希望探究复杂系统如何应对异常时,对系统中的服务注入通信故障、超时、错误等,这是一个故障注入的典型场景。 希望探究更多其他的非故障类的场景,流量激增、资源竞争条件、拜占庭故障、非计划中的或非正常组合的消息处理等等。
和故障注入类似,故障测试方法通过对预先设想到的可以破坏系统的点进行测试,但是并没能去探究上述这类更广阔领域里的、不可预知的、但很可能发生的事情。
在测试中,要进行断言:即给定一个特定的条件,系统会输出一个特定的结果。 测试一般来说只会产生二元的结果,验证一个结果是真还是假,从而判定测试是否通过。 严格意义上来说,这个实践过程并不能发掘出系统未知的或尚不明确的认知,它仅仅是对已知的系统属性可能的取值进行测验。 而实验可以产生新的认知,而且通常还能开辟出一个更广袤的对复杂系统的认知空间。
故障注入则是对一个特定的条件、变量的验证方法。 混沌工程是发现新信息的实践过程。
一些混沌工程实验的输入样例:
- 模拟整个云服务区域或整个数据中心故障
- 在驱动程序中执行模拟 I/O 错误的程序
- 强制系统节点间的时间不同步
- 让某个 Elasticsearch 集群 CPU 超负荷
- 跨多实例删除部分 Kafka topic 来重现生产环境中发生过的问题
- 挑选一个时间段,和针对一部分流量,对其涉及的服务间调用注入一些特定的延时
- 方法级别的混乱,让方法随机抛出各种异常
- 在代码中插入一些指令可以允许在这些指令之前运行故障注入
混沌工程的前提条件是监控系统。 如果没有对系统行为的可见能力,就无法从实验中得出有效的结论。
软件工程师通常会对这三个方面进行优化:性能、可用性、容错能力。
原则
- 建立稳定状态的假设
- 多样化现实世界事件
- 在生产环境运行实验
- 持续自动化运行实验
- 最小化爆炸半径
如何描述稳定状态
期望通过一个模型,基于所期望的业务指标,来描述系统的稳定状态,不只是数值范围。
建立假设
每当进行混沌工程实验的时候,应该首先在心里对实验结果有一个假设。 没有一个预先的假设,就不清楚应该从数据里找什么,最终也难以得出有效结论。
思考一下当向系统注入不同类型的事件时,稳定状态行为会发生什么变化。
故障
- 硬件故障
- 网络延迟或隔离
- 上行或下行输入的大幅波动以及重试风暴
- 资源耗尽
- 状态转换异常
- 服务之间的不正常的或者预料之外的组合调用
- 下游依赖故障
- 功能缺陷
- 拜占庭故障
- 资源竞争条件
不需要穷举所有可能对系统造成改变的事件,只需要注入那些频繁发生且影响重大的事件,同时要足够理解会被影响的故障域。
注入的事件一定是认为系统能处理的。 同时,注入的事件应该是所有可能的真实世界的事件,而不仅仅是故障或延迟。
让这些薄弱环节曝光出来而不会意外造成更大规模的故障。
确定故障的边界,逐渐加大故障范围。
爆炸半径
某一部署单元、某一机房,某一集群,甚至精确到实例级别乃至流量级别。
流程
- 选定假设
- 设定实验的范围
- 识别出要监控的指标
- 执行实验
- 分析实验结果
- 扩大实验范围
- 自动化实验
阶段
- 实验结果只反映系统指标,而不是业务指标;只对实验对象注入一些简单事件,如"关闭节点"
- 用复制的生产流量来运行实验;实验结果反映聚合的业务指标;对实验对象注入较高级的事件,如网络延迟
- 实验框架和持续发布工具集成;持续收集实验结果;在实验组和控制组之间比较业务指标差异;对实验组引入如服务级别的影响和组合式的故障事件
对比
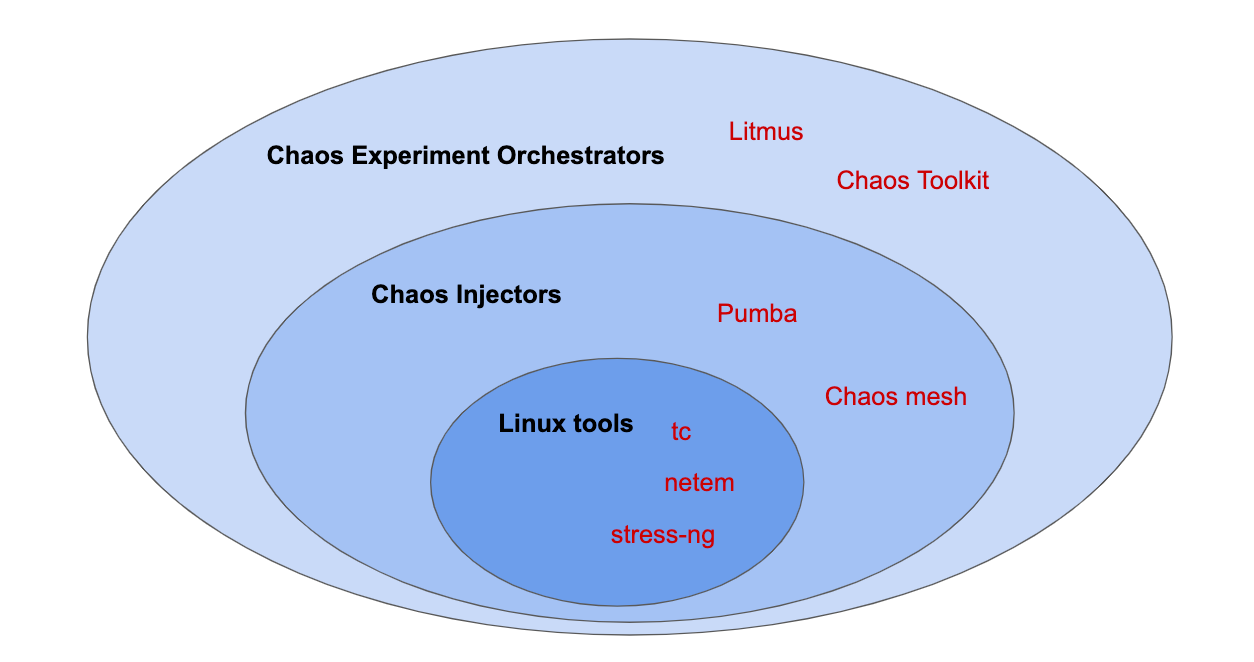
Chaos Toolkit/Chaos Toolkit Extensions for Kubernetes
https://docs.chaostoolkit.org/drivers/kubernetes/

可扩展性,旨在成为创建自定义混沌工具和实验的框架。
“开放混沌计划”,旨在通过开放 API 规范,使混沌实验标准化。
Litmus
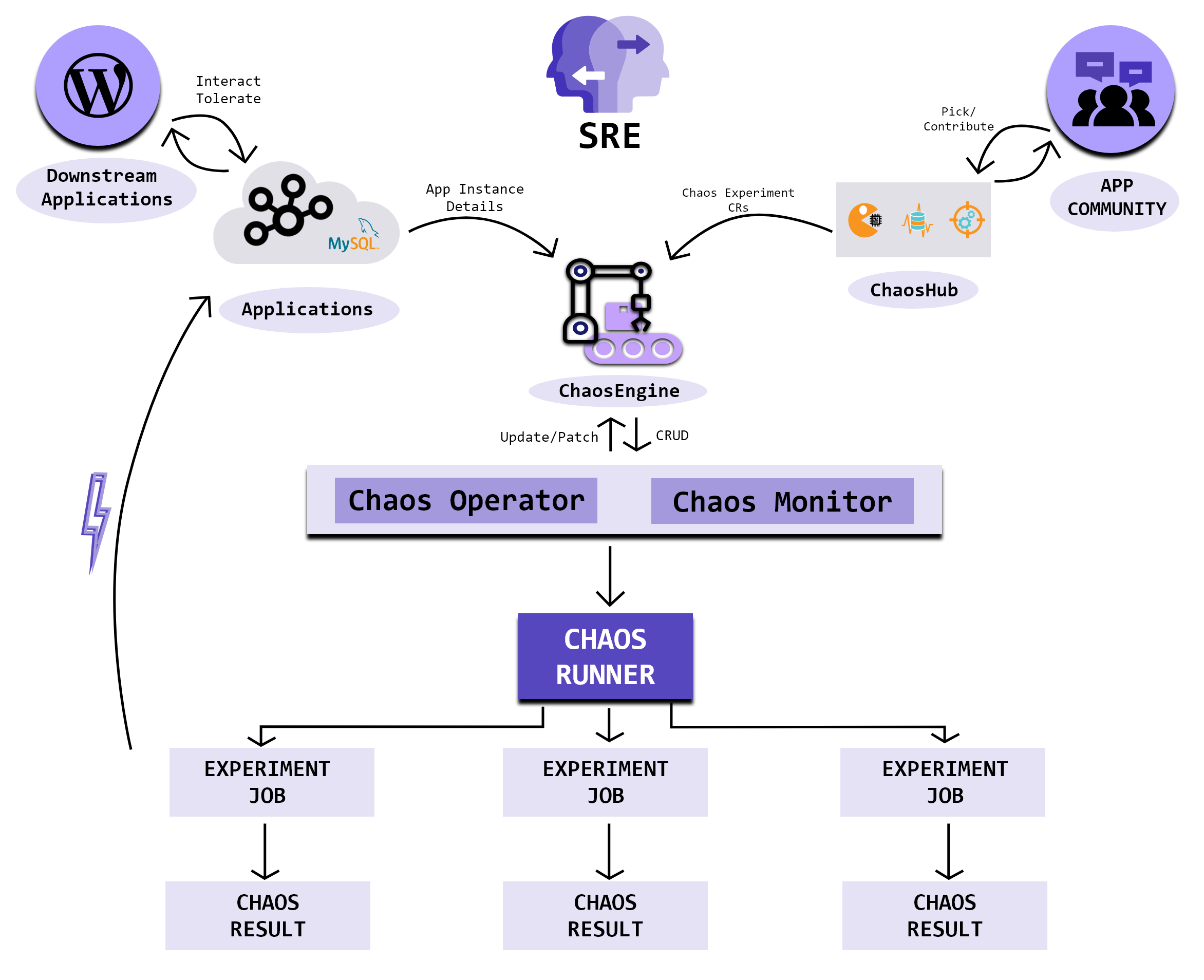
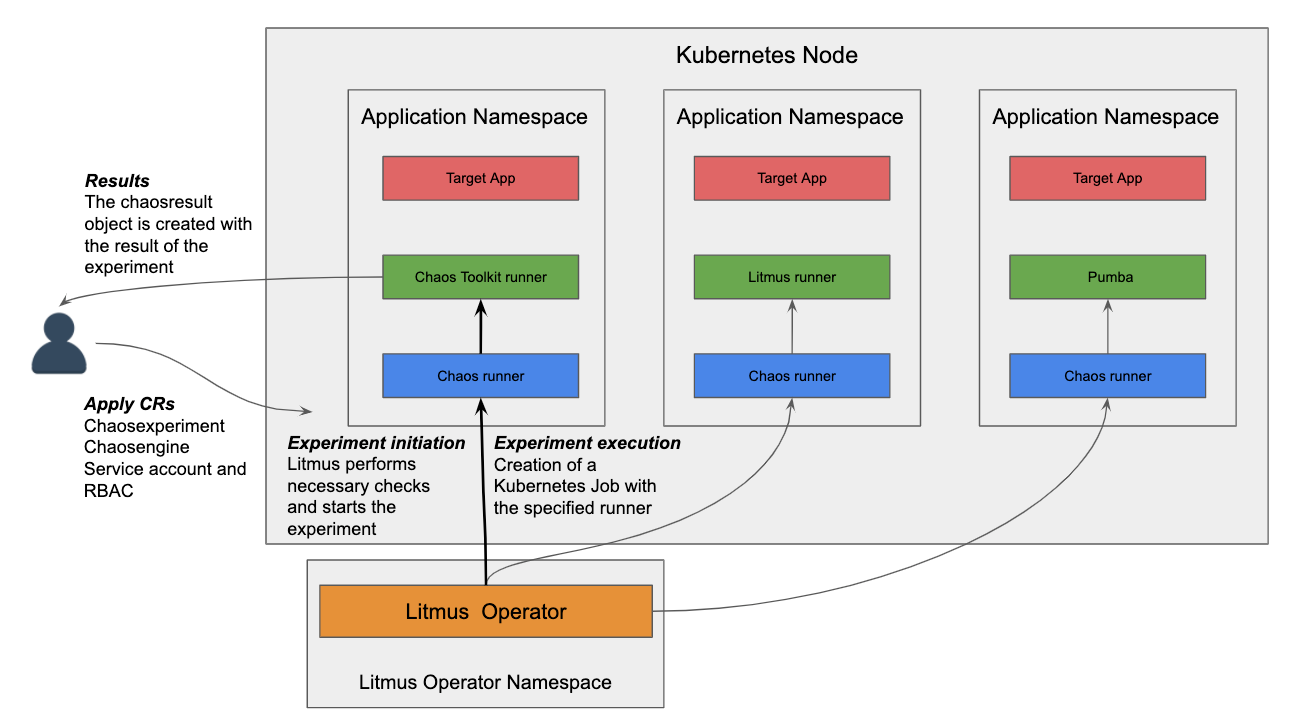
- ChaosEngine 关联一个 Kubernetes 的应用或是 Kubernetes 节点。Litmus 的 Chaos-Operator 会 watch 这个对象并触发 ChaosExperiment。
- ChaosExperiment 包含了一组混沌事件的配置。当 ChaoseEngine 触发混沌事件的时候,Chaos-Operator 就会创建 ChaoseExpeiment。
- ChaosResult 混沌事件的结果。Chaos-exporter 读取结果并暴露 metrics 写到 Prometheus 中。
chaos-mesh
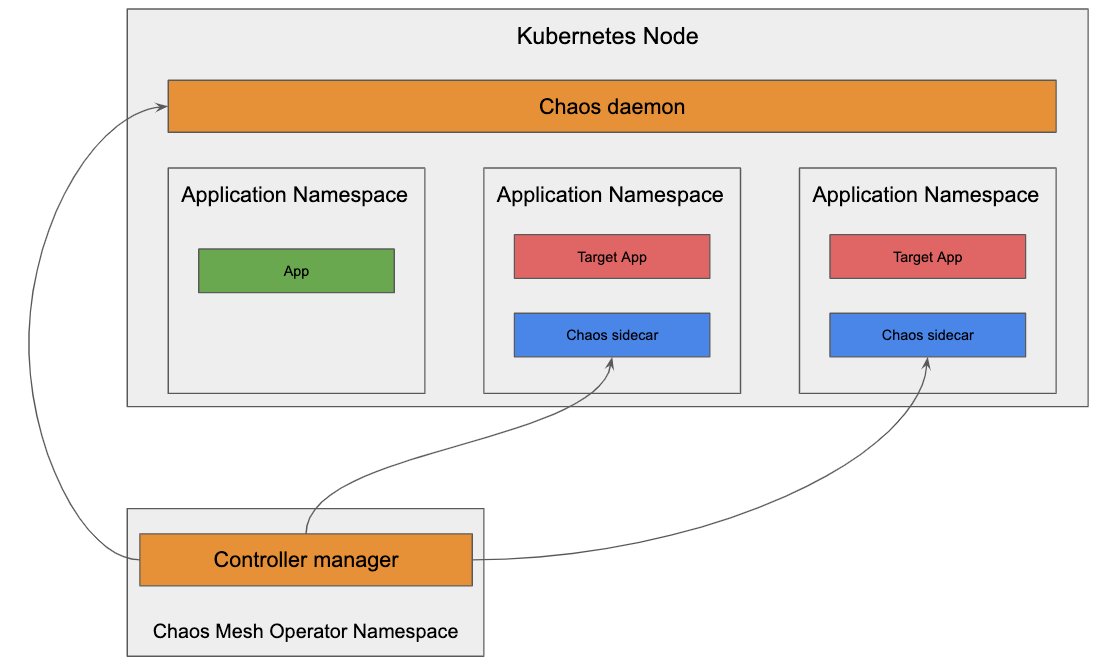

https://grafana.com/grafana/plugins/yeya24-chaosmesh-datasource
kube-monkey
每天早上,都会生成一个全天应该执行的 Pod 的计划。
允许指定每个 Pod 的故障之间的平均时间。
允许单个应用程序以自己独特的方式选择加入。 应用程序 a 可以要求每周一天杀死一个 Pod。 应用程序 b 可以要求杀死 50% 的 Pod。
chaoskube
每隔 10 分钟,随机杀 Pod。
kubethanos
会随机杀死一半的 Pod。