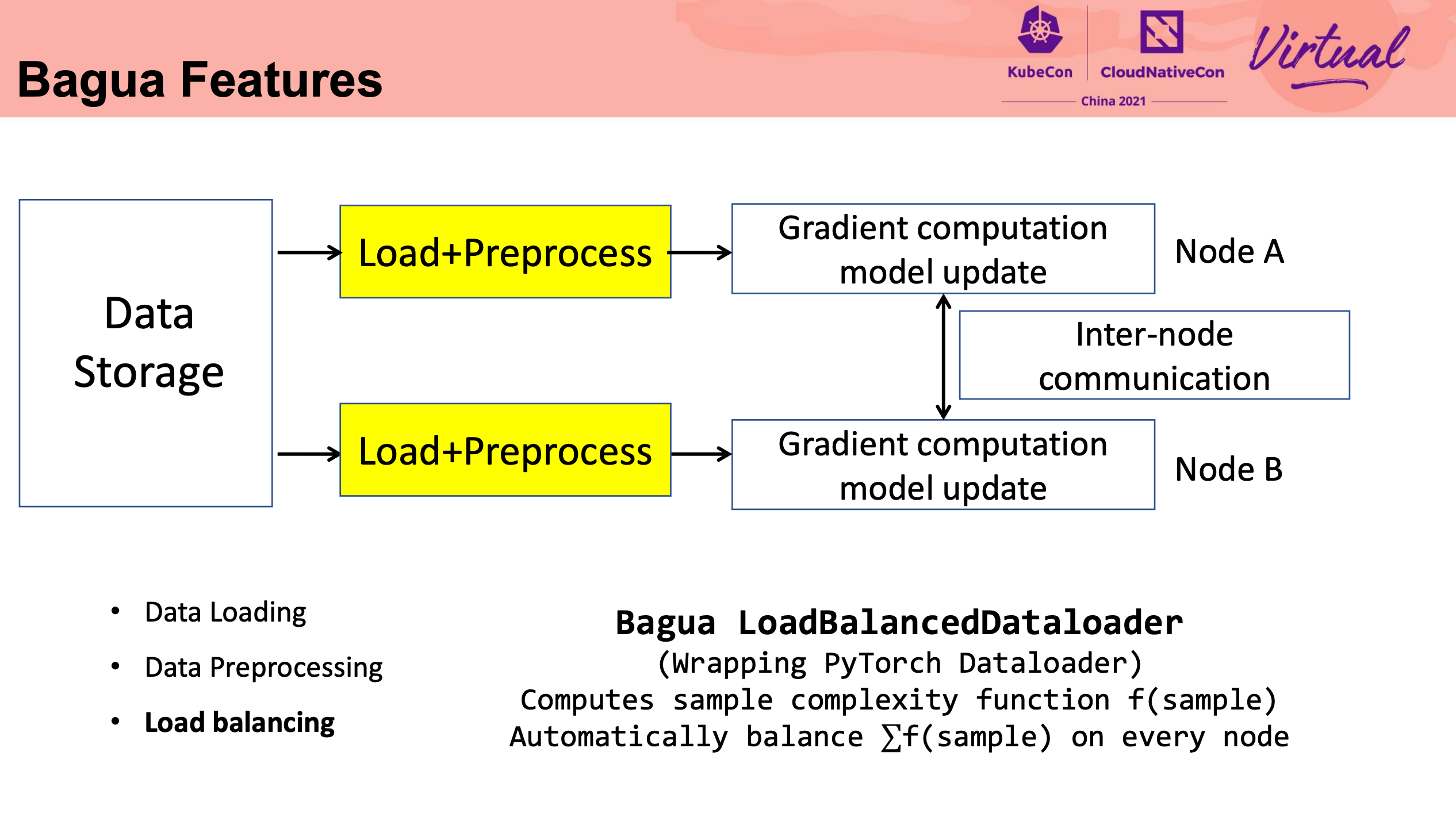
这块细节比较多,还是直接看代码比较好。
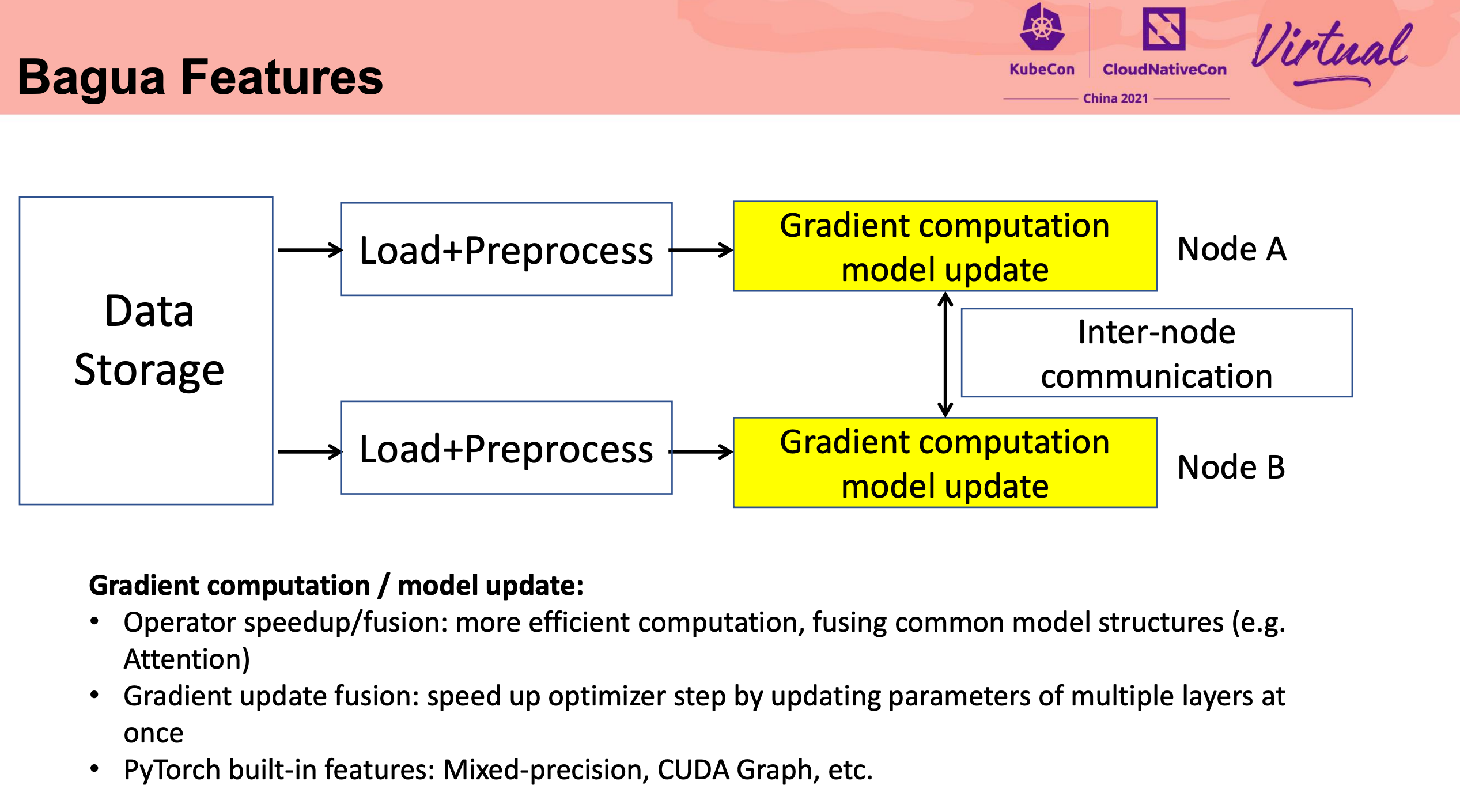
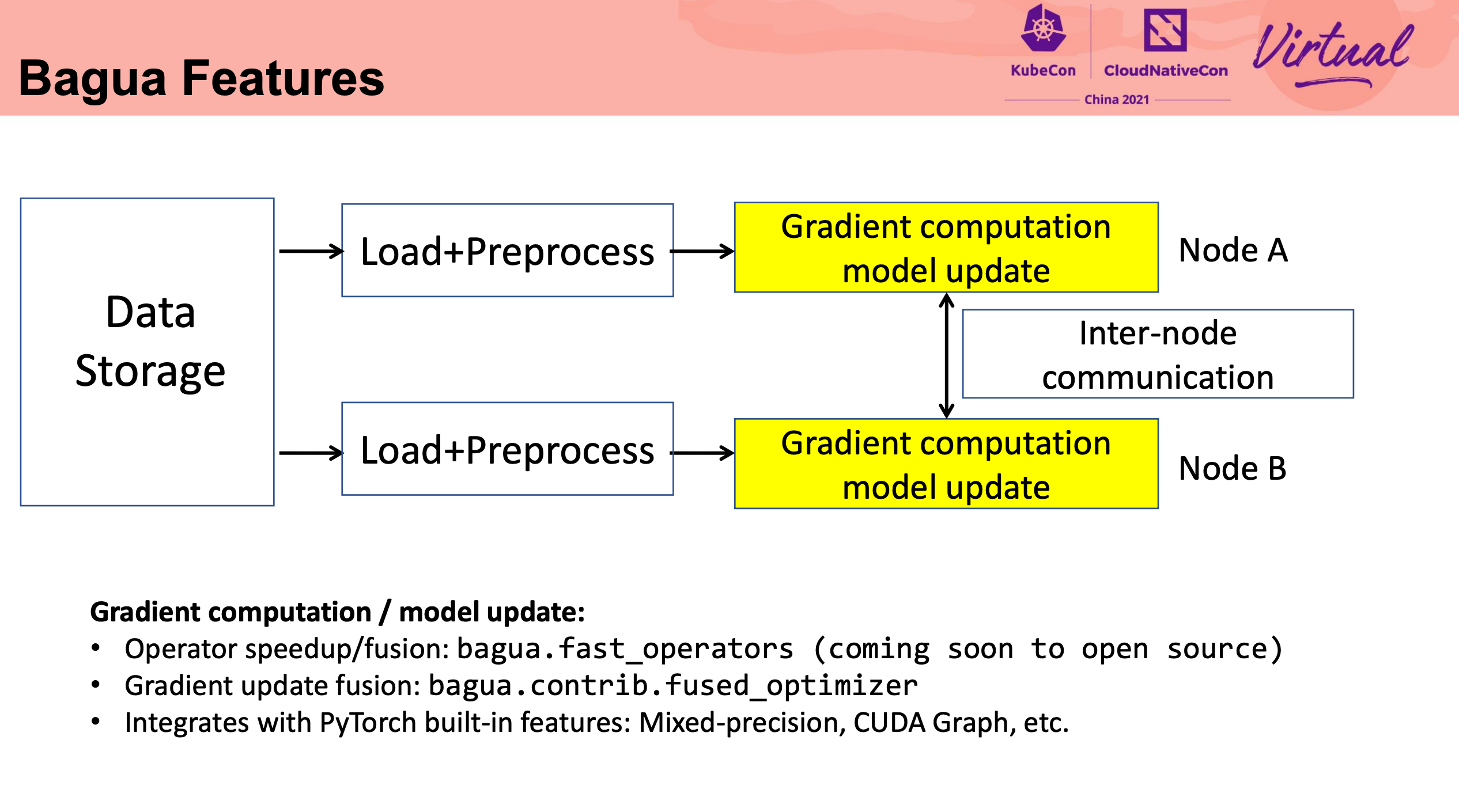
直接重写 NCCL 可还行。
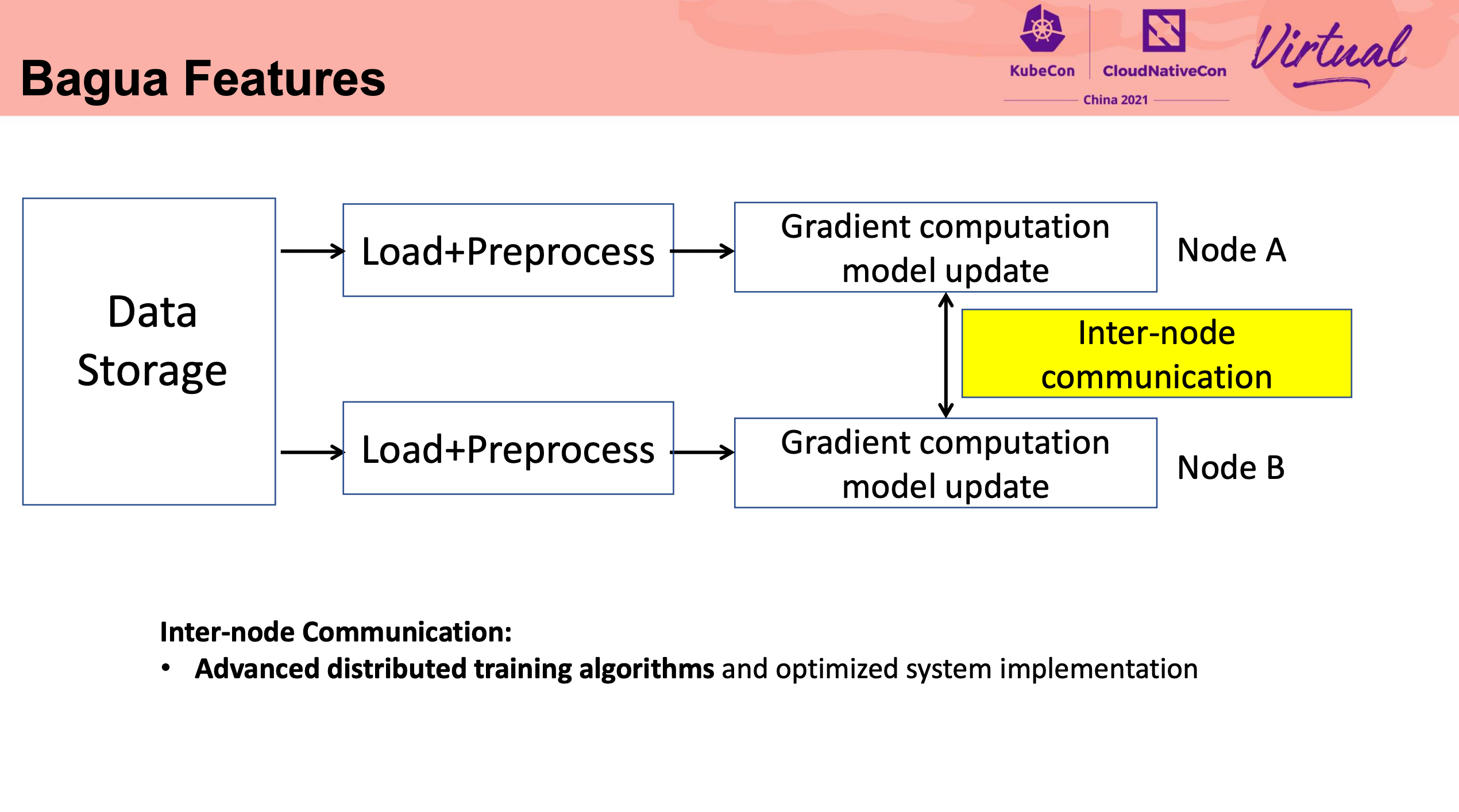

Bagua 命名的由来非常有趣。
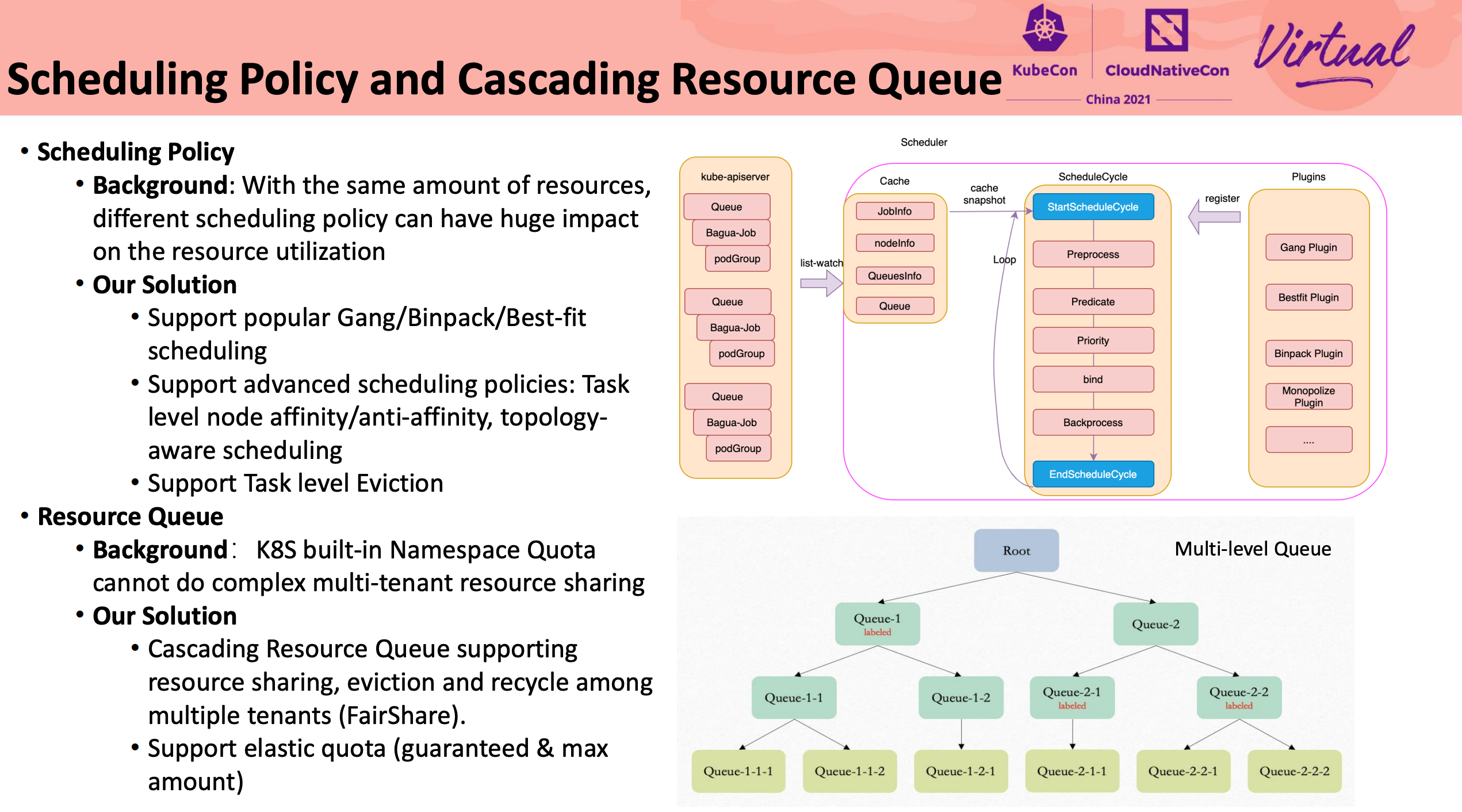
Exploration About Mixing Technology of Online Services and Offline Jobs Based on Volcano
感觉 Volcano 的设计比 Kubernetes Scheduling-Framework 好一点。
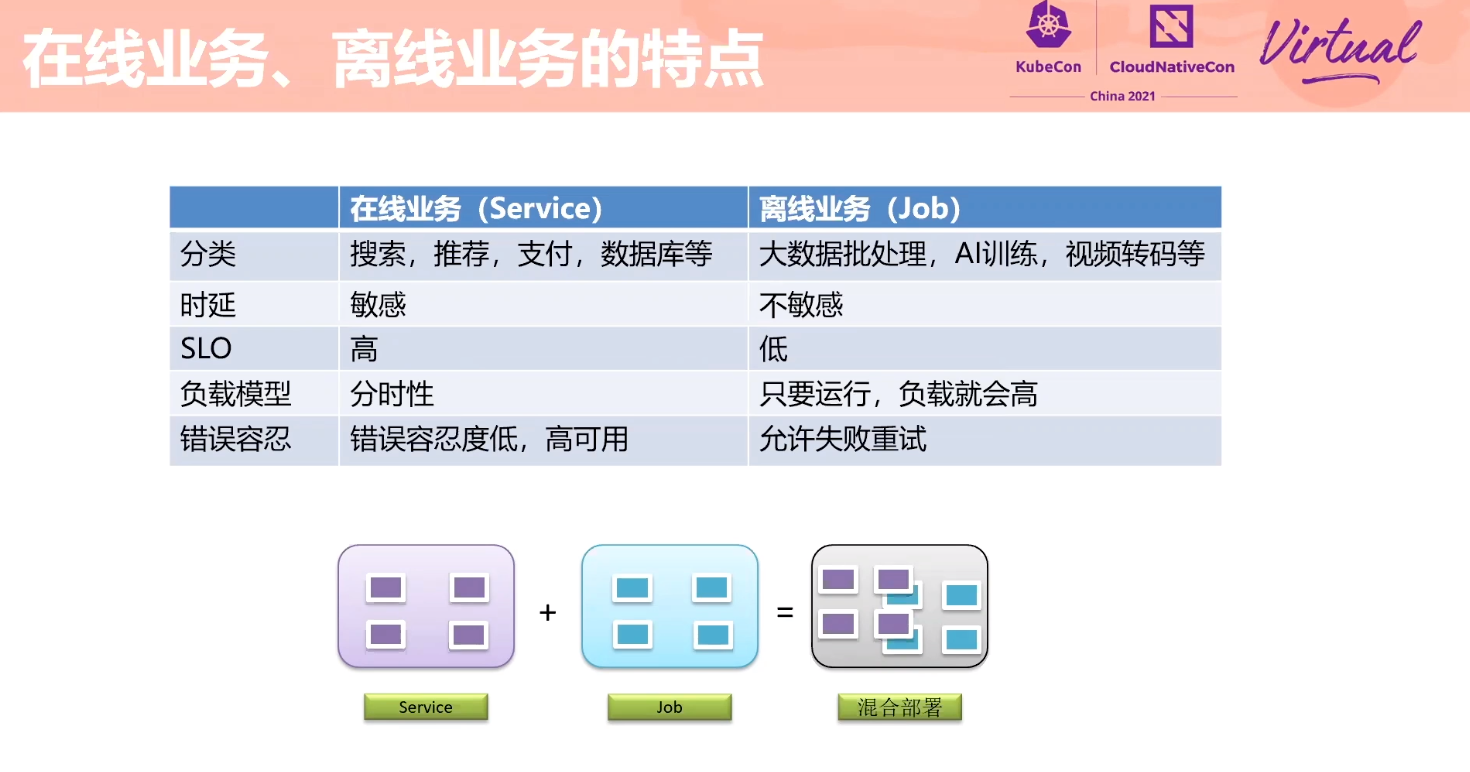

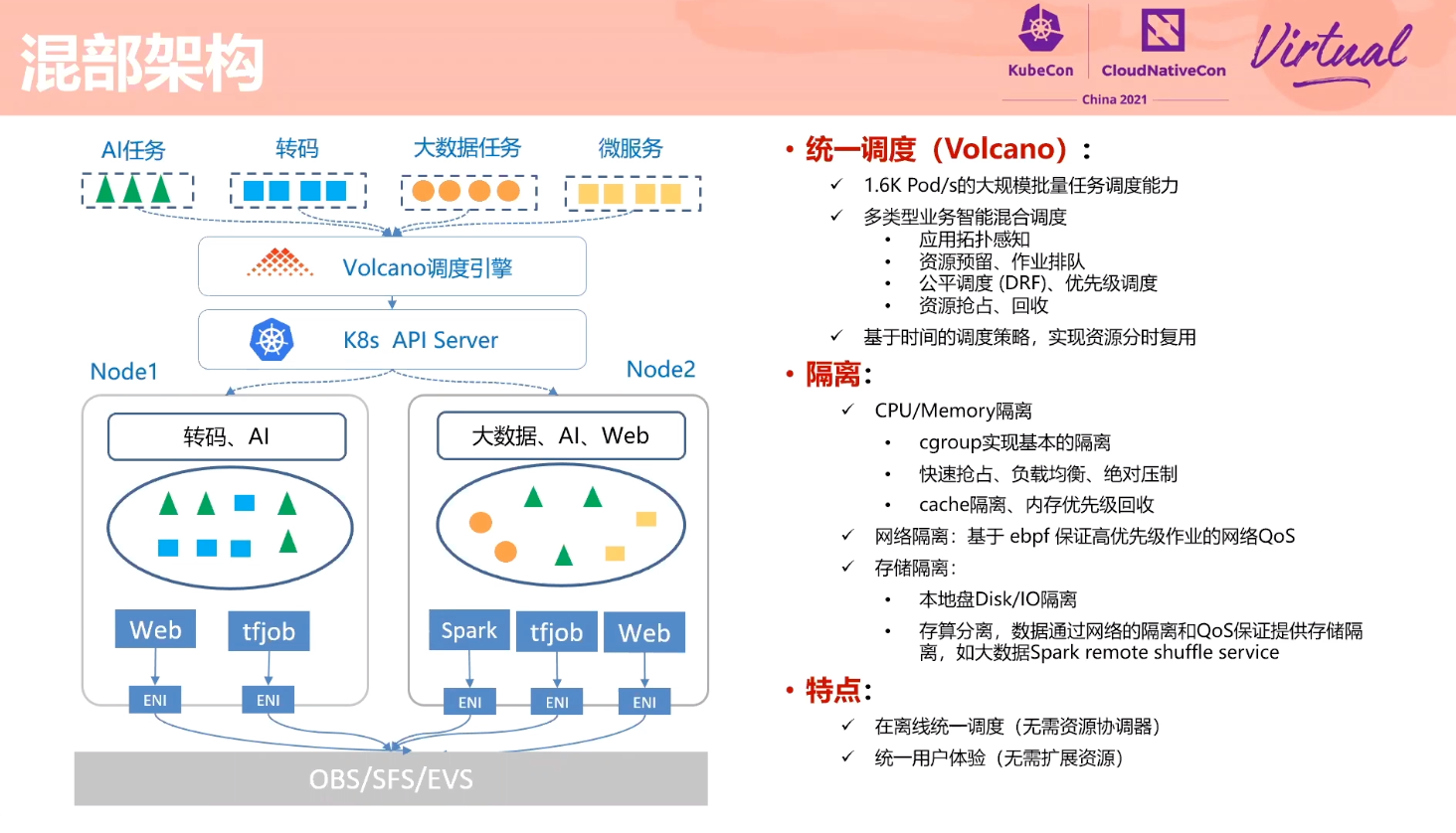
细节不是很多,L3 Cache 隔离怎么实现的没展开讲。

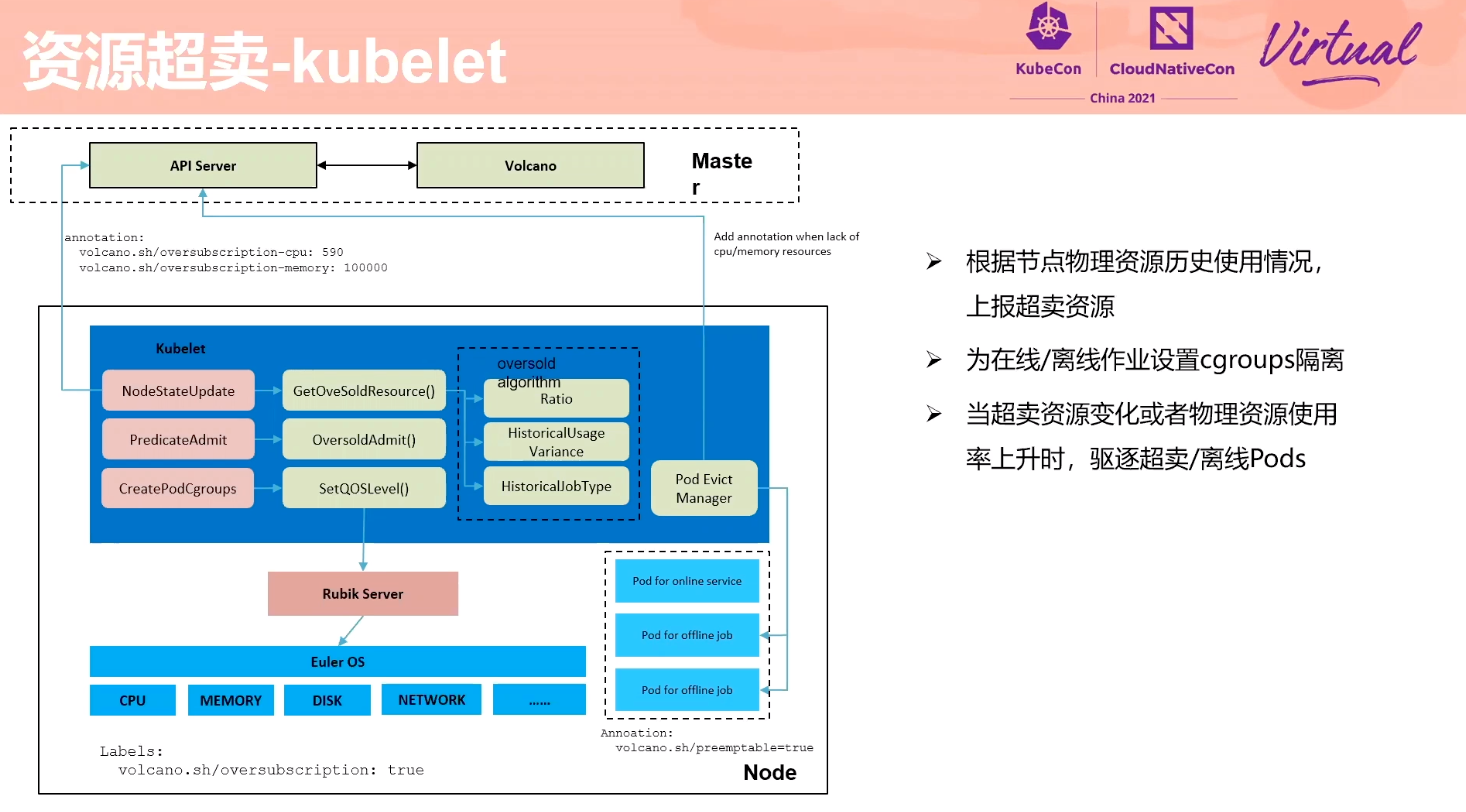
也要魔改 kubelet。 kubelet 应该提供一个插件机制。
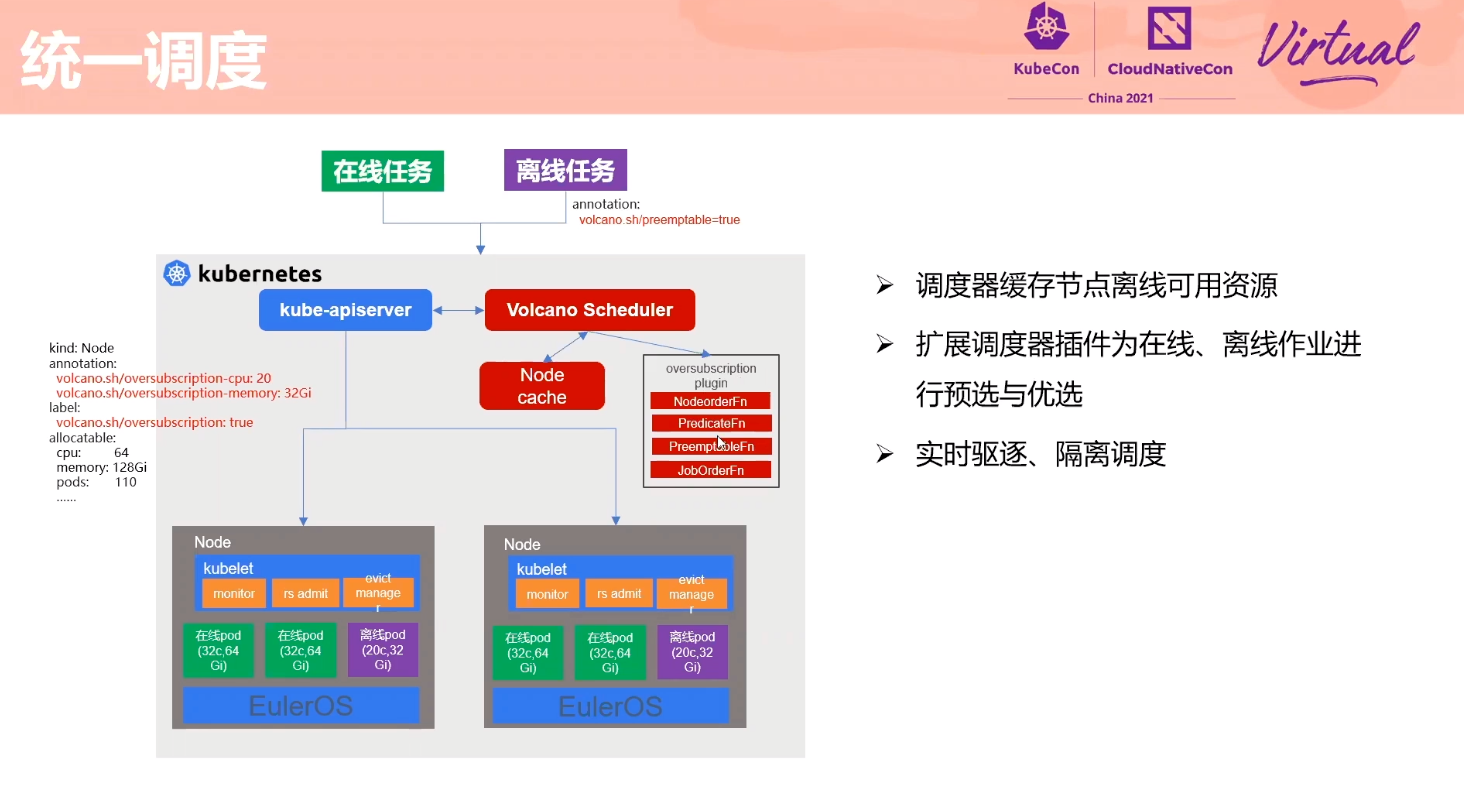
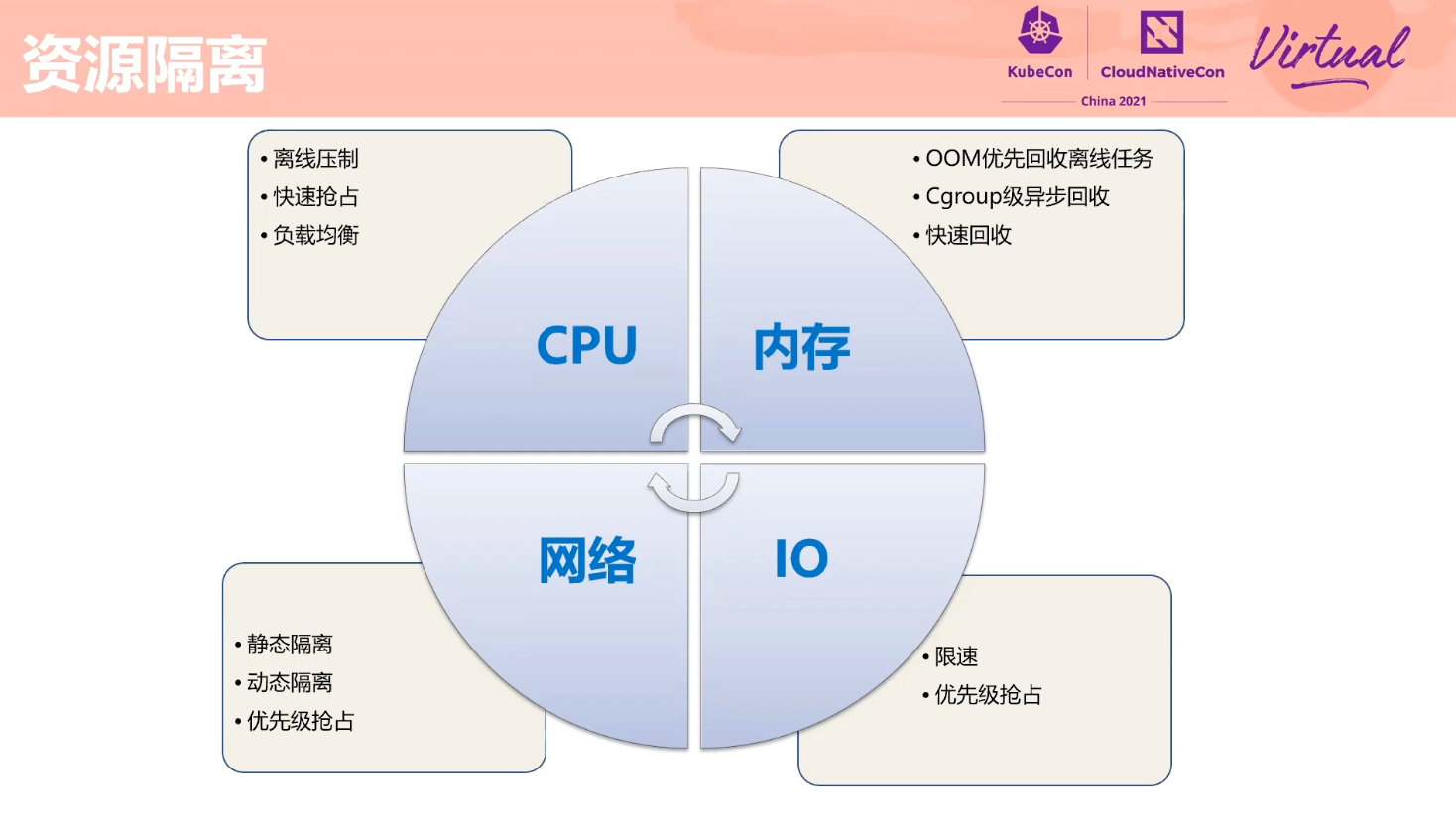
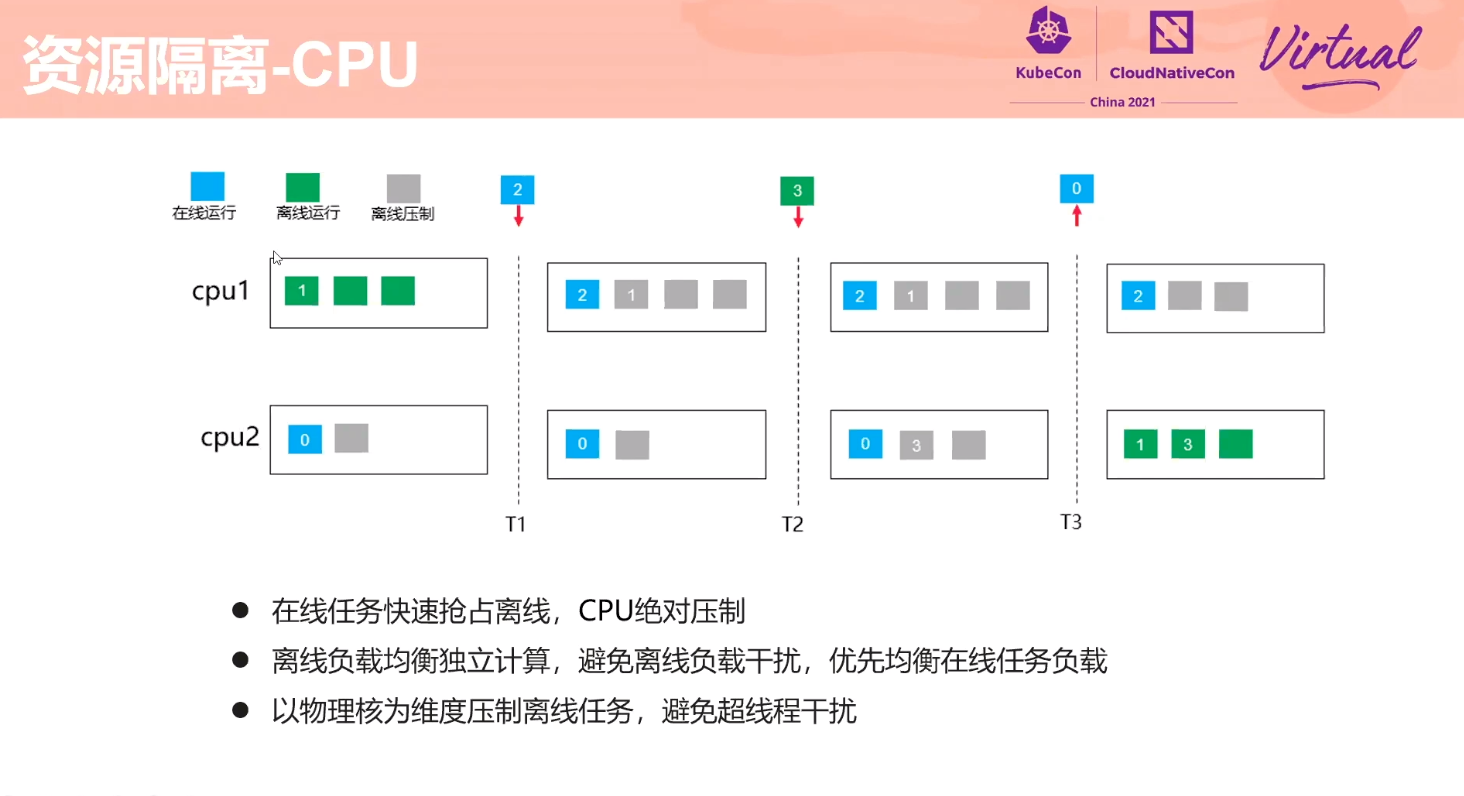

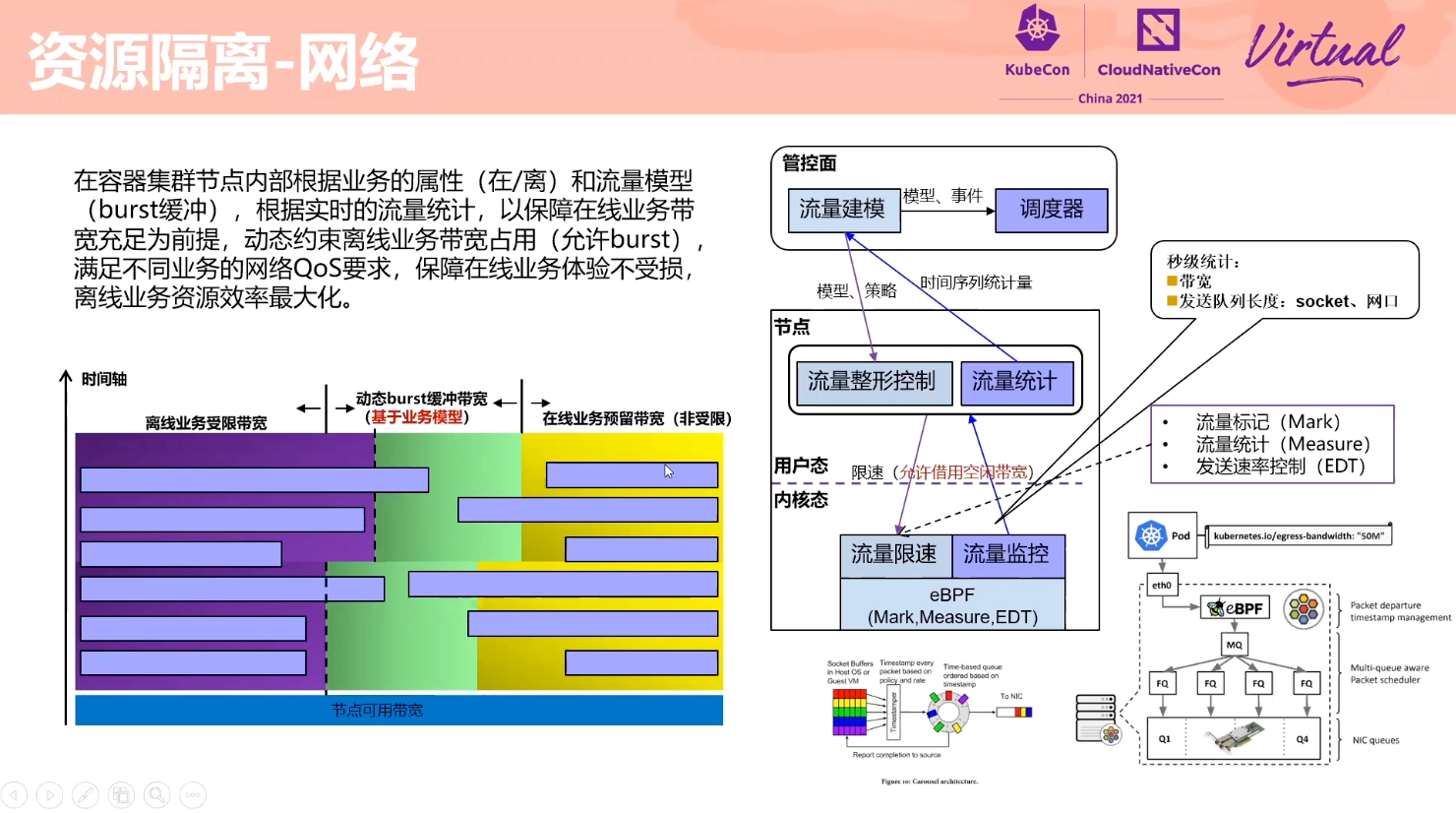
如何做干扰检测没有展开讲。
小总结
混部和 eBPF 相关的主题明显变多了。
云原生安全的主题也变多了。
边缘计算场景有了新的花样 WASM。
除了 Operator 之外,也有一些新的 K8s 开发的相关 Session,比如 Apiserver Aggregation。