看脚下一片黑暗 望头顶星光璀璨
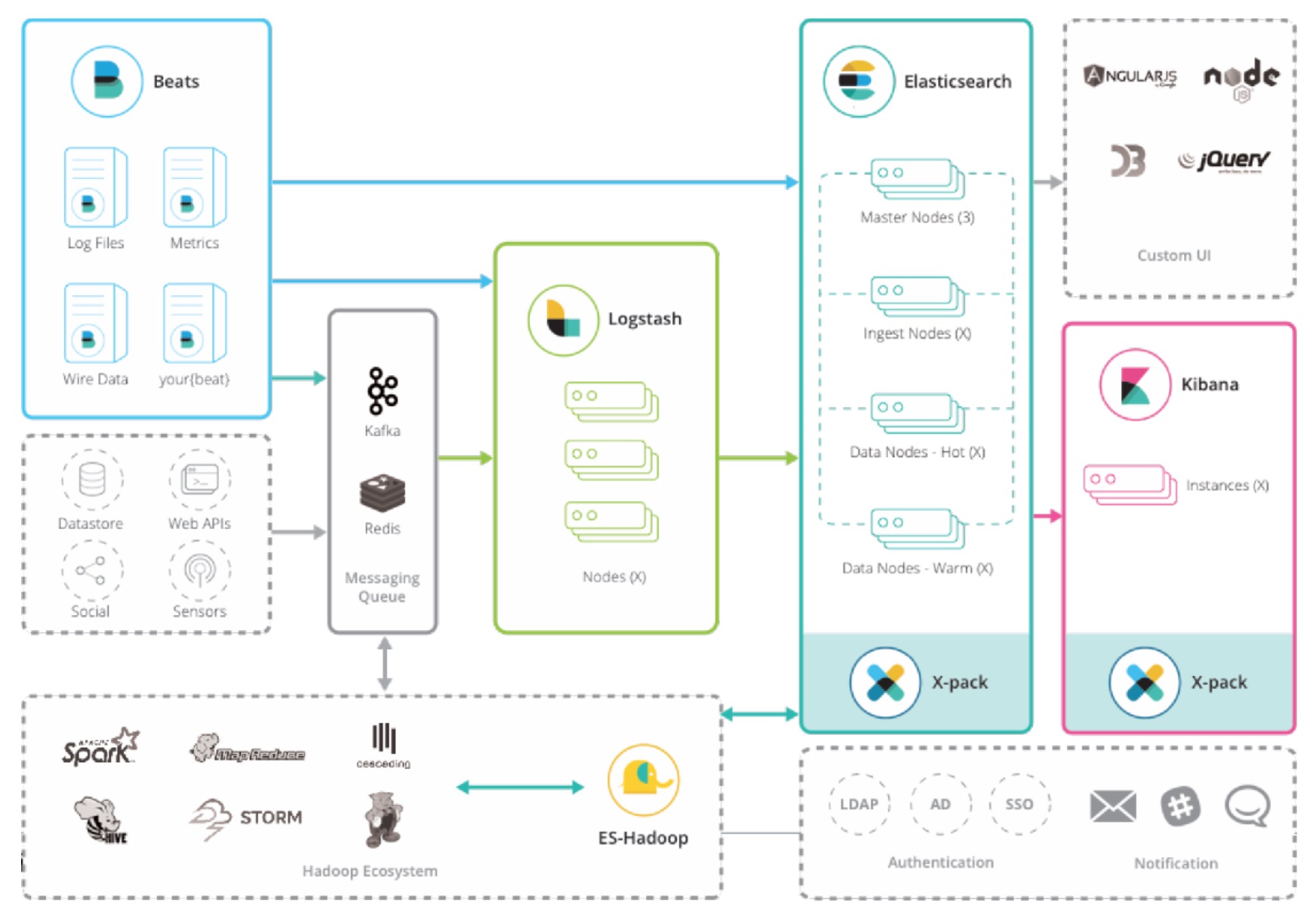
Elastic Stack 是由 Elastic 公司推出的一个技术栈,包括但不限于 beats、logstash、elasticsearch、kibana 等软件。
目前整体的架构 大致如下:
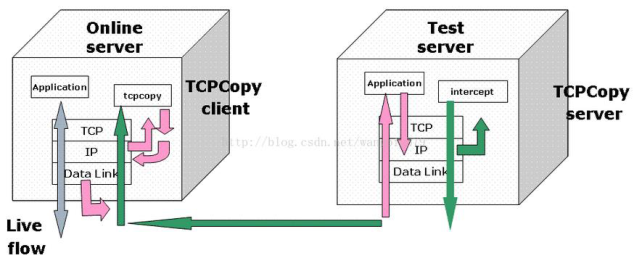
TCPCopy 默认从 IP 层抓包,从 IP 层发包,在测试服务器进行响应包的截获,并通过 intercept 程序返回响应包的必要信息给 TCPCopy。
在线上要引流的机器和测试机分别安装 TCPCopy,版本 tcpcopy-0.9.6.tar.gz
然后:
configure
make
make install